Hive SQL总结(大数据学习18)
一. HIVE启动的两种方式 :1 直接启动 2 Hive thrift服务
1 Hive 直接启动: 找寻你所安装的hive文件下的hive驱动 我的驱动是在 apps/apache-hive-1.2.1-bin/hive 下 执行驱动就可以将hive启动起来
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/hive
2 Hive thrift服务: 将hive作为一个服务器,通过另一个节点用beeline去连接 具体操作如下:
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/hiveserver2 //先作为服务器启动重新开一个mini1窗口
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
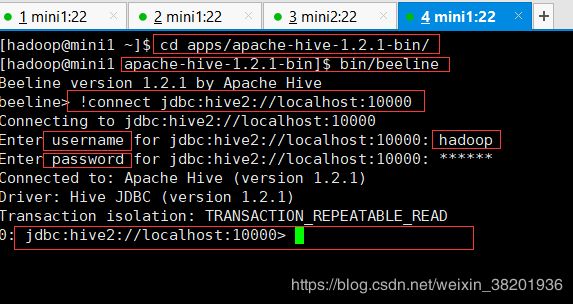
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/beeline //先启动beeline节点,然后在连接你启动的hive服务器
// 当进去beeline节点后执行下面操作
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: hadoop //该账号为你登录的服务器用户名
Enter password for jdbc:hive2://localhost:10000: ****** //密码为服务器密码
上述就是hive的两种启动方式!
二、 Hive命令
现在在第一种hive启动方式下进行如下操作:
1 查看数据库: show databases;
2 使用数据库: use +数据库名;
3 查看表: show tables;
4 创建内表: create table sust(id int,name string) row format delimited fields terminated by ','; //以逗号分隔要导入数据的信息

5 向内表导入数据:hadoop fs -put sust.tex /user/hive/warehouse/shizhan03.db/sust
导入的数据内容如下
01,liyaozhou
02,fangjingli
03,wangjun
04,liuyang
05,wangkang
06,malin
07,qianghua
08,gaoyixing
09,huanglichang
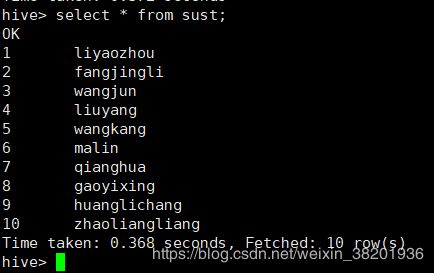
10,zhaoliangliang6: 查看内部表信息: select * from sust;
现在在第二种hive启动方式下进行如下操作:

7:创建外表:0: jdbc:hive2://localhost:10000> create external table sust1 (id int,name string) //创建表名为sust1
> row format delimited fields terminated by ',' //使用逗号进行分隔
> stored as textfile //存储形式为文本类型
> location '/SUST'; // 指定创建的表存在哪个目录下

8:向外表导入数据: 导入的数据内容和内表的一样
0: jdbc:hive2://localhost:10000> load data local inpath '/home/hadoop/sust.tex' into table sust1; //引号里面是你要导入数据的路径,后面指明你要导入的表
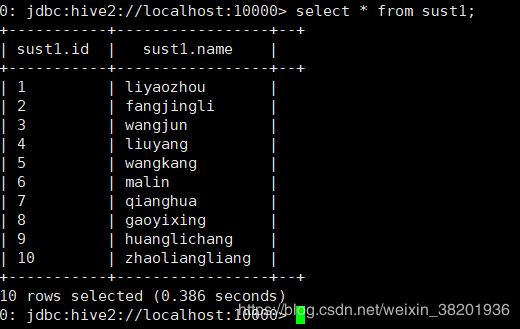
9: 查看外表信息: select * from sust;
10.外表和内表的区别:
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
11. 删内表: drop table sust; 删外表:drop table sust1;
12.创建带分区的内表:
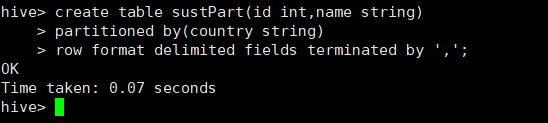
0: jdbc:hive2://localhost:10000> create table sustPart (id int,name string) //创建表名为sust1
> partitioned by(country string) // 按国家进行分区
> row format delimited fields terminated by ',' ; //使用逗号进行分隔
13.将不同国家的数据导入按国家分区的表中 先创建一个不同国家的数据
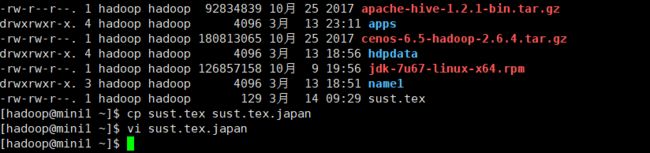
数据源如下:
01,anbei
02,cangjingkong
03,meihuizi
04,xiaotianyilang
05,taijun
06,xiaoquan
07,riben
08,bendaohuizi
09,guangdao
10,changqi先导入中国的数据:
load data local inpath '/home/hadoop/sust.tex' into table sustPart partition(country='China');
在导入另一个国家的数据:
load data local inpath '/home/hadoop/sust.tex.japan' into table sustPart partition(country='Japan');
14. 查看分区:select * from sustPart;
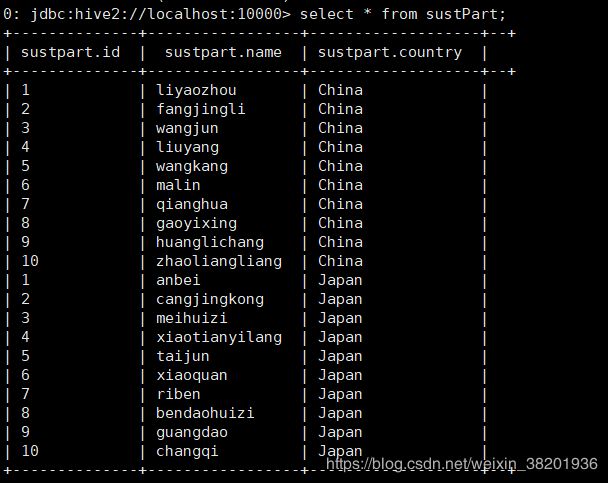
15.根据分区进行查找人名 select count(1) from sustPart where country='China' group by (name='liyaozhou');
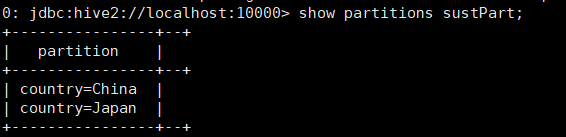
16. 展示分区: show partitions + 表名; 如 show partitions sustPartion;
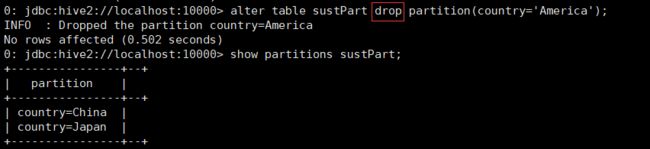
17. 增加分区:alter table sustPart add partition(country='America');

17. 减少分区:alter table sustPart drop partition(country='America');
18. 表名重命名:alter table +表名 rename to +新表名;