7 Support Vector Machines
7.1 Large Margin Classification
7.1.1 Optimization Objective
支持向量机(SVM)代价函数在数学上的定义。
复习一下S型逻辑函数:

那么如何由逻辑回归代价函数得到支持向量机的代价函数(对于一个示例):
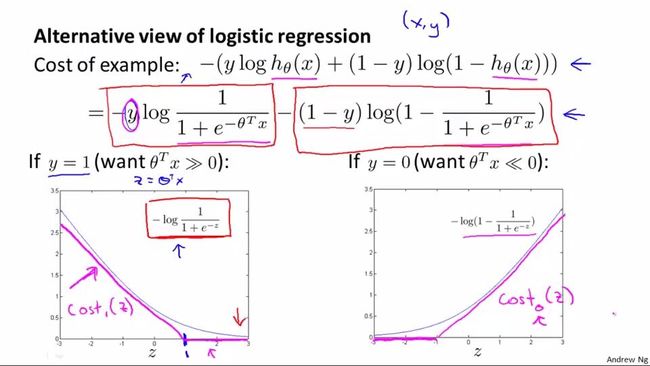
其实就是将逻辑回归的代价函数中的log(1/(1+e^(-ΘTx)))和log(1-1/(1+e^(-ΘTx)))分别替换为cost1(ΘTx)和cost0(ΘTx)(cost0和cost1分别对应y=0和y=1时的目标函数定义。后面会知道,cost1(ΘTx)应该是cost1(ΘTf),cost0(ΘTx)应该是cost0(ΘTf))。并对m和λ进行提取。
可以对比:
逻辑回归的代价函数(优化目标):
SVM的代价函数和假设:
注意一下C的作用:C是控制对于误分类训练样本惩罚程度的,为正值。
the C parameter is a positive value that controls the penalty for misclassified training examples.
可以看到逻辑回归和SVM的假设的优化重点不同,逻辑回归的假设优化重点在第一项,SVM的优化重点在第二项。
做道题:
答案:可以将1式提取mλ,则1式的优化结果与2式相同。

7.1.2 Large Margin Intuition
支持向量机被称为大间距分类器的原因以及理解SVM的假设。
最小化SVM代价函数的必要条件。

来直观理解支持向量机被称为大间距分类器的原因。取代价函数中的C非常非常大的时候为例作为说明。
当C非常大的时候,J(Θ)将会得到能使第一个累加项([]中的内容)的和近似为0的优化解。当你最小化这个关于变量Θ的函数的时候,会得到如图的黑色的决策边界,这就是SVM的决策边界。黑色边界有着较大的间距(margin),努力用一个最大间距来分离样本,这也是SVM被称为大间距分类器的原因,这也是求解优化问题的结果。
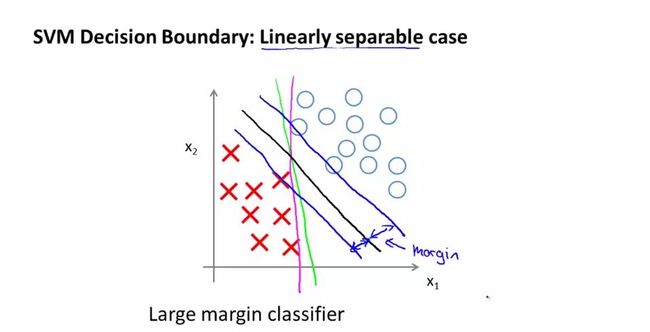
如果C很小,就会得到这条黑线;如果C很大,黑线就会顺时针转动变为粉线。C的作用类似于1/λ,λ就是逻辑回归正则化中使用过的λ。

7.1.3 Mathematics Behind Large Margin Classification
从数学角度,用向量内积来理解SVM的目标函数,解释为什么支持向量机是一个大间距分类器。
关于向量内积的预备数学知识。
下图中介绍二维向量u和二维向量v的内积情况,首先介绍两向量夹角≤90。的情况:
u和v的内积是uTv=||u||·||v||·cosθ=u1v1+u2v2=||u||·p,这里p就是v在u上的投影。过程就是将v投影至u向量,记其标量长度为p(有正负,与u同向为正,反向为负)。

下面讨论当C非常大的目标函数的情况下,SVM能有效产生大间距分类的原因。
SVM标准的代价函数:

C非常大时,SVM的代价函数可以简化为以下形式:
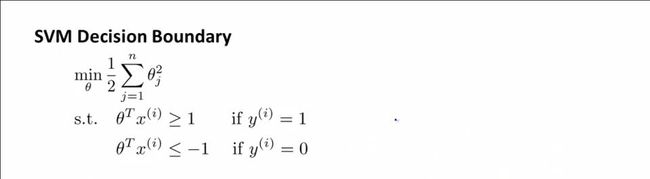
前提简化:
1.n=2(只有2个特征)。
2.Θ0=0,这使决策边界通过原点。其实当Θ0≠0的时候,类似于下面的推导过程,还是可以得到SVM能有效产生大间距分类的原因。
那么C非常大时,代价函数进一步可以演变为以下的意义:代价函数就是求向量Θ的范数(长度)最小值。

对应的,对约束条件进行理解(结合上面关于内积的预备知识):
如果向量机选择这条绿色的边界,那么该决策边界对应的向量Θ应该垂直边界代表的直线(因为直线上的点与原点形成的向量与向量Θ的内积为0),且向量Θ应该指向正例。这时,可以看到x(1)在向量Θ上的投影p(1)的标量长度非常小,对应的如果要满足p(i)*||Θ||≥1,那么||Θ||就会很大。同样也可以分析x(2)。

相反的,如果是下面的绿色直线x1=0作为决策边界,可以看到x(1)在向量Θ上的投影p(1)的标量长度较大,对应的如果要满足p(i)*||Θ||≥1,那么||Θ||就可以较小。同样也可以分析x(2)。在这里,x(1)和x(2)在向量Θ上的投影p(1)和p(2)之和的一半就是margin。

支持向量机最小化目标函数的目标是p(i)*||Θ||≥1的前提下,使得||Θ||尽可能的小,所以要选择能使p尽可能大的决策边界。支持向量机极大化这些p(i)的范数(训练样本到决策边界的距离)。
做道题:


答案:在坐标系中,默认横轴对应的是x1,纵轴对应的是x2。可以看到决策边界取x1=0时,左侧正例在向量上的投影Θ至少是2,右侧负例在向量Θ上的投影也至少是-2。又要满足约束函数||Θ||·p(i)=||Θ||·2≥1和||Θ||·p(i)=||Θ||·(-2)≤-1。min(p(i))=2,所以||Θ||≥1/2。所以是B。
下一节介绍如何利用支持向量机的原理,应用他们建立一个复杂的非线性分类器。
7.2 Kernels
7.2.1 Kernels I
讨论核函数是什么以及如何用核函数(kernels)构建复杂的非线性分类器。
对于一个特定的二元分类问题,如果要构造下图的决策边界,一般需要高阶项。如果用高阶项做特征变量,运算量会非常大,而且也不知道这些高阶项是不是我们所需要的,所以能不能选择别的特征变量或者有没有比这些高阶项更好的特征变量,或者说是否有不同的选择或者更好的选择来构造特征变量,以嵌入到假设函数中。有的,就要用到核函数。
定义决策边界对应的函数是Θ0+Θ1f1+Θ2f2+Θ3f3,其中f1、f2和f3就是相似度函数。

下图给定新的x点,计算该点与标记的3个标记点(landmark)l(1)、l(2)和l(3)之间的相似度f1、f2和f3。相似度函数就是所谓的核函数。在这里,就是高斯核函数,实际还有许多不同的核函数。这个相似度函数也可以写成K(x,l(i)),这里的x和l是向量。

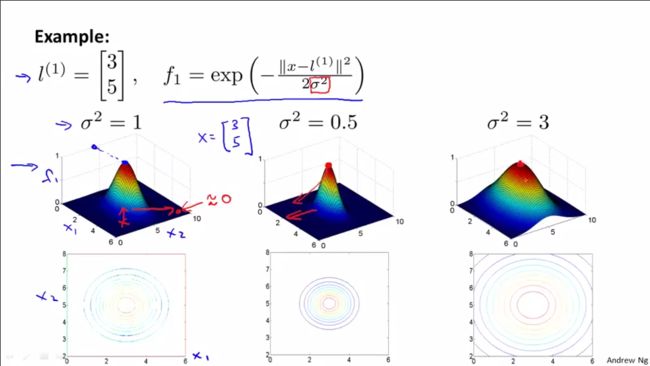
关于特征变量f1,高斯核函数情况下,具体的公式如下(忽略x0,这里的相似度函数是计算x和l向量之间的各分量的距离):当新给的点x距离l较近时,就x和l(1)比较相似,显然f1≈1;当新给的点x距离l较远时,就x和l(1)不相似,显然f1≈0。这样确定l(1),新给的x就能对应地求出相似度f1、f2和f3。

