Fork/Join框架原理解析
1、概述
Fork/Join Pool采用优良的设计、代码实现和硬件原子操作机制等多种思路保证其执行性能。其中包括(但不限于):计算资源共享、高性能队列、避免伪共享、工作窃取机制等。本文(以及后续文章)试图和读者一起分析JDK1.8中Fork/Join Pool的源代码实现,去理解Fork/Join Pool是怎样工作的。当然这里要说明一下,起初本人在决定阅读Fork/Join归并计算相关类的源代码时(ForkJoinPool、WorkQueue、ForkJoinTask、RecursiveTask、ForkJoinWorkerThread等),并不觉得这部分代码比起LinkedList这样的类来说有多少难度, 但其中大量使用位运算和位运算技巧,有大量Unsafe原子操作。博主能力有限,确实不能在短时间内将所有代码一一详细解读,所以也希望各位读者能帮助笔者一同完善。
2、要点
2-1. Fork/Join Pool实例化
实际上在之前文章中给出的Fork/Join Pool使用实例中,我们使用的new ForkJoinPool()或者new ForkJoinPool(N)这些方式来进行操作,这并不是ForkJoinPool作者Doug Lea推荐的使用方式。在ForkJoinPool主类的注释说明中,有这样一句话:
A static commonPool() is available and appropriate for most applications. The common pool is used by any ForkJoinTask that is not explicitly submitted to a specified pool.
Using the common pool normally reduces resource usage (its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use).
以上描述大致的中文解释是:ForkJoinPools类有一个静态方法commonPool(),这个静态方法所获得的ForkJoinPools实例是由整个应用进程共享的,并且它适合绝大多数的应用系统场景。使用commonPool通常可以帮助应用程序中多种需要进行归并计算的任务共享计算资源,从而使后者发挥最大作用(ForkJoinPools中的工作线程在闲置时会被缓慢回收,并在随后需要使用时被恢复),而这种获取ForkJoinPools实例的方式,才是Doug Lea推荐的使用方式。代码如下:
......
ForkJoinPool commonPool = ForkJoinPool.commonPool();
......通过阅读ForkJoinPool的代码我们可以发现ForkJoinPool中如何完成commonPool的初始化:、
static {
......
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction() {
public ForkJoinPool run() { return makeCommonPool(); }});
// report 1 even if threads disabled
int par = common.config & SMASK;
commonParallelism = par > 0 ? par : 1;
......
}
......
// 这是主要的创建过程
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
// 可以通过在java程序启动时,指定这些参数的方式
// 来完成并行等级,线程工厂,异常处理类的指定工作
try {
// 首先确认技术人员在启动应用程序时,是否指定了这些参数,来控制CommonPool的创建过程
// ignore exceptions in accessing/parsing properties
String pp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp =
System.getProperty("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
// 没有在启动时指定以上参数也没关系,java会启动默认参数
if (factory == null) {
// 如果当前没有启动SecurityManager,安全策略管理器
// 这时使用defaultForkJoinWorkerThreadFactory这个工厂对象
// 它是java.util.concurrent.ForkJoinPool.DefaultForkJoinWorkerThreadFactory这个类的实例
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else
// use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
// 如果并行等级小于0,并且当前应用程序可用CPU内核数为1
// 那么设定parallelism并行等级为1
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
// 最后使用这个构造函数初始化commonPool
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE, "ForkJoinPool.commonPool-worker-");
} 以上代码片段中的中文注释是笔者加的,而英文注释是源代码自带的。对commonPool的初始化过程有Java security安全策略框架参与,doPrivileged方法为排除Java security安全策略框架的权限检查,而SecurityManager是Java security安全策略框架的管理器。一般情况下Java应用程序不会自动启动安全管理器,不过读者可以在Java应用程序启动时,使用-Djava.security.manager参数启动SecurityManager,或者在你的代码中通过System.setSecurityManager()方法显式设定一个。
当然,除了使用ForkJoinPool提供的commpool对象外,读者也可以直接通过ForkJoinPool提供的三种构造函数直接完成实例化,这三个可以同的构造分别是(以上构造函数的使用意义已经在之前的文章中讨论过了,这里就不再赘述了):
public ForkJoinPool() {
......
