基于 TensorFlow 、OpenCV 和 Docker 的实时视频目标检测
在本文中,我将介绍如何在 Docker 容器中使用 Tensorflow Object-detection API 来执行实时(网络摄像头)和视频的目标检测。我使用 OpenCV 和 python3 的多任务处理库 multiprocessing、多线程库 multi-threading。
我会重点描述我在搭建过程中遇到的问题,以及我的解决方案 (有些还未解决)。完整的代码在这里 my Github:
https://github.com/lbeaucourt/Object-detection

使用Youtube视频进行视频处理测试
动机
我们从 Dat Tran 这篇文章开始挑战实时目标检测。我将使用 python 的 multiprocessing 库,增加处理网络摄像头时的 FPS。为了进一步提高可移植性,我将项目集成到 Docker 容器中。不过处理进出容器的视频流可能会有一点麻烦。
此外,在次项目我还添加了一个视频后处理功能,同样使用 multiprocessing 库来减少处理时间(使用 Tensorflow 原始目标检测 API 处理时间会非常长)。
实时和视频目标识别都可以在我的个人笔记本电脑上以高性能运行,仅使用 8GB CPU。
Docker在数据科学中的应用
我不在这里描述 Tensorflow 目标检测 API 的实现,因为相关的文档很多。我将展示数据科学家在日常工作中如何使用 Docker。注意,我会使用 Tensorflow 的经典 ssd_mobilenet_v2_coco 模型来提高性能。先将模型文件(.pb 文件)和相应的标签映射文件复制到本地,后面可能会用到。
我认为使用 Docker 应是当今数据科学家的必备技能。在数据科学和机器学习领域,每周都会发布许多新的算法,工具和程序,直接在你的计算机目录上安装调试这些代码、程序会让系统变得凌乱不堪。为了防止这种情况,我使用 Docker 容器来创建我的数据科学工作区将程序部署在容器中。
你可以在我的代码库中找到这个项目的 Dockerfile。以下是我安装配置 Tensorflow 目标检测的方法(按照官方安装指南):
# Install tensorFlow
RUN pip install -U tensorflow
# Install tensorflow models object detection
RUN git clone https://github.com/tensorflow/models /usr/local/lib/python3.5/dist-packages/tensorflow/models
RUN apt-get install -y protobuf-compiler python-pil python-lxml python-tk
#Set TF object detection available
ENV PYTHONPATH "$PYTHONPATH:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research/slim"
RUN cd /usr/local/lib/python3.5/dist-packages/tensorflow/models/research && protoc object_detection/protos/*.proto --python_out=.
安装 OpenCv 并编译:
# Install OpenCV
RUN git clone https://github.com/opencv/opencv.git /usr/local/src/opencv
RUN cd /usr/local/src/opencv/ && mkdir build
RUN cd /usr/local/src/opencv/build && cmake -D CMAKE_INSTALL_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/ .. && make -j4 && make install
编译镜像的时候有点长,之后就可以快速的调用
实时图像目标检测
我首先尝试将目标检测应用于我的网络摄像头。在 Dat Tran 的文章中有这部分的详细描述。难点在于将网络摄像头流发送到 docker 容器并恢复输出流以使用 X11 服务器显示它。
将视频流发送到容器
Linux 系统可以在/ dev /目录中找到摄像头设备,并可以将其作为文件进行操作。通常笔记本电脑摄像头是「0」设备。要将其数据流发送到 docker 容器,请在运行 docker 镜像时使用 device 参数:
docker run --device=/dev/video0
对于 Mac 和 Windows 用户,将网络摄像头流发送到容器的方式并不像 Linux 那样简单(尽管 Mac 基于 Unix)。我不在这里过多介绍,可以查阅相关文档,只提一下 Windows 用户的解决方案是使用 Virtual Box 启动 docker 容器。
在容器中恢复视频流
解决这个问题我花了一段时间(然而并没有完美解决)。我找到了一些使用 Docker 图形界面的资料,here。特别是介绍了将容器连接到主机的 X 服务以显示内容
你必须开启 xhost,以便容器可以通过读写 X11 unix 套接字来正常的显示内容。首先设置 X 服务器主机的权限(有一定安全隐患)让 docker 访问它:
xhost +local:docker
在完成项目后,应当恢复默认设置
xhost -local:docker
然后创建两个环境变量 XSOCK 和 XAUTH:
XSOCK=/tmp/.X11-unix
XAUTH=/tmp/.docker.xauth
第一个环境变量引用 X11 unix 套接字,第二个引用 X 验证文件配置适当的权限:
xauth nlist $DISPLAY | sed -e 's/^..../ffff/' | xauth -f $XAUTH nmerge -
最后,我们只需要更新我们的 docker run 命令。传入我们的 DISPLAY 环境变量,为 X11 Unix 套接字增加一个卷,并为 X 身份验证文件增加一个名为 XAUTHORITY 的环境变量,并让该变量指向它:
docker run -it --rm --device=/dev/video0 -e DISPLAY=$DISPLAY -v $XSOCK:$XSOCK -v $XAUTH:$XAUTH -e XAUTHORITY=$XAUTH
现在我们可以运行 docker 容器看看效果
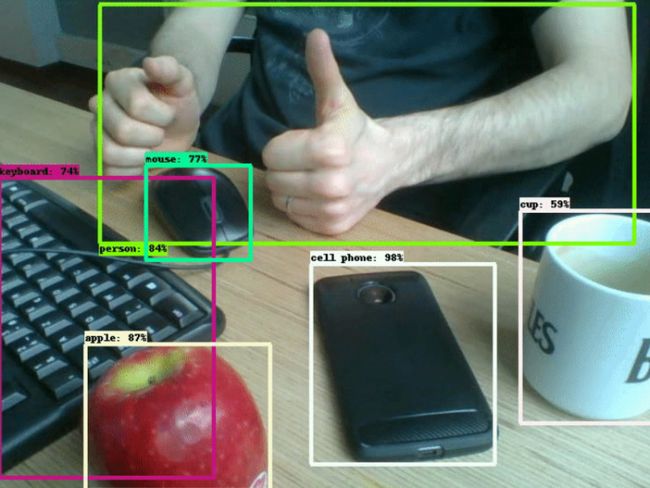
目标检测结果 (我是个害羞的人⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄)
尽管主机具有X服务配置,我仍不能完全删除代码中的bug。在OpenCV中 需要通过调用python 脚本(init-openCV.py)来进行初始化,即使用函数cv2.imshow 。用这种方法我得到了如下的错误消息:
The program 'frame' received an X Window System error.
