深度学习 之八 【循环神经网络 RNN】
1.循环神经网络 Recurrent Neural Network
循环神经网络,一般用在
语音识别,例如:Google Assistant, Apple Siri, Amazon Alexa
股票涨跌,随着时间的变化股票的涨跌
自然语言处理(NLP),
机器翻译,
手势识别
这么多有趣的应用,我们来一探究竟!
- 你喜欢玩游戏和机器人吗?查看 Open AI 制造的 DotA 2机器人。
- 为无声电影自动添加声音如何?
- 这个酷炫工具是用来自动手写生成。
- Amazon 的语音转文本使用高质量的语音识别 Amazon Lex。
- Facebook 使用循环神经网络和长短期记忆网络技术 构建语言模型。
- Netflix也使用循环神经网络模型:这是个很有趣的阅读材料。
例如,一个预测字母的RNN架构图
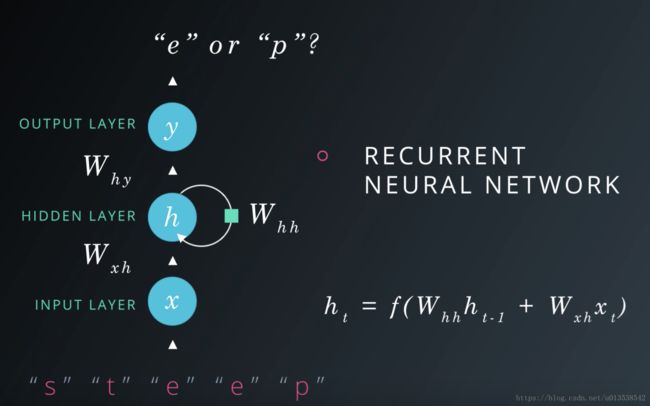
展开RNN网络架构图
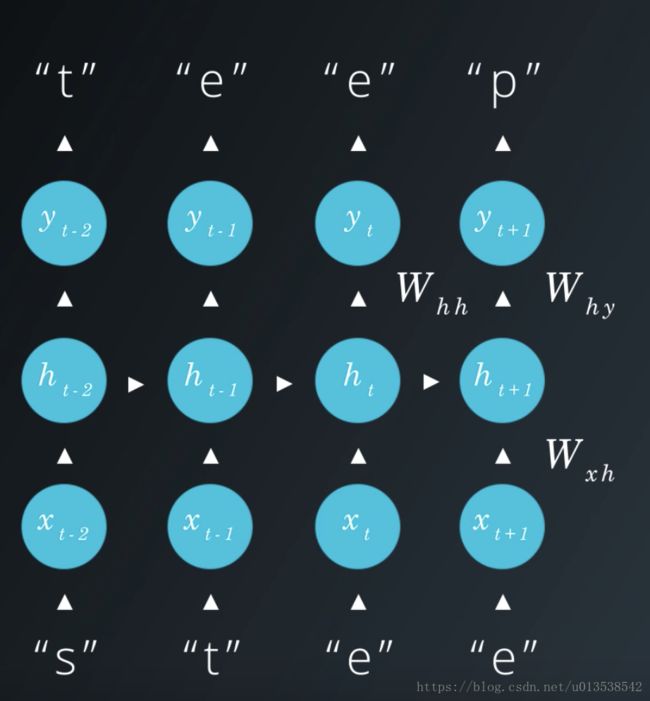
使用数字的方式展开RNN网络架构图

2.LSTM (Long Short Term Memory长短期记忆)
下图是一个LSTM的节点运算图,分别使用 Forget Gate, Remember Gate, Learn Gate, Use Gate,紧接着第二张图,就是它的运算规则。
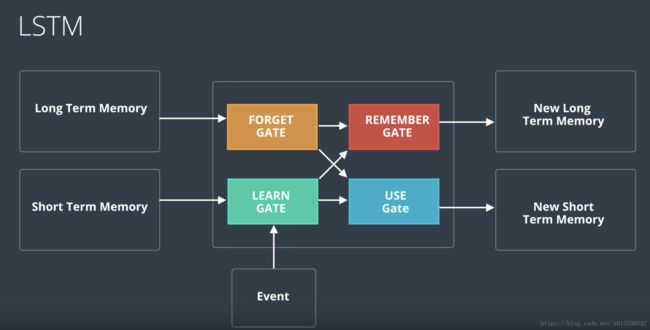
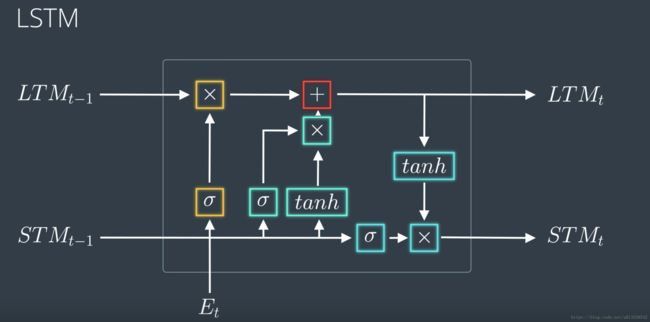
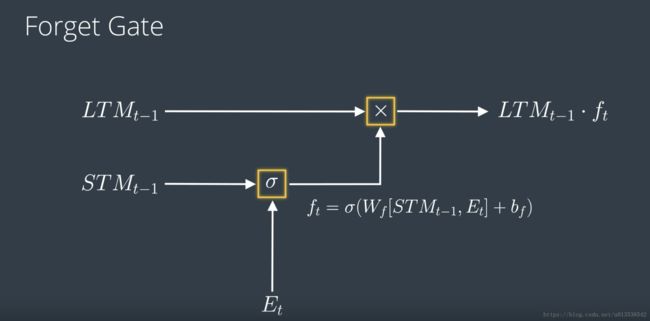
遗忘门 Forget Gate
工作原理是:遗忘门会接受一个长期记忆并决定要保留还是遗忘哪部分记忆。
数学公式:
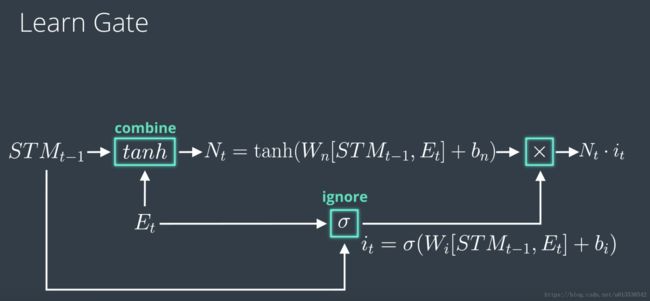
学习门 Learn Gate
工作原理是:它会接受短期记忆和事件,然后将两者合并起来,然后忽略其中一部分,只保留重要的部分
数学公式:
记忆门 Remember Gate
工作原理是:它会接受从遗忘门输出的长期记忆以及从学习门输出的短期记忆,直接把两者合并来气,生成一个新的长期记忆。
数学公式:

使用门 Use Gate
工作原理是:使用门也称作为输出门,它会用刚从遗忘门输出的长期记忆和刚从学习门输出的短期记忆,来生成一个新的短期记忆,和一个输出结果。
数学公式:

其他架构
GRU 门限递归单元(Gate Recurrent Unit)