}
public ForkJoinPool(int parallelism) {
......
}
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler, boolean asyncMode) {
......
}2-2. 工作线程和工作队列
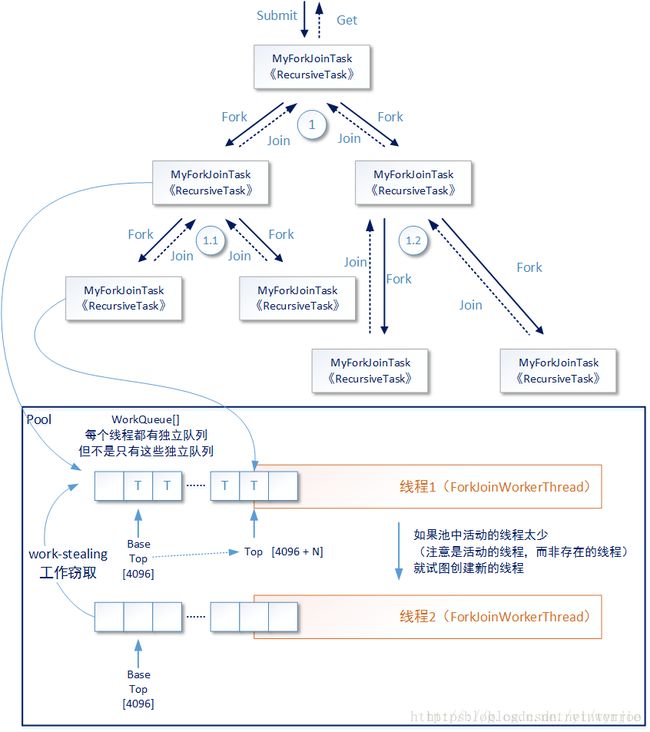
在本小节中我们主要讨论ForkJoinPool中处理ForkJoinTask任务及其子任务的情况,而ForkJoinPool处理Runnable或者Callable类型任务的情况将在后文讨论。ForkJoinPool中主要的工作线程,采用ForkJoinWorkerThread定义,其中有两个主要属性pool和workQueue:
public class ForkJoinWorkerThread extends Thread {
......
// the pool this thread works in
final ForkJoinPool pool;
// work-stealing mechanics
final ForkJoinPool.WorkQueue workQueue;
......
}pool属性表示这个进行归并计算的线程所属的ForkJoinPool实例,workQueue属性是java.util.concurrent.ForkJoinPool.WorkQueue这个类的实例,它表示这个线程所使用的子任务待执行队列,而且可以被其它工作线程偷取任务。后者的内部是一个数组结构,并使用一些关键属性记录这个队列的实时状态,更具体的来说这个WorkQueue**是一个双端队列**。
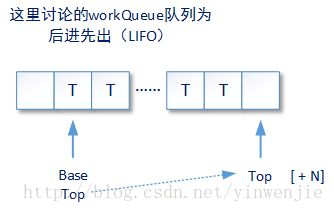
Java中还有一组类似的双端队列顶层接口java.util.Deque、java.util.concurrent.BlockingDeque,但应该是出于实现细节的考虑,WorkQueue这个双端队列并没有实现这些接口。所谓双端队列,就是说队列中的元素(ForkJoinTask任务及其子任务)可以从一端入队出队,还可以从另一端入队出队。这个双端队列将用于支持ForkJoinPool的两种异步模型(asyncMode):后进先出(LIFO_QUEUE)和先进先出(FIFO_QUEUE)。以下代码片段示例了WorkQueue类中定义的一些重要属性:
......
static final class WorkQueue {
......