然后,它可能调用主要python 脚本(my-object-detection.py) 并且将视频流传送到主机进行展示。我对使用第一个python 脚本去初始化X11系统的结果不是很满意,但是目前我还没有找到解决这个问题的方法。
后来补充:我最终(在偶然间)发现这个问题的解决方法,通过使用OpenCV (3.4.1) 这个稳定版本替代本地克隆的git库。因此现在在主流python 脚本之前没有必要调用 init openCV.py
视频处理
为了能通过我的摄像头实时运行目标检测API ,我使用线程和多进程处理的python 库。一个线程用于读取摄像头视频流。视频帧被放进一个队列通过工作池去处理(Tensorflow目标检测运行的地方)。
对于视频处理而言,它不可能使用线程,因为所有的视频帧都是在工作单元能将目标检测应用在队列第一帧之前被读取。当输入队列满后被读取的视频帧就会被丢失。使用大量工作单元和队列可能可以解决这个问题(伴随巨大的算力消耗)
简单队列的另外一个问题是,由于分析时间的不断变化,视频帧在输出队列中不是按照与输入队列相同的顺序。
为了增加视频处理功能,我删掉了读取帧率的线程。作为一个替代,我使用下面的代码来读取帧率。
while True:
# Check input queue is not full
if not input_q.full():
# Read frame and store in input queue
ret, frame = vs.read()
if ret:
input_q.put((int(vs.get(cv2.CAP_PROP_POS_FRAMES)),frame))
如果输入队列没满,下一帧视频从视频流中读取并且放进队列中。否则,当视频帧没有从输入队列获取时不会处理任何事情。
为了解决帧率顺序的问题,我使用了如下这种优先队列作为第二输入队列:
1. 视频帧带着对应的视频帧编号被读取并放入输入队列中(实际上是一个python 列表对象放入了序列)。
2. 然后,工作单元从输入队列中提取视频帧,处理后将它们放入第一个输出队列(依然带着它们相关的视频帧编号)。
while True:
frame = input_q.get()
frame_rgb = cv2.cvtColor(frame[1], cv2.COLOR_BGR2RGB)
output_q.put((frame[0], detect_objects(frame_rgb, sess, detection_graph)))
3. 如果输出队列不为空,视频帧带着它们相应的优先视频帧编号被抽取并放入优先队列。优先队列的大小被设置为其它队列的三倍。
# Check output queue is not empty
if not output_q.empty():
# Recover treated frame in output queue and feed priority queue
output_pq.put(output_q.get())
4. 最后,如果输出优先队列不为空,则取出有最高优先编号的视频帧(最小的优先编号)(这是标准的优先队列工作)。如果优先级编号对应于预期的编号,视频帧被加入输出视频流(并且根据需要写入),其它的视频帧则被放回优先队列。
# Check output priority queue is not empty
if not output_pq.empty():
prior, output_frame = output_pq.get()
if prior > countWriteFrame:
output_pq.put((prior, output_frame))
else:
countWriteFrame = countWriteFrame + 1
# Do something with your frame
为了停止这个过程,我检查所有的队列为空,并且所有的视频帧已经从视频流中抽取:
if((not ret) & input_q.empty() &
output_q.empty() & output_pq.empty()):
break
总结
在这篇文章中,我展示了如何使用docker来实现Tensorflow的实时目标检测项目。如上所述,docker是测试新数据科学工具最安全的方法,同时可以将解决方案打包给用户。我也将如何采用来自Dat Tran 原始的python 脚本利用多进程去进行视频处理展示给你。
谢谢你从头到尾阅读这篇文章。如上所述,这个项目有许多可以提高的地方。如果您有任何意见,请不要犹豫立刻告知我,我总是热衷得到建议或评论。