如何开发用于情感分析的N-gram多通道卷积神经网络-电影评论的情感分析代码实现
用于文本分类和情感分析的标准深度学习模型使用单词嵌入层和一维卷积神经网络。
可以通过使用多个并行卷积神经网络来扩展模型,该网络使用不同的内核大小读取源文档。实际上,这为文本创建了一个多通道卷积神经网络,用于读取具有不同n-gram大小(单词组)的文本。
在本教程中,您将了解如何开发一个多通道卷积神经网络,用于文本电影评论数据的情绪预测。
完成本教程后,您将了解:
- 如何准备电影评论文本数据进行建模。
- 如何在Keras中开发用于文本的多通道卷积神经网络。
- 如何评估看不见的电影评论数据的拟合模型。
教程概述
本教程分为4个部分; 他们是:
- 电影评论数据集
- 数据准备
- 开发多渠道模型
- 评估模型
Python环境
本教程假定您已安装Python 3 SciPy环境。
您必须安装Keras(2.0或更高版本)或TensorFlow或Theano后端。
本教程还假设您安装了scikit-learn,Pandas,NumPy和Matplotlib。
电影评论数据集
电影评论数据是Bo Pang和Lillian Lee在21世纪初从imdb.com网站上检索到的电影评论的集合。收集的评论作为他们自然语言处理研究的一部分提供。
评论最初于2002年发布,但更新和清理版本于2004年发布,称为“v2.0”。
该数据集包含从imdb.com托管的rec.arts.movies.reviews新闻组的档案中抽取的1,000张正面和1,000张负面电影评论。作者将此数据集称为“极性数据集”。
我们的数据包含2000年之前写的1000份正面和1000份负面评论,每个作者的评论上限为20(每位作者共312位)。我们将此语料库称为极性数据集。
- 感伤教育:基于最小削减的主观性总结的情感分析,2004。
数据已经有所清理; 例如:
- 数据集仅包含英语评论。
- 所有文本都已转换为小写。
- 标点符号周围有空格,如句点,逗号和括号。
- 文本每行分为一个句子。
该数据已用于一些相关的自然语言处理任务。对于分类,机器学习模型(例如支持向量机)对数据的性能在高70%到低80%(例如78%-82%)的范围内。
更复杂的数据准备可以看到高达86%的结果,交叉验证10倍。如果我们希望在现代方法的实验中使用这个数据集,这给了我们80年代中期的球场。
...根据下游极性分类器的选择,我们可以实现高度统计上的显着改善(从82.8%到86.4%)
- 感伤教育:基于最小削减的主观性总结的情感分析,2004。
您可以从此处下载数据集:
- 代码实现群:225215316资源共享QQ群:755786769
解压缩文件后,您将拥有一个名为“ txt_sentoken ”的目录,其中包含两个子目录,其中包含负面和正面评论的文本“ neg ”和“ pos ”。对于每个neg和pos,每个文件存储一个评论,命名约定为cv000到cv999。
接下来,我们来看看加载和准备文本数据。
数据准备
在本节中,我们将看看3件事:
- 将数据分成训练和测试集。
- 加载和清理数据以删除标点符号和数字。
- 准备所有评论并保存到文件。
分为X训练和测试装置
我们假装我们正在开发一个系统,可以预测文本电影评论的情绪是积极的还是消极的。
这意味着在开发模型之后,我们需要对新的文本评论进行预测。这将要求对这些新评论执行所有相同的数据准备,就像对模型的训练数据执行一样。
我们将通过在任何数据准备之前拆分训练和测试数据集来确保将此约束纳入我们模型的评估中。这意味着测试集中的数据中的任何知识可以帮助我们更好地准备数据(例如,使用的单词)在用于训练模型的数据的准备中是不可用的。
话虽如此,我们将使用最近100个正面评论和最后100个负面评论作为测试集(100条评论),其余1,800条评论作为训练数据集。
这是90%的列车,10%的数据分割。
通过使用评论的文件名可以轻松实现拆分,其中评论为000至899的评论用于培训数据,而评论为900以上的评论用于测试。
装载和清洁评论
文本数据已经非常干净; 没有太多准备工作。
不会因细节问题而陷入困境,我们将按以下方式准备数据:
- 在白色空间的分裂标记。
- 从单词中删除所有标点符号。
- 删除所有不完全由字母字符组成的单词。
- 删除所有已知停用词的单词。
- 删除长度<= 1个字符的所有单词。
我们可以将所有这些步骤放入一个名为clean_doc()的函数中,该函数将从文件加载的原始文本作为参数,并返回已清理的标记列表。我们还可以定义一个函数load_doc(),它从文件中加载文档,以便与clean_doc()函数一起使用。下面列出了清理第一次正面评价的示例。
12345678910111213141516171819202122232425262728293031323334from nltk . corpus import stopwordsimport string# load doc into memorydef load_doc ( filename ) :# open the file as read onlyfile = open ( filename , 'r' )# read all texttext = file . read ( )# close the filefile . close ( )return text# turn a doc into clean tokensdef clean_doc ( doc ) :# split into tokens by white spacetokens = doc . split ( )# remove punctuation from each tokentable = str . maketrans ( '' , '' , string . punctuation )tokens = [ w . translate ( table ) for w in tokens ]# remove remaining tokens that are not alphabetictokens = [ word for word in tokens if word . isalpha ( ) ]# filter out stop wordsstop_words = set ( stopwords . words ( 'english' ) )tokens = [ w for w in tokens if not w in stop_words ]# filter out short tokenstokens = [ word for word in tokens if len ( word ) > 1 ]return tokens# load the documentfilename = 'txt_sentoken/pos/cv000_29590.txt'text = load_doc ( filename )tokens = clean_doc ( text )print ( tokens )12345678910111213141516171819202122232425262728293031323334from nltk . corpus import stopwordsimport string# load doc into memorydef load_doc ( filename ) :# open the file