// 队列状态
volatile int qlock; // 1: locked, < 0: terminate; else 0
// 下一个出队元素的索引位(主要是为线程窃取准备的索引位置)
volatile int base; // index of next slot for poll
// 为下一个入队元素准备的索引位
int top; // index of next slot for push
// 队列中使用数组存储元素
ForkJoinTask[] array; // the elements (initially unallocated)
// 队列所属的ForkJoinPool(可能为空)
// 注意,一个ForkJoinPool中会有多个执行线程,还会有比执行线程更多的(或一样多的)队列
final ForkJoinPool pool; // the containing pool (may be null)
// 这个队列所属的归并计算工作线程。注意,工作队列也可能不属于任何工作线程
final ForkJoinWorkerThread owner; // owning thread or null if shared
// 记录当前正在进行join等待的其它任务
volatile ForkJoinTask currentJoin; // task being joined in awaitJoin
// 当前正在偷取的任务
volatile ForkJoinTask currentSteal; // mainly used by helpStealer
......
}
......当ForkJoinWorkerThread需要向双端队列中放入一个新的待执行子任务时,会调用WorkQueue中的push方法。我们来看看这个方法的主要执行过程(请注意,源代码来自JDK1.8,它和JDK1.7中的实现有显著不同):
/**
* Pushes a task. Call only by owner in unshared queues. (The
* shared-queue version is embedded in method externalPush.)
*/
final void push(ForkJoinTask task) {
ForkJoinTask[] a; ForkJoinPool p;
int b = base, s = top, n;
// 请注意,在执行task.fork时,触发push情况下,array不会为null
// 因为在这之前workqueue中的array已经完成了初始化(在工作线程初始化时就完成了)
if ((a = array) != null) {
int m = a.length - 1; // fenced write for task visibility
// U常量是java底层的sun.misc.Unsafe操作类
// 这个类提供硬件级别的原子操作
// putOrderedObject方法在指定的对象a中,指定的内存偏移量的位置,赋予一个新的元素
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
// putOrderedInt方法对当前指定的对象中的指定字段,进行赋值操作
// 这里的代码意义是将workQueue对象本身中的top标示的位置 + 1,
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
// Tries to create or activate a worker if too few are active.
// signalWork方法的意义在于,在当前活动的工作线程过少的情况下,创建新的工作线程
p.signalWork(p.workQueues, this);
}
// 如果array的剩余空间不够了,则进行增加
else if (n >= m)
growArray();
}
}sun.misc.Unsafe操作类直接基于操作系统控制层在硬件层面上进行原子操作,它是ForkJoinPool高效性能的一大保证,类似的编程思路还体现在java.util.concurrent包中相当规模的类功能实现中。实际上sun.misc.Unsafe操作类在Java中有着举足轻重的地位,本专题的后续文章中会详细介绍sun.misc.Unsafe操作类,以及基于这个类实现的Java乐观锁机制。当ForkJoinWorkerThread需要从双端队列中取出下一个待执行子任务,就会根据设定的asyncMode调用双端队列的不同方法,代码概要如下所示:
// 试图从指定的队列中取出下一个待执行任务
final ForkJoinTask nextTaskFor(WorkQueue w) {
for (ForkJoinTask t;;) {
WorkQueue q; int b;
// 该方法试图从“w”这个队列获取下一个待处理子任务
if ((t = w.nextLocalTask()) != null)
return t;
// 如果没有获取到,则使用findNonEmptyStealQueue方法
// 随机得到一个元素非空,并且可以进行任务窃取的存在于ForkJoinPool中的其它队列
// 这个队列被记为“q”
if ((q = findNonEmptyStealQueue()) == null)
return null;
// 试图从“q”这个队列base位处取出待执行任务
if ((b = q.base) - q.top < 0 && (t = q.pollAt(b)) != null)
return t;
}
}
......
