网络优化-- (INPLACE-ABN)In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
INPLACE-ABN ABN
In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
相关:CityScapes 语义分割项目第一(180313统计)
原文地址:In-Place-abn
先进的深度网络中,大多数重复使用BN+激活层组合。而现有的深度学习框架对此的内存优化策略不佳。论文提出了INPLACE-ABN层代替BN+激活层,相比于标准的BN+激活层节省了50%的内存。
代码:
- 官方-pytorch
Abstract
论文提出了一种新颖的有效的计算方式,能大幅度减少现代深度神经网络训练存储足迹。称之为In-Place Activated Batch Normalization(INPLACE-ABN)。具体来说,INPLACE-ABN是将常用深度网络中常见的BN+Activation组合替换为一个合并层,通过存储少量计算结果(丢弃部分中间结果,在反向传播时倒置计算恢复需要的参量),节省了50%的存储空间,却只增加少许计算量。
论文证明了频繁的使用INPLACE-ABN和现在广泛使用的checkpointing方案效率一样高。新的方案在ImageNet-1K分类实验获得state-of-the-art水准。在高内存需求的语义分割任务上,如COCO-Stuff, Cityscapes and Mapillary Vistas,同样获得了新的state-of-the-art结果.
Introduction
现如今高性能的计算机视觉系统通常以深度网络为主干,生成目标丰富特征表示。例如在MS-COCO竞赛上,高名次的模型大多数是基于ResNet/ResNeXt模型。 深度模型与给定的计算资源限制(GPU显存等)紧密相关,以语义分割为例,这是一个对显存需求大的任务,现存的方案训练时,要在单个batch上裁剪的数量和裁剪的空间分辨率之间做权衡。
实际情况是,大多数基于深度网络主干的系统在单个GPU上设置的crop不超过1,部分原因是因为在一些深度网络中内存管理不当导致的。本论文注重于提高模型在训练期间的内存管理效率,从而提升模型在复杂视觉任务上的表现。
论文引入了一个新颖的统一的层INPLACE-ABN, 用于替换batch normalization(BN) + nonlinear activation layers (ACT),可直接集成到现有的先进网络中(例如ResNet、DenseNet等)。INPLACE-ABN是将BN层和激活层融合,使用少量的存储空间。如下图所示:

在反向传播过程中,我们能够从存储空间取得正向传播时存储的值,通过翻转正向传播计算过程得到需要的参数,这样在节省存储空间的同时能够高效的恢复所需要的参数。
论文的方法相比于标准的BN+ACT方案,在理论上减少了50%内存使用,在实际的语义分割任务实验上数据吞吐量增加了75%左右。INPLCAE-ABN方案获得了显著的内存增益,并且没有引入明显的计算开销,运行时间只增加了0.8-2%。
此外,论文回顾了先广泛使用的checkpointing内存管理策略,这需要很高的计算复杂度,论文针对性的提出了一个优化方案,能够降低在反向传播过程中所需的重计算量。相对于checkpointing方案来说,论文提出的INPLACE-ABN方案计算可节省内存空间并相对的使用较少的计算时间。并且INPLACE-ABN能够做成一个标准的插件层,容易集成到现有的先进深度学习模型中。
实验结果证明INPLACE-ABN方案在ImageNet-1K的分类任务上,使用各个模型表现与现存的标准实现性能类似。在CityScapes,COCO-Stuff等语义分割任务显著提高了性能。
论文的主要贡献在于:
- 引入了新颖的、独立的INPLACE-ABN层,替换BN+ACT组合,实现联合近似计算,减少训练深度模型时的内存需求
- 受到INPLACE-ABN层启发,不改变BN层的条件下针对性的改进了广泛使用的checkpointing内存管理策略,实现更有效的计算
- 论文做了大量实验:
- 在ImageNet-1K分类任务上,展现了与多个先进模型相似的性能
- 在COCO-Stuff, Cityscapes and Mapillary Vistas语义分割任务上,得益于额外的可用内存收益,获得了更好的性能
Related Work
现有的深度学习框架中考虑内存优化管理问题通常是在不同层次上解决。高效的深度学习框架如TensorFlow、MXNet或PyTorch遵循不同的内存分配策略。其中包括广泛使用的checkpointing策略,它通过使用额外的内存用于存储前向传播计算结果,从而在反向传播时恢复出来,用于计算所需的参数。有一些工作描述了如何在子图的checkpointing之间递归应用这样的变体,也有工作使用动态编程进一步优化,在固定的存储限制下,决定存储策略让重计算的计算消耗最小化。
几乎所有的深度网络架构都是基于NVIDIA硬件开发的,因为NVIDIA提供了low-level的计算功能库CUDA和cuDNN,这提供了使用GPU加速的基本计算功能。另一个研究路线是减少CNN训练期间精度(存储精度,个人理解类似于float64->float32),从而减少内存使用。
此外有的工作改进了ResNet使其包含可逆残差模块(reversible blocks),可逆块可在反向传播时重组,因此不需要存储正向传播时的值,这可以节省内存。但是这样计算量增加了2倍。首先,在反向传播时每个残差块要重新计算,这和checkpointing消耗类似;其次,模型设计限制只能使用某些blocks,可逆残差模块不能生成信息应丢弃的bottleneck.
In-Place Acticated Batch Normalization
Batch Normalization ReView
BN作为一个有效的工具用于减少参数内部协变量,可加速训练过程。BN广泛应用于各大先进模型中。其关键在于归一化层,应用轴对齐对输入分布做白化操作,在保持网络表现能力的情况下做缩放和平移操作。白化操作有利用在一个batch上的统计信息。并且这样处理对训练过程产生额外的正则化效果。
白化操作示意图如下:

对于原数据 A A A,大致分布在坐标轴第一象限,这对于随机初始的模型(绿色和蓝色线),学习起来比较麻烦(概率上来讲离得远要调整次数就多点)。白化操作就是去均值变换到 B B B,再放缩到 C C C。这样数据分布在远点附近,学习起来要方便的多。
用数学表达式来描述BN层:对于一个特定的修正单元 x x x,一个batch记为 B B B,有 m m m个训练样本记为 x B = x 1 , . . . , x m x_{B}={x_1,...,x_m} xB=x1,...,xm,BN操作如下:
x i ^ = B N ( x i ) = x i − μ B σ B 2 + ϵ \hat{x_i}=BN(x_i)=\frac{x_i-\mu_{B}}{\sqrt{\sigma_{B}^{2}+\epsilon}} xi^=BN(xi)=σB2+ϵxi−μB
ϵ > 0 \epsilon>0 ϵ>0是一个极小的常量,用于预防出现数值异常。其中 μ B \mu_B μB和 σ B 2 \sigma_{B}^{2} σB2分别是平均值和方差,计算如下:
μ B = 1 m ∑ j = 1 m x j , σ B 2 = 1 m ∑ j = 1 m ( x j − μ B ) 2 \mu_B=\frac{1}{m}\sum_{j=1}^mx_j, \ \ \sigma_{B}^{2}=\frac{1}{m}\sum_{j=1}^{m}(x_j-\mu_B)^2 μB=m1j=1∑mxj, σB2=m1j=1∑m(xj−μB)2
白化操作是做缩放和平移:
y i = B N γ , β ( x i ) = γ x i ^ + β y_i=BN_{\gamma,\beta}(x_i)=\gamma\hat{x_i}+\beta yi=BNγ,β(xi)=γxi^+β
其中 γ , β \gamma,\beta γ,β是可学习的。
BN操作示意图如下:

BN操作可应用在模型中任何激活操作。在训练期间,BN层的统计信息在每次batch前是做特定更新的,使用特定的 ( γ , β ) (\gamma,\beta) (γ,β)配合高的学习率,可加快训练速度。 在测试期间,整个数据集为 τ \tau τ,BN的统计信息固定为 μ τ \mu_{\tau} μτ和 σ τ \sigma_{\tau} στ。并且,可以将训练好的BN层参数和CONV层的权重融合,加速BN层操作。
Memory Optimization Strategies
先看BN的标准用法(不节省内存)和广泛使用的checkpointing方案。
Standard:
下图Figure 2(a)展现了大部分深度学习框架中使用的构建BN模块的标准实现:
- 绿色表示的是前向传播
- 灰色突出为了补偿节省内存而做的额外计算
- 天蓝色表示的反向传播
- 虚线框表示前向传播时需要存储的值,用于反向传播,这显著的影响内存占用量.
x和z存储起来用于反向传播,论文为了表示清楚,省去了2个额外的缓冲区,用保存BN层反向时期的 μ B \mu_{B} μB和 σ B \sigma_{B} σB。
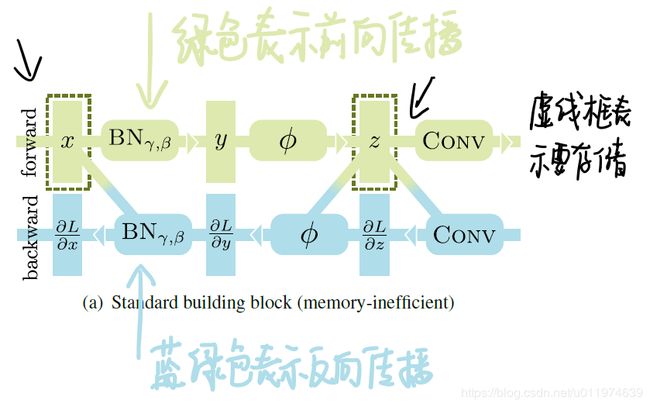
在前向传播时,输入 x x x和输出 z z z存储起来用于反向传播。变量 x x x在反向传播期间用于通过BN层计算梯度 ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L和 ∂ L ∂ γ \frac{\partial L}{\partial \gamma} ∂γ∂L,而 z z z用于激活等后续操作所需。
Checkpointing:
该方案在训练神经网络时存储部分变量,例如下图Figure 2(b)中,存储一个变量 x x x,在反向传播期间,通过 x x x再作一次正向计算得到 z z z(即图中灰色部分, 从而得到和Standard存储两个变量一样的效果:

显然,这需要额外的计算量来弥补节省内存带来的消耗。值得注意的是,在反向传播期间重计算BN层时(灰色部分),可以重复使用前向传播时的 μ B \mu_{B} μB和 σ B \sigma_{B} σB,并可将归一化和随后的仿射变换融合到单个缩放-平移操作。这可以减少第二次计算前向BN计算花费。
论文提出的三种优化方案
下面的三种方案是论文的贡献,第一种是针对checkpointing做了改进。第二和第三种方案是使用INPLACE-ABN,在节省内存的同时有着更低的计算成本,且容易集成到现有的深度学习框架中。
(针对改进)Checkpointing (proposed version):
在先前的checkpointing中,计算不是最优的。可通过存储 x ^ \hat{x} x^而不是 x x x省去额外计算操作。具体来说,如果没有存储 x ^ \hat{x} x^,那么反向传播时穿过BN层需要重计算 x ^ \hat{x} x^。对此,论文认为存储 x ^ \hat{x} x^更有效。如下图:

可通过 x ^ \hat{x} x^计算出 z z z,即 π γ , β ( x ^ ) = γ x ^ + β \pi_{\gamma,\beta}(\hat{x})=\gamma \hat{x}+\beta πγ,β(x^)=γx^+β,后面再接激活操作。
(INPLACE-ABN方案1):In-Place Activated Batch Normalization I
上面节省存储空间策略局限在于最后一层(图例中的 C O N V CONV CONV),依赖于非局部变量如 x x x(或 x ^ \hat{x} x^)计算梯度。这在现有的标准框架里面实现起来比较麻烦,因为在激活层后的任何层在反向传播过程中都依赖于 z z z,这都需要触发重计算(一直从x计算到z)。论文提出了如下的代替方案:

存储正向传播的 z z z,任何在激活层后的都有计算梯度的本地信息。通过BN层进行就地计算,再倒序计算 x ^ \hat{x} x^。但是这需要激活函数是可逆的,才能做此操作。
当前主流的激活函数ReLU不满足可逆条件,在4.1中论文使用Leaky ReLU这样具有小斜率的可逆函数可以很好的代替ReLU。同时还需要反转缩放-平移操作 π γ , β \pi_{\gamma,\beta} πγ,β,需要 γ ≠ 0 \gamma≠0 γ̸=0。
(INPLACE-ABN方案2):In-Place Activated Batch Normalization II
在In-Place ABN I的反向传播中可将 x ^ = π γ , β − 1 ( y ) = y − β γ \hat{x}=\pi_{\gamma,\beta}^{-1}(y)=\frac{y-\beta}{\gamma} x^=πγ,β−1(y)=γy−β这一计算进一步拆分为梯度 ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L和 ∂ L ∂ γ \frac{\partial L}{\partial \gamma} ∂γ∂L,使用 y y y的函数代替 x ^ \hat{x} x^。直接的倒置 π γ , β \pi_{\gamma,\beta} πγ,β恢复 x ^ \hat{x} x^应用 m m m缩放-平移操作。如果偏导数是直接基于 y y y的,那么修正梯度显示了同样的计算量可以被梯度 ∂ L ∂ x i \frac{\partial L}{\partial x_i} ∂xi∂L吸收,计算消耗为 O ( 1 ) O(1) O(1). 下图显示这样优化方法:

我们记 B N γ , β + BN_{\gamma,\beta}^{+} BNγ,β+作为 y y y函数的反向传播。
Technical Details
论文给出的INPLACE-ABN方案中两个主要的模块是可逆的激活函数(INPLCAE ABN I&II)和可逆的 π γ , β \pi_{\gamma,\beta} πγ,β(INPLCAE ABN I),实现通过BN层的反向传播依赖于 y y y.
可逆的激活函数
常见的激活函数是ReLU,这是不可逆的。论文采用了Leaky ReLU,对应的斜率 α = 0.01 \alpha=0.01 α=0.01,这和原本的ReLU效果类似:
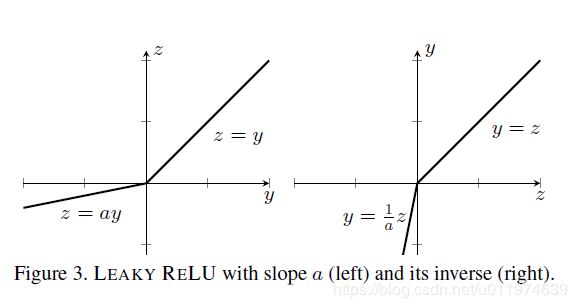
对于给定的斜率 α \alpha α,对应的计算公式:
f ( y ) = { y if y ≥ 0 α y if y < 0 , f − 1 ( z ) = { z if z ≥ 0 z α if z < 0 f(y)= \begin{cases} y& \text{if } y≥0\\ \alpha y& \text{if } y<0 \end{cases}, f^{-1}(z)= \begin{cases} z& \text{if } z≥0\\ \frac{z}{\alpha}& \text{if } z<0 \end{cases} f(y)={yαyif y≥0if y<0,f−1(z)={zαzif z≥0if z<0
Leaky ReLU和其对应的逆函数有相同的计算消耗。
Inversion of π γ , β \pi_{\gamma,\beta} πγ,β
在INPLACE-ABN I配置中,如果 γ = 0 \gamma=0 γ=0,因为 π γ , β − 1 ( y ) = y − β γ \pi^{-1}_{\gamma,\beta}(y)=\frac{y-\beta}{\gamma} πγ,β−1(y)=γy−β,那么 π γ , β \pi_{\gamma,\beta} πγ,β会到临界值。虽然在实际情况下很难遇到这个情况,可以通过给定容差预防。也可以直接固定为1,不学习参数。
INPLACE-ABN I: Backward pass through BN.
反向传播BN层时,梯度** ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L可由使用 ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L**(z直接求出)和 x ^ \hat{x} x^( y i = γ x i ^ + β y_i=\gamma\hat{x_i}+\beta yi=γxi^+β求出)表示。

上述的表达式与原始的BN层不同,新的BN层不依赖于 μ B \mu_{B} μB,因此我们在前向计算时只存储 σ B \sigma_{B} σB。
原本的BN层反向传播计算如下:
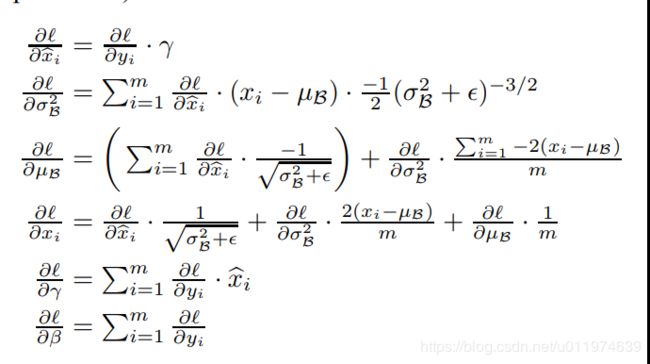
上述的计算过程在附录里面有具体的证明:

INPLACE-ABN II:Backward pass through BN.
论文提出的第二个解决方案使用 y y y来替换 x ^ \hat{x} x^,获得额外的内存节省:

Implementation Details
论文发布了使用Pytorch实现的代码,创建一个新的layer融合了BN层和激活层,我们可以在层内处理从 z z z到 x ^ \hat{x} x^的计算。对于前向和反向传播算法如下所示:
前向传播

- 1.第一行通过 x , γ , β x,\gamma,\beta x,γ,β计算出 μ B , σ B \mu_B,\sigma_B μB,σB,进而计算 y y y
- 2. y y y经过激活函数得到 z z z
- 3.存储了 z , σ B z,\sigma_{B} z,σB到缓存区,用于反向传播
除了要存储的,其他的计算都可以共享同一存储区域。
反向传播

-
1.从存储区恢复了 z , σ B z,\sigma_{B} z,σB
-
2.通过 z z z和 ∂ L ∂ z \frac{\partial L}{\partial z} ∂z∂L计算出梯度 ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L(即反向传播通过激活层)
-
3.通过 z z z解算出 y y y(因为设置了激活函数可逆)
-
4.如果是INPLACE-ABN I结构
- 5.通过 y y y计算出 x ^ \hat{x} x^(即 y = γ x ^ + β y=\gamma \hat{x}+\beta y=γx^+β)
- 6.通过 x ^ , ∂ L ∂ y , σ B \hat{x},\frac{\partial L}{\partial y},\sigma_B x^,∂y∂L,σB求梯度 ∂ L ∂ x , ∂ L ∂ γ , ∂ L ∂ β \frac{\partial L}{\partial x},\frac{\partial L}{\partial \gamma},\frac{\partial L}{\partial \beta} ∂x∂L,∂γ∂L,∂β∂L
-
7.如果是INPLACE-ABN II结构
- 通过 y , ∂ L ∂ y , σ B y,\frac{\partial L}{\partial y},\sigma_B y,∂y∂L,σB求梯度 ∂ L ∂ x , ∂ L ∂ γ , ∂ L ∂ β \frac{\partial L}{\partial x},\frac{\partial L}{\partial \gamma},\frac{\partial L}{\partial \beta} ∂x∂L,∂γ∂L,∂β∂L
注意II省去了一步,将关于 x ^ \hat{x} x^梯度直接吸收到一起了。
Experiment
论文在ImageNet分类任务和多个语义分割数据集上对INPLACE-ABN做了全面性能评价。此外,也做了运行时间分析。 论文实验平台是4张NVIDIA Titan Xp(12G)。除了指定的以外,所有实验的使用的激活函数为Leaky ReLU, 斜率 α = 0.01 \alpha=0.01 α=0.01
ImageNet Classification
论文在ImageNet-1K上训练了几个基于残差单元的先进模型证明了INPLACE-ABN结构的有效性。主要集中于两个问题:
- 激活函数对性能的影响
- INPLACE-ABN获得内存增益,补偿用于提高模型性能
ResNeXt-101/ResNeXt-152: 采用64分支的ResNeXt单元,使用101和152的层配置。在训练期间,将图片的小边缩小到256,再随机crop到 224 × 224 224×224 224×224。做了去均值和颜色增强等操作。使用带Nesterov动量的SGD,初始的学习率为0.1,权重衰减为 1 0 − 4 10^{-4} 10−4和动量0.9.一共跑90epochs,每过30epochs学习率降低10倍。
WideResNet-38: 该模型通过堆叠残差单元模型宽度和深度之间做权衡。与上述的训练配置类似,除了学习率是从0.1线性降低到 1 0 − 6 10^{-6} 10−6.
**Discussion of results:**下表显示测 Leaky ReLU对模型性能的影响:

可以看到与广泛使用的ReLU相比性能基本类似.
Baseline: 训练带标准的BN层的ResNeXt101,batch_size=256.
变体实验考虑了两种情况:
- 固定网络架构,利用节省出来的内存,把单个batchsize图片设置更多
- 即ResNeXt101,INPLACE-ABN,batch_size=512。准确率有一些提升
- **固定batchsize,**训练更大的网络主干
- 使用152层,batch_size=256.
- WideResNet-38. batch_size=256
此外还训练了一个同步梯度下降的,INPLACE-ABN的ResNeXt101.
实验结果如下:

可以看到几种变体相对于baseline都是有提升的~
Semantic Segmentation
Datasets used for Evaluation:
论文在Cityscapes, COCO-Stuff and Mapillary Vistas数据集上做了评估。 在Cityscapes使用了精标注的图片。
Segmentation approach:
论文采用DeepLabv3的架构,具体来说,就是使用扩张卷积扩展特征分辨率,使用ASPP捕获不同尺度的上下文信息,ASPP的不同卷积和全局特征输出共1280通道,经过一个CONV+BN+ACT降维到256,经过logit得到最终输出。 论文使用INPLACE-ABN策略替换DeepLabv3。
所有的CityScapes实验都设置了360epochs。学习率采用poly策略,初始学习率为 2.5 × 1 0 − 3 2.5×10^{-3} 2.5×10−3. 因为COCO-Stuff数据集较大,设置训练了30epochs. 使用SGD,动量0.9,衰减 1 0 − 4 10^{-4} 10−4。数据增强使用随机的水平翻转和随机的尺度放缩.
Discussion of Results.:
下表报道了在CityScapes、COCO-stuff上不同BN配置的结果。
STD-BN标准的BN层+Leaky ReLUINPLACE-ABN,FIXED CROP固定裁剪图片大小,将每个batch数量提升到最大(表格从16提升到了28了)INPLACE-ABN,FIXED BATCH固定batchsize,将裁剪尺寸提升到最大(表格从512提升到了672了)INPLACE-ABN(sync),FIXED BATCH梯度同步下降
结果包含以ResNeXt101和WideResNet38为主体的两组实验。WideResNet38整体上表现较好一些。两个主体都在ImageNet-1K上做过预训练。所有的结果都是用单一尺度测出出来,没有翻转图片。(论文吐槽了一下:这是故意的避免一些花里胡哨的方法稀疏测试结果)

可以看到使用INPLACE-ABN结构的数据吞吐量增加了70%。使用更好的分辨率效果要比更大的batch要好。
Optimizing Settings for Cityscapes and Vistas Datasets.:
在Cityscapes和COCO-Stuff上做了一些进阶实验。每个batch中crops了12个 680 × 680 680×680 680×680尺寸,使用在ImageNet-1K上预训练的ResNeXt152继续微调。性能提升到了78.49%.
对于WideResNet38做了如下改变:
- 使用crop了16个的 712 × 712 712×712 712×712,达到了79.02%
- 使用crop了12个的 872 × 872 872×872 872×872,达到了79.16%
对于CLASS-UNIFORM SAMPLING策略,使用统一的采样策略,即大致让所有的类别出现的概率一致(过度采样代表性不足的类别)。可看到这在没有使用额外数据的情况下达到了79.4%。

因为Mapillary Vistas数据集较大,故使用和CityScapes上表现最佳的配置,初始学习率提高到了 3.5 × 1 0 − 3 3.5×10^{-3} 3.5×10−3,跑了90个epochs.达到了53.12%比17年冠军51.59%要好。table 4中显示了关于LSUN2017基于PSPNet的训练配置。
Timing analysis
除了讨论新方案在内存性能上的影响。论文进一步讨论了实际运行时间上的变化。论文比较了在连续执行传统方案、Checkpointing和新方案的运行时间。通过对32张图片在ResNeXt101的前4组COnv时间分析,时间对比如下:

可以看到新的方案相较于checkpointing要了一倍.
Conclusion
论文提出了INPLACE-ABN用于替换现在广泛使用的BN+ACT层组合,针对现有的深度学习框架做了内存优化。相比于BN+ACT标准方案节省了50%的内存却只增加了少许计算量。论文的内存管理方案与广泛使用的checkpointing相比,在反向传播期间能够向后重组丢弃的缓存区,能够封装成单个layer,更容易实现。
论文在ImageNet-1K做了分类测试,在Cityscapes, COCO-Stuff and Mapillary Vistas做了语义分割测试。将节省出的内存用于更大的batch和更大的crop,获得了更佳的性能。