第十一记·Sqoop安装及使用
Sqoop:SQL-to-Hadoop连接传统关系型数据库和Hadoop的桥梁把关系型数据库的数据导入到Hadoop与其相关的系统(HBase和Hive)中把数据从Hadoop系统里抽取并导出到关系型数据库里利用MapReduce加快数据传输速度,批处理方式进行数据传输。主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop1&Sqoop2两个不同版本,完全不兼容,Sqoop2比Sqoop1的改进引入sqoopserver,集中化管理Connector等,多种访问方式:CLI,WebUI,RESTAPI。引入基于角色的安全机制。
sqoop安装步骤
1.解压:
$ tar -zxvf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/modules/cdh/2.更改conf目录下的文件:
$ cp sqoop-env-template.sh sqoop-env.sh3.拷贝jdbc驱动包到lib目录:
$ cp /opt/modules/apache-hive-0.13.1-bin/lib/mysql-connector-java-5.1.27-bin.jar lib/4.更改sqoop-env.sh文件:
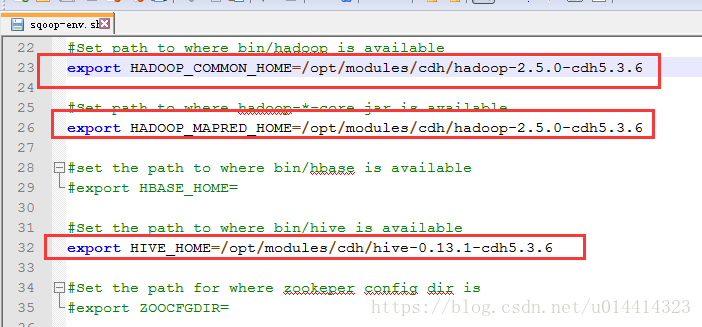
5.测试是否配置成功:
$ bin/sqoop list-databases \
--connect jdbc:mysql://hadoop01.com:3306/ \
--username root \
--password 123456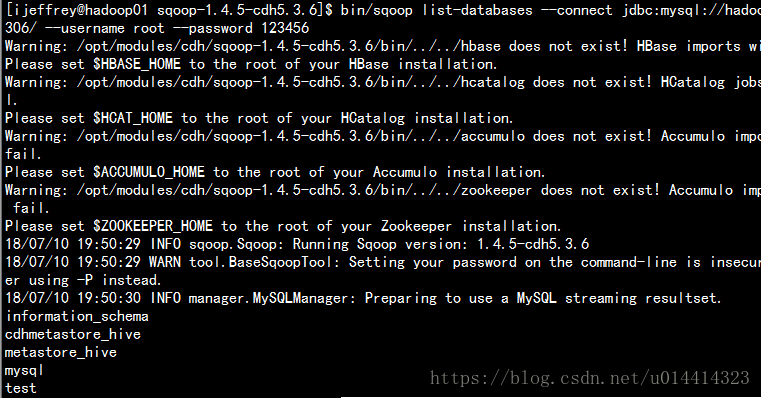
如图显示了MySQL数据库说明配置成功。
Sqoop使用--常用命令
一、sqoop导入import、导出export
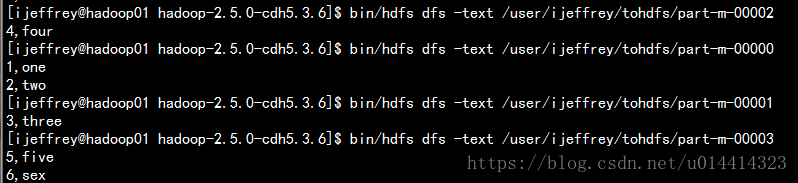
1.mysql中的sqoop库的表tohdfs上传到hdfs
bin/sqoop import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--table tohdfs 
2.控制map任务的个数 -m,--num-mappers
输出目录路径如果存在则删除--delete-target-dir
指定输出目录 --target-dir
bin/sqoop import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--delete-target-dir \
--target-dir /sqoop_test \
--table tohdfs \
-m 1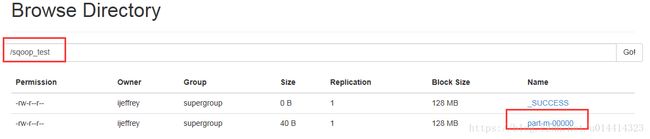