/**
* Takes next task, if one exists, in order specified by mode.
*/
final ForkJoinTask nextLocalTask() {
// 如果asyncMode设定为后进先出(LIFO)
// 则使用pop()从双端队列的前端取出任务
// 否则就是先进先出模式(FIFO),使用poll()从双端队列的后端取出任务
return (config & FIFO_QUEUE) == 0 ? pop() : poll();
}
......2-3. ForkJoinPool中的队列
那么ForkJoinPool是怎样创建队列的呢?请看如下两段源代码片段:
/**
* Tries to add the given task to a submission queue at
* submitter's current queue. Only the (vastly) most common path
* is directly handled in this method, while screening for need
* for externalSubmit.
*/
// ForkJoinPool类中的方法
// 该方法试图将一个任务提交到一个submission queue中,随机提交
final void externalPush(ForkJoinTask task) {
WorkQueue[] ws; WorkQueue q; int m;
// 取得一个随机探查数,可能为0也可能为其它数
int r = ThreadLocalRandom.getProbe();
// 获取当前ForkJoinPool的运行状态
int rs = runState;
// 最关键的操作在这里,详见后文说明
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask[] a; int am, n, s;
if ((a = q.array) != null && (am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;
// 以下三个原子操作首先是将task放入队列
U.putOrderedObject(a, j, task);
// 然后将“q”这个submission queue的top标记+1
U.putOrderedInt(q, QTOP, s + 1);
// 最后解除这个submission queue的锁定状态
U.putIntVolatile(q, QLOCK, 0);
// 如果条件成立,说明这时处于active的工作线程可能还不够
// 所以调用signalWork方法
if (n <= 1)
signalWork(ws, q);
return;
}
// 这里试图接除对这个submission queue的锁定状态
// 为什么会有两次接触呢?因为在之前代码中给队列加锁后,
// 可能队列的现有空间并不满足添加新的task的条件
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
externalSubmit(task);
}
......
/**
* Full version of externalPush, handling uncommon cases, as well
* as performing secondary initialization upon the first
* submission of the first task to the pool. It also detects
* first submission by an external thread and creates a new shared
* queue if the one at index if empty or contended.
*/
// 以下是externalSubmit方法的部分代码,用于初始化ForkJoinPool中的队列
private void externalSubmit(ForkJoinTask task) {
......
// initialize
// 如果条件成立,就说明当前ForkJoinPool类中,还没有任何队列,所以要进行队列初始化
else if ((rs & STARTED) == 0 || ((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
// 通过原子操作,完成“任务窃取次数”这个计数器的初始化
U.compareAndSwapObject(this, STEALCOUNTER, null, new AtomicLong());
// create workQueues array with size a power of two
// 这段代码也非常有趣,详见后文的分析。
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
workQueues = new WorkQueue[n];
ns = STARTED;
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
}
......
}externalPush方法中的“q = ws[m & r & SQMASK]”代码非常重要。我们大致来分析一下作者的意图,首先m是ForkJoinPool中的WorkQueue数组长度减1,例如当前WorkQueue数组大小为16,那么m的值就为15;r是一个线程独立的随机数生成器,关于java.util.concurrent.ThreadLocalRandom类的功能和使用方式可参见其它资料;而SQMASK是一个常量,值为126 (0x7e)。以下是一种可能的计算过程和计算结果:
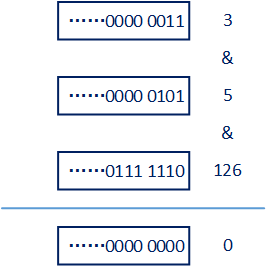
实际上任何数和126进行“与”运算,其结果只可能是0或者偶数,即0 、 2 、 4 、 6 、 8。也就是说以上代码中从名为“ws”的WorkQueue数组中,取出的元素只可能是第0个或者第偶数个队列。
我们再来看看以上代码给出的externalSubmit方法中,进行WorkQueue数组初始化的代码。当外部调用这通过submit、execute、invoke方法向ForkJoinPool提交一个计算任务时,会运行这段代码为ForkJoinPool创建多个WorkQueue并形成数组。其中以下代码片段用于确定这个即将创建的WorkQueue数组的大小
......