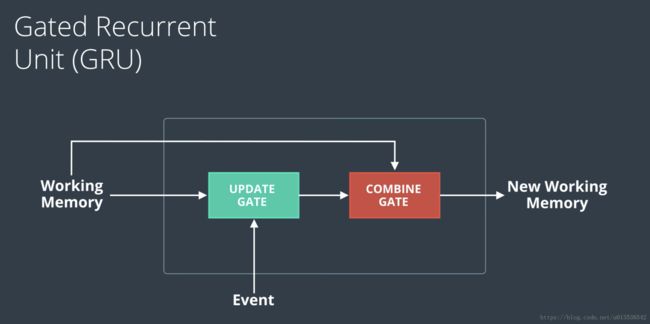
GRUs 的一些参考文献
- Michael Guerzhoy的论文
- Steve Carell的论文
窥视孔连接的LSTM (Peephole Connections)

3.超参数
凭直觉和经验设置超参数
3.1 优化器参数
学习率,通常我们的设置范围是 0.000001 到 0.1
自适应学习优化器
- AdamOptimizer
- AdagradOptimizer
3.2 模型架构参数
3.3 MiniBatch 大小
之所以需要设置batch size是因为计算资源问题,将batch size设置小的值,可以降低训练速度,但是可以让计算机努力的训练它,当特别大的数据进行训练时,计算资源可能会出现内存不足的现象。
当设置batch size太小时,假如,如:1,2,4,8,16 这样会使训练速度变慢
当设置batch size太大时,假如,如:512,1024,2048 这样会导致计算成本过高,并降低准确度
一般我们将batch size设置为 32, 64, 128, 256
Systematic evaluation of CNN advances on the ImageNet ,作者:Dmytro Mishkin, Nikolay Sergievskiy, Jiri Matas
3.4 隐藏层数量
“在实践中,3 层神经网络的性能通常优于 2 层神经网络,但是更深(4、5、6 层)帮助不大。这与卷积网络形成鲜明对比,人们发现在卷积网络中深度是对良好的识别系统极其重要的组成部分(例如,10 个可学习层的数量级)。” ~ Andrej Karpathy (来源)
3.5 RNN cell
- LSTM Cell
- GRU Cell 门控循环单元
- Valilla RNN Cell
LSTM和GRU的性能都高于valilla
LSTM 与 GRU 对比
“这些结果清楚地表明了门控单元较于传统循环单元的优点。收敛往往更快,而且最终的解决方案往往会更好。但是,我们的结果在 比较 LSTM 和 GRU 方面并非决定性的,这表明门控循环单元类型的选择可能在很大程度上取决于数据集和相应的任务。”
根据序列建模的门控循环神经网络的实证评估,作者:Junyoung Chung、Caglar Gulcehre、KyungHyun Cho、Yoshua Bengio
“除了语言建模,GRU 在所有任务上都胜过了 LSTM”
循环网络架构的实证探索作者:Rafal Jozefowicz、Wojciech Zaremba、Ilya Sutskever
