Matrix Factorization 学习记录(一):基本原理及实现
Matrix Factorization 学习记录(一):基本原理及实现
最近在学习Matrix Factorization,也就是矩阵的分解。 这个技术目前主要应用于推荐系统领域,用于实现隐含语义模型(Latent Factor Model)。通过矩阵分解,一方面可以减少运算量,另一方面可以很好的解决由于用户数目和物品数目过多引起的行为矩阵稀疏化问题。我虽然暂时不去做推荐系统,但是我觉得这种使用embedding形式来表示用户/物品向量的思维非常值得借鉴,可能可以用于其他地方,因此学习了一下。
关于Matrix Factorization的原理,目前已经有很多现有的资料。我这里就不再赘述,只简要描述一下。有兴趣的可以去参阅wiki上的解释。
Matrix Factorization的基本原理
Matrix Factorization的原理比较简单,就是将一个矩阵D分解为U和V的乘积,即对于一个特定的规模为m*n的矩阵D,估计出规模分别为m*k和n*k的矩阵U和V,使得 UVT U V T 的值尽可能逼近矩阵D。一般来讲,k的取值应该满足 k≤min{m,n} k ≤ m i n { m , n } ,这样矩阵分解才有意义。如果在推荐系统中,D代表用户对商品的行为矩阵的话,那么U和V则分别代表embedding表示的用户和商品向量。
以公式来表示的话,就是
其中 Ui U i 表示U矩阵第i行的向量, Vj V j 表示V矩阵第j行向量。
为了限制U,V的取值呈现一个以0为中心的正态分布,这里对U,V的值加上正则项,得到目标优化项
这里定义 ‘ ‘ 。 对L求Ui的偏微分,得到对应梯度
将该结果扩展,可以得到对L求U和V的偏微分为
得到梯度以后,既可以通过梯度对U,V的值进行迭代。如果是采用最简单的梯度下降的话,则迭代公式如下
其中 α α 表示学习速率。
Matrix Factorization的基本实现
进行了上述公式推导以后,可以对Matrix Factorization通过代码来实现出来。这篇文章实现了Matrix Factorization的基本功能,但是由于其在计算梯度阶段只计算了矩阵中单个点的梯度,因此其代码实现中单次迭代也是采用三重循环来实现。算上迭代循环,整个函数中出现了4重循环,显得效率不高。为了方便对照,下面贴上4重循环实现的函数:
def lfm(a,k):
'''
来源: https://www.cnblogs.com/tbiiann/p/6535189.html
其在计算梯度阶段只计算了矩阵中单个点的梯度,因此其代码实现中单次迭代也是
采用三重循环来实现。算上迭代循环,整个函数中出现了4重循环,显得效率不高
参数a:表示需要分解的评价矩阵
参数k:分解的属性(隐变量)个数
'''
assert type(a) == np.ndarray
m, n = a.shape
alpha = 0.01
lambda_ = 0.01
u = np.random.rand(m,k)
v = np.random.randn(k,n)
for t in range(1000):
for i in range(m):
for j in range(n):
if math.fabs(a[i][j]) > 1e-4:
err = a[i][j] - np.dot(u[i],v[:,j])
for r in range(k):
gu = err * v[r][j] - lambda_ * u[i][r]
gv = err * u[i][r] - lambda_ * v[r][j]
u[i][r] += alpha * gu
v[r][j] += alpha * gv
return u,v 而按照我之前的推导,可以通过矩阵计算直接算的U和V的梯度,通过这种方法实现的代码如下所示:
def LFM_ed2(D, k, iter_times=1000, alpha=0.01, learn_rate=0.01):
'''
此函数实现的是最简单的 LFM 功能
:param D: 表示需要分解的评价矩阵, type = np.ndarray
:param k: 分解的隐变量个数
:param iter_times: 迭代次数
:param alpha: 正则系数
:param learn_rate: 学习速率
:return: 分解完毕的矩阵 U, V, 以及误差列表err_list
'''
assert type(D) == np.ndarray
m, n = D.shape # D size = m * n
U = np.random.rand(m, k) # 为何要一个均匀分布一个正态分布?
V = np.random.randn(k, n)
err_list = []
for t in range(iter_times):
# 这里,对原文中公式推导我认为是推导正确的,但是循环效率太低了,可以以矩阵形式计算
D_est = np.matmul(U, V)
ERR = D - D_est
U_grad = -2 * np.matmul(ERR, V.transpose()) + 2 * alpha * U
V_grad = -2 * np.matmul(U.transpose(), ERR) + 2 * alpha * V
U = U - learn_rate * U_grad
V = V - learn_rate * V_grad
ERR2 = np.multiply(ERR, ERR)
ERR2_sum = np.sum(np.sum(ERR2))
err_list.append(ERR2_sum)
return U, V, err_list使用numpy来执行矩阵运算,屏蔽了底层的具体实现,且效率比循环更高。如果将来需要将该模型运用于实际数据,也可以通过使用spark等框架来执行矩阵计算。
Matrix Factorization的简单测试
测试方案:
if __name__=='__main__':
D = np.array([[5,5,0,5],[5,0,3,4],[3,4,0,3],[0,0,5,3],[5,4,4,5],[5,4,5,5]])
U, V, err_list = LFM_ed2(D, 3, iter_times=200, learn_rate=0.01, alpha=0.01)
print(err_list[-1])
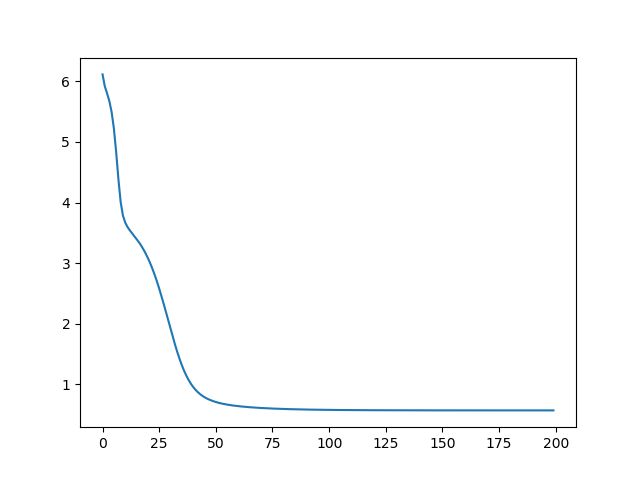
err_log = np.log(np.array(err_list))
plt.plot(err_list)
plt.show()
plt.figure(2)
plt.plot(err_log)
plt.show()得到的估计误差和误差的对数值分别如下图所示
估计误差↓
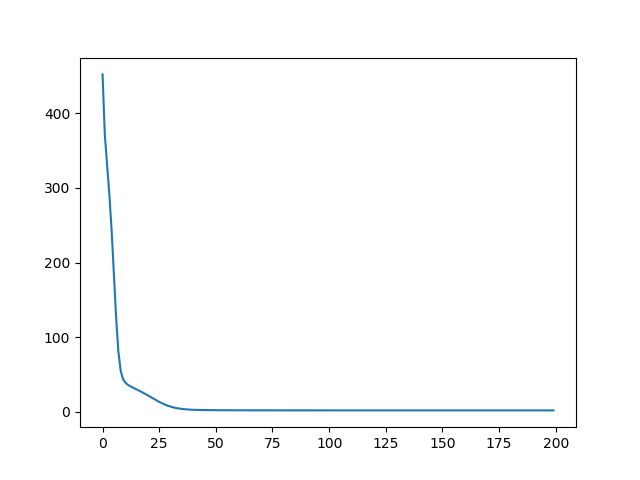
对数误差↓