// SMASK是一个常量
static final int SMASK = 0xffff;
......
// 这是config的来源
// mode是ForkJoinPool构造函数中设定的asyncMode,如果为LIFO,则mode为0,否则为65536
// parallelism 为技术人员设置的(或者程序自行设定的)并发等级
this.config = (parallelism & SMASK) | mode;
......
// ensure at least 2 slots
int p = config & SMASK;
// n这个变量就是要计算的WorkQueue数组的大小
int n = (p > 1) ? p - 1 : 1;
......
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
......从以上整理的代码可以看出,最后确认ForkJoinPool中WorkQueue数组初始化大小的因素是名叫config的变量,而config变量又与构造ForkJoinPool时所传入的并发等级(parallelism)、异步模式(asyncMode)有关。在我们选择LIFO模式时,计算结果如下表所示(下表中的结果建立在mode = 0的前提下):
| parallelism | n | parallelism | n |
|---|---|---|---|
| 1 | 4 | 2 | 4 |
| 3 | 8 | 4 | 8 |
| 5 | 16 | 6 | 16 |
| 7 | 16 | 8 | 16 |
| 9 | 32 | 10 | 32 |
| … | 32 | 14 | 32 |
| … | 32 | 16 | 32 |
| 17 | 64 | … | … |
是的,计算结果“n”按照两倍规模进行扩展,并且在初始化时保证和并发级别设定的数量(parallelism)至少两倍的关系。这是为什么呢?这是因为ForkJoinPool中的这些WorkQueue和工作线程ForkJoinWorkerThread并不是一对一的关系,而是随时都有多余ForkJoinWorkerThread数量的WorkQueue元素。而这个ForkJoinPool中的WorkQueue数组中,索引位为非奇数的工作队列用于存储从外部提交到ForkJoinPool中的任务,也就是所谓的submissions queue;索引位为奇数的工作队列用于存储归并计算过程中等待处理的子任务,也就是task queue。
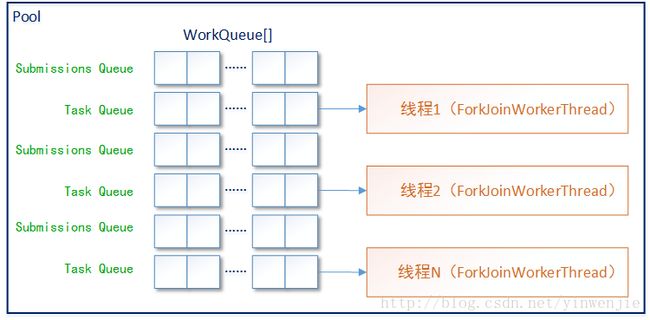
这样我们也就可以明白,ForkJoinPool中重写的toString()方法,是如何取得submissions、tasks、steals和running监控数据,请看以下toString()方法的源码片段:
public String toString() {
......
WorkQueue[] ws; WorkQueue w;
if ((ws = workQueues) != null) {
// 循环着,依次遍历当前ForkJoinPool中WorkQueue数组的每一个元素
for (int i = 0; i < ws.length; ++i) {
if ((w = ws[i]) != null) {
// 获取当前WorkQueue中元素的数量
// (WorkQueue也是使用数组方式存储这些元素)
int size = w.queueSize();
// 如果当前数组元素的索引位为非奇数
// 说明是submissions queue,这时submissions计数器发生累加
if ((i & 1) == 0)
qs += size;
else {
// 否则说明是task queue,这时tasks计数器增加
qt += size;
// 通过nsteals属性,获得这个task queue中任务被“窃取”的次数
st += w.nsteals;
// 如果条件成立,就说明当前task queue所对应的工作线程
// 没有被任何方式阻塞,所以running计数器增加
if (w.isApparentlyUnblocked())
++rc;
}
}
}
}
......
return super.toString() +
......