3.mysql ---> hdfs : 输出output
指定数据输出分隔符(mysql默认是 ',') --fields-terminated-by
指定快速模式 --direct
bin/sqoop import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--delete-target-dir \
--target-dir /sqoop_test \
--table tohdfs \
-m 1 \
--fields-terminated-by "\t" 
4.sqoop job
bin/sqoop job --create job01 创建
bin/sqoop job --delete 删除任务
bin/sqoop job --exec 执行job
bin/sqoop job --show 显示job的详细信息
bin/sqoop job --list 显示可执行的job 创建任务
bin/sqoop job \
--create job01 \
--import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--target-dir /sqoop_test \
--table tohdfs \
-m 1 \
--fields-terminated-by "\t" \
--check-column id \
--incremental append \
--last-value 10 执行任务
bin/sqoop job --exec job01 执行job的时候会确认密码,指定成mysql的登录密码
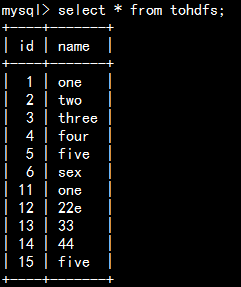

5.导出某几列数据或者几行数据 --where -e,--query
bin/sqoop import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--delete-target-dir \
--target-dir /where_test1 \
--table tohdfs \
-m 1 \
--fields-terminated-by "\t" \
--where 'id<6' 

导出某几列: -e,--query
bin/sqoop import \
--connect jdbc:mysql://hadoop21.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--delete-target-dir \
--target-dir /where_test2 \
-m 1 \
--fields-terminated-by "\t" \
--query 'select * from tohdfs where id <5 and $CONDITIONS' query使用要点:
a.不能使用--table
b.如果--query的sql语句带着where字句,
c.必须要加上标识符$CONDITIONS
6.mysql ---> hive import(主要用来分析mysql存储历史数据,如公司的业务日志,系统数据等)
将MySQL数据库sqoop下面的表tohdfs导入 到 hive中db_mysql库下面的hive_table表。
bin/sqoop import \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--direct \
--table tohdfs \
--delete-target-dir \
--hive-import \
--hive-database db_mysql \
--hive-table hive_table \
--fields-terminated-by "\t" \
-m 1
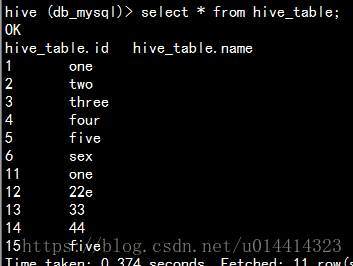
机制:运行MapReduce任务时,结果将会保存在默认的输出目录上,将结果集文件移动到hive对应表文件夹下
二、sqoop导出export
1、常规模式导入数据到mysql
bin/sqoop export \
--connect jdbc:mysql://hadoop01.com:3306/sqoop \
--username root \
--password 123456 \
--table tomysql \
--export-dir /where_test1 \
-m 1 \
--input-fields-terminated-by '\t'先在mysql中创建表
create table tomysql(
id int primary key not null,
name varchar(20) not null
);
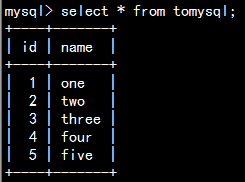
2、sqoop运行一个file文件
--options-file 选项类似于Hive中使用 -f 选项
在mysql建表file_to_mysql
create table file_to_mysql(
id int primary key not null,
name varchar(20) not null
);vi一个文件 :注意格式,一行key一行value
export
--connect
jdbc:mysql://hadoop01.com:3306/sqoop
--username
root
--password
123456
--table
file_to_mysql
--export-dir
/where_test1
-m
1
--input-fields-terminated-by
'\t'执行文件命令
bin/sqoop --options-file /opt/datas/file_tomysql.txt
导入成功。
XY个人笔记