下面来看一下高斯核函数是怎么样子的,也就是特征变量f1计算的内容。
取特定的l(1)向量并且参数σ2=分别取1、0.5和3情况下的高斯核函数的3D曲面立体图以及曲面的等值线图。
1.3D曲面图上的z轴(高度)对应的就是f1的取值情况,在这里不同σ2情况下,f1取值都为0-1之间,极大值为1,极小值为0,就是高度不变。
2.σ2越大,曲线越“胖”,核函数凸起的宽度变宽了,等值线图也扩大了一些;从l(1)点向外移动,特征变量的值减小的速度变慢。
高斯核函数相当于衡量示例之间距离的相似函数,其中σ决定了特征变量(相似性度量)减少的速度快慢。
讲完特征变量的概念以后,来看一下特定Θ0、Θ1、Θ2、Θ3下,能得到什么样的预测函数。Θ0=-0.5,Θ1=1,Θ2=1,Θ3=0时,预测两个点离l(1)、l(2)和l(3)不同的距离来预测y值是1还是0。前提:如果Θ0+Θ1f1+Θ2f2+Θ3f3≥0,就预测为1。
1.距离l(1)较近的点,那么f1≈1,f2≈0,f3≈0,所以Θ0+Θ1f1+Θ2f2+Θ3f3=1≥0。
2.距离l(1)、l(2)和l(3)都较远的点,那么f1≈0,f2≈0,f3≈0,所以Θ0+Θ1f1+Θ2f2+Θ3f3=-0.5<0。

对大量的点进行相应的处理,特定Θ0、Θ1、Θ2、Θ3下(这里Θ0=-0.5,Θ1=1,Θ2=1,Θ3=0),距离l(1)、l(2)近的点的的预测值是1;距离l(1)、l(2)较远的点的预测值y是0。那么自然就会得到如图的决策边界(红线里面预测y=1,外面预测y=0)。这就是如何使用标记点和核函数来训练非常复杂的非线性判别边界的方法。

以上就是核函数的定义和以及我们如何在支持向量机中使用它们定义新的特征变量。我们通过标记点(landmark)和核函数(kernels)来定义新的特征变量,从而训练复杂的非线性分类器。
下面将会讲,我们如何得到这些标记点(landmark)以及其他的相似度函数是什么样的,如果有的话,是否能够代替上面用的高斯核函数。下节课将会来看看支持向量机如何通过核函数的定义,有效地学习复杂的非线性函数。
7.2.2 Kernels II
补充上一节缺失的一些细节以及支持向量机中的偏差-方差折中问题。
如何得到l(1)、l(2)、l(3)等标记点(landmark):选取所有训练样本为标记点。这说明特征向量是在描述新样本距离每一个测试样本的距离。
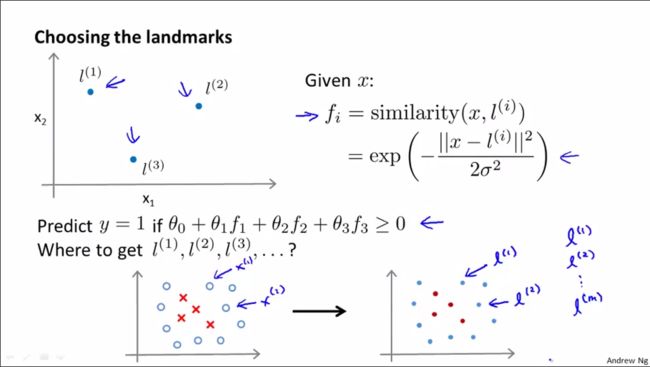
具体而言:给定m个训练样本,将这m个训练样本的位置作为landmark。然后输入x,x可以属于训练集、测试集合交叉验证集。我们计算特征值f1,f2,f3...最终得到由这些特征值得到的特征向量f。对于训练集中的数据,描述训练样本的特征向量。在这m个训练数据中,每一个训练数据x(i)所得的特征向量(核函数)f中,总有一维向量的值为1(因为这里x(i)=l(i))

已知Θ向量,如何对样本做出预测:给定x,计算特征向量f,只要当ΘTf>=0时就预测y=1,;否则,就预测y=0。其中的参数向量Θ是m+1维的(f0=1),这里有m+1个特征,额外的1是因为截距的原因。许多SVM软件包自动设置x0=1,自动设置截距Θ0。因此,实现SVM时,不用想逻辑回归那样添加x0=1这样的向量。

如何得到Θ变量。SVM中的代价函数:

具体而言就是求出能使代价函数取最小值的参数Θ。正则化项是n项的累加,这里n=m,因为特征变量的个数=训练集样本数。
实际使用SVM时,为了提高了计算效率,更适应大数据,对于代价函数的最后一项的细微改变使得最终的优化目标与上式直接最小化||Θ||2略有区别。将SVM的相关技术如果用于其他的机器学习算法,将会是不合适的(比如将核函数用于逻辑回归,这样的话,运行将会非常慢)。由于具体化技术,对某些细节的修改以及支持向量软件的实现细节,支持向量机可以与核函数搭配得很好。成熟的软件包中已经包含了SVM中的数值优化技巧,建议使用相关的软件包。
下面讨论SVM中的偏差-方差折中问题。涉及2个参数:代价函数中的参数C和核函数中(这里是高斯核函数)的σ2。
1.支持向量机中的参数C选择。C的作用和λ的作用相似(λ就是逻辑回归中的正则化参数):C较大,等价于λ较小,低偏差,高方差;C较小,等价于λ较大,高偏差,低方差。

2.选择高斯核函数中的σ2。假设只有一个特征量x:σ2越大,特征变量fi越平滑,相似函数随x的变化更平缓,从而带来高偏差和低方差。σ2越小,特征变量fi越陡峭,相似函数随x的变化更剧烈,从而带来低偏差和高方差。

做道题:
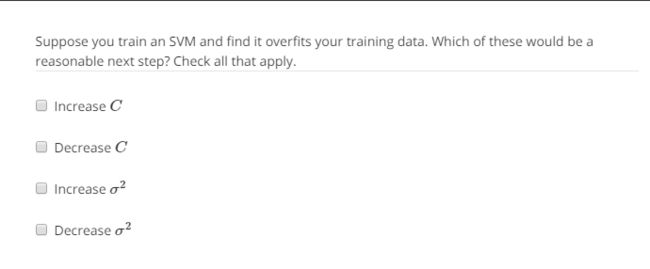
答案:

7.3 SVMs in Practice
7.3.1 Using An SVM
为了运行SVM,实际上需要做什么。
1.强烈建议使用一个高度优化的软件库,而不是尝试自己去实现。好的软件库,比如liblinear,linsvm等等。
2.选择参数C的值。
3.选择核函数(相似函数)。以下是两种最常见的核函数:
1)可以不用核函数,这种做法也叫线性核函数,仅仅使用ΘTx,可以理解为这种情况只是给你一个标准的线性分类器。什么情况下决定不用核函数(使用线性核函数):特征变量有n个,训练样本m个,n>>m。
2)使用高斯核函数。注意theta平方的选择。什么时候选择高斯核函数:特征变量有n个,训练样本有m个,m中等大于n。

如果选择高斯核函数,那么要实现函数来计算核函数的特定特征。注意,如果特征变量取值范围很不一样,在使用高斯核函数之前,对它们进行归一化是很重要的。

注意不是所有能够提出来的相似度函数都是有效的核函数。高斯核函数,线性核函数等其他人们在用的核函数都满足默塞尔定理(Mercer’s Theorem)。这条定理的作用就是确保所有的SVM软件包能够使用大量的优化方法,并能快速地获得参数Θ。
不常用的核函数如下:
1.多项式核函数。k(x,l)=(xTl+b)^n(b为常数,n为指数),x和l很接近的时候,k(x,l)会很大。这个核函数有2个参数:b和n。效果要比高斯核函数差一些。用在x和l都是严格非负数的时候,保证两者的内积非负。
2.字符串核函数。用于字符串相关,比如文本分类。
3.卡方核函数。
4.直方图交叉核函数。

最后的细节。
1.多类分类问题。许多SVM软件包已经内置用于多类分类的函数,可以直接使用;也可以使用逻辑回归中提及的一对多的方法进行分类(k个类别,k个参数theta)。
2.什么时候用逻辑回归,什么时候用SVM。
1)n相对于m比较大。使用逻辑回归或者线性核函数SVM
2)n较小,m是中等规模(不会过分的大,但要比n合适的大)。这时候高斯核函数的运行效果就会比较好。
3)n较小,m非常大。创造更多的特征量,使用逻辑回归或者不带核函数的SVM。
其实,逻辑回归或者不带核函数的SVM是相似的。可以用逻辑回归的地方就可以用不带核函数的SVM,反之亦然。
3.神经网络什么时候使用:对于上面的3种情况,神经网路都可能可以很好地解决,但是神经网络的运行很慢。

实际上,SVM是一个凸优化问题,有全局最小值。有时候,选择模型确实重要,但更重要的是数据是否充足,是否熟练,是否擅长做误差分析和调试学习算法,如何设计新的特征变量等等。
做道题:
答案:
习题:

BC

CD

AD