2019独角兽企业重金招聘Python工程师标准>>> ![]()
Using MRR(Multi-Range Read )
MySQL 5.6版本提供了很多性能优化的特性,其中之一就是 Multi-Range Read 多范围读(MRR) , 它的作用针对基于辅助/第二索引的查询,减少随机IO,并且将随机IO转化为顺序IO,提高查询效率。
Multi-Range Read原理
在没有MRR之前,或者没有开启MRR特性时,MySQL针对基于辅助索引的查询策略是这样的:
select non_key_column from tb where key_column=x;第一步 先根据where条件中的辅助索引获取辅助索引与主键的集合,结果集为rest。
select key_column, pk_column from tb where key_column=x order by key_column第二步 通过第一步获取的主键来获取对应的值。
for each pk_column value in rest do:
select non_key_column from tb where pk_column=val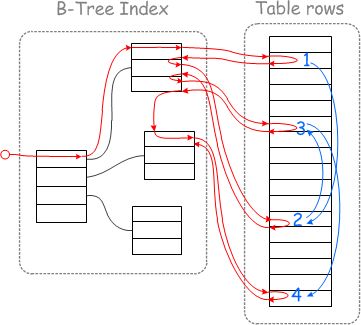
由于MySQL存储数据的方式: 辅助索引的存储顺序并非与主键的顺序一致,从图中可以看出,根据辅助索引获取的主键来访问表中的数据会导致随机的IO . 不同主键不在同一个page里面时必然导致多次IO和随机读。
在使用MRR优化特性的情况下,MySQL针对基于辅助索引的查询策略是这样的:
第一步 先根据where条件中的辅助索引获取辅助索引与主键的集合,结果集为rest
select key_column, pk_column from tb where key_column = x order by key_column第二步 将结果集rest放在buffer里面(read_rnd_buffer_size 大小直到buffer满了),然后对结果集rest按照pk_column排序,得到结果集是rest_sort
第三步 利用已经排序过的结果集,访问表中的数据,此时是顺序IO.
select non_key_column fromtb where pk_column in ( rest_sort )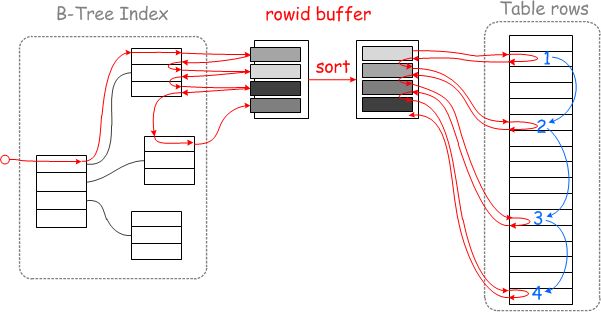
从图示MRR原理,MySQL 将根据辅助索引获取的结果集根据主键进行排序,将乱序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,多页数据记录可一次性读入或根据此次的主键范围分次读入,以减少IO操作,提高查询效率。
相关参数
我们可以通过参数 optimizer_switch 的标记来控制是否使用MRR,当设置mrr=on时,表示启用MRR优化。mrr_cost_based表示是否通过cost base的方式来启用MRR。如果选择mrr=on,mrr_cost_based=off,则表示总是开启MRR优化。
参数read_rnd_buffer_size用来控制键值缓冲区的大小。
MRR 适用于以下两种情况。
range access
ref and eq_ref access, when they are using Batched Key Access
如下示例,
在totalView列上建立索引,
alter table article add index idx_total_view (totalView);
alter table article drop index idx_total_view;
> explain select * from article where totalView between 20 and 8987
******************** 1. row *********************
id: 1
select_type: SIMPLE
table: article
type: range
possible_keys: idx_total_view
key: idx_total_view
key_len: 5
ref:
rows: 1
Extra: Using index condition; Using MRR
1 rows in set========END========