“我们一致的发现是至少两层的深度是有益的。但是,在两层和三层之间,我们的结果不太一致。此外,LSTM 和 GRU 之间的结果也不一致,但都显著优于 RNN。”
可视化和理解循环网络,作者:Andrej Karpathy、Justin Johnson、Li Fei-Fei
“哪些变体最好?它们的差异是否重要?Greff, et al. (2015) 对常用的变体进行了详尽的对比,发现它们都差不多一样。Jozefowicz, et al. (2015) 测试了超过一万个 RNN 架构,发现某些在特定任务上的性能优于 LSTM。”
理解 LSTM 网络,作者:Chris Olah
RNN 架构示例
- 应用 Cell 层 大小 词汇 嵌入大小 学习率
- 语音识别(大词汇表) LSTM 5, 7 600, 1000 82K, 500K – – paper
- 语音识别 LSTM 1, 3, 5 250 – – 0.001 paper
- 机器翻译 (seq2seq) LSTM 4 1000 原词汇:160K,目标词汇:80K 1,000 – paper
- 图片字幕 LSTM – 512 – 512 (固定) paper
- 图像生成 LSTM – 256, 400, 800 – – – paper
- 问题回答 LSTM 2 500 – 300 – pdf
- 文本总结 GRU 200 原词汇:119K,目标词汇:68K 100 0.001 pdf
关于超参数的更多文章
如果你想了解有关超参数的更多信息,以下是关于此主题的一些很好的资源:
- 用基于梯度下降的方法训练深度框架的实践推荐指导,作者:Yoshua Bengio
- 深度学习手册 - 第 11.4 章:选择超参数,作者:Ian Goodfellow、Yoshua Bengio、Aaron Courville
- 神经网络和深度学习手册 - 第 3 章:如何选择神经网络超参数?作者:Michael Nielsen
- 有效 BackProp (pdf) ,作者:Yann LeCun
更多专业资源:
- 如何生成好的单词嵌入?作者:Siwei Lai、Kang Liu、Liheng Xu、Jun Zhao
- 系统评估 CNN 在 ImageNet 上的进步,作者:Dmytro Mishkin、Nikolay Sergievskiy、Jiri Matas
- 可视化和理解循环网络,作者:Andrej Karpathy、Justin Johnson、Li Fei-Fei