", running = " + rc +
", steals = " + st +
", tasks = " + qt +
", submissions = " + qs +
"]";
}注释比较详细,而且比起workqueue的入队出队逻辑和任务窃取逻辑,以上代码就是非常简单了。所以这里就不再赘述代码过程了。注意,以上代码分析基于JDK 1.8的源码分析,而与JDK1.7中ForkJoinPool的实现有较大差异。
2-5. ForkJoinPool工作监控
ForkJoinPool重写了toString()方法,以便技术人员在代码调试或者其它需要临时监控ForkJoinPool运行情况的场景下,轻松获取ForkJoinPool中的主要工作状态。以下运行效果展示了ForkJoinPool类的toString()方法打印的情况:
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 7, running = 7, steals = 14, tasks = 224, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 7, running = 7, steals = 14, tasks = 213, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 7, running = 7, steals = 14, tasks = 164, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 9, running = 9, steals = 22, tasks = 281, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 8, running = 8, steals = 22, tasks = 212, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 6, size = 9, active = 7, running = 7, steals = 22, tasks = 192, submissions = 0]
**********************- parallelism:当前ForkJoinPool设定的并行级别
- size:当前ForkJoinPool线程池内部的所有线程数量,这些线程可能处于阻塞状态(使用join方法引起的阻塞或者任务中其它会引起线程阻塞方法引起的阻塞),可能处于运行状态。
- active:当前线程池内部,正在进行compute计算的线程(这些线程不代表没有被阻塞)。
- running:当前线程池内部,正在进行compute计算并且没有被任何阻塞线程阻塞机制所影响的线程数量
- steals:当前ForkJoinPool线程池内部各个work queue间发生的“工作窃取”操作的总次数。
- tasks:当前ForkJoinPool线程池内部各个work queue中等待处理的子任务总数量。
- submissions:通过submit方式或者其它方式提交到ForkJoinPool中,准备进行归并计算的但是ForkJoinPool还没有开始处理的任务(ForkJoinTask任务或者其子任务)数量。
这里要重点说明一下active和running两个返回信息的关系和区别:通常情况下active数量和running数量是一致的,因为正在运行归并计算子任务的线程,肯定是处于运行状态,否则它怎么进行计算呢?但是如果技术人员在进行归并计算的时候,主动阻塞了线程就另当别论了。例如技术人员在compute()方法中使用wait方法主动阻塞线程的情况:
......
protected int[] compute() {
......
// 让任务随机等待
// 因为要进行1亿次计算,大约设定百万分之1的概率强制阻塞
if(ThreadLocalRandom.current().nextFloat() < 0.000001f) {
try {
synchronized (this) {
this.wait(1000);
}
} catch (InterruptedException e) {
e.printStackTrace(System.out);
}
}
......
}
......以上的代码在对1亿条数据数进行排序时,有百万分之一的概率阻塞排序子任务。在子任务进行归并计算时,可强制让计算线程阻塞1秒。这时我们再执行这个应用程序并且进行监控,那么以下可能就是我们会看到的监控信息了:
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 5, running = 3, steals = 21, tasks = 154, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 5, running = 0, steals = 21, tasks = 142, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 5, running = 2, steals = 25, tasks = 131, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 7, running = 2, steals = 28, tasks = 212, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 7, running = 3, steals = 28, tasks = 216, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 6, running = 0, steals = 28, tasks = 148, submissions = 0]
**********************
@2503dbd3[Running, parallelism = 4, size = 7, active = 5, running = 1, steals = 28, tasks = 142, submissions = 0]
**********************因为是随机概率,所以读者自行运行的监控效果和这里给出的监控效果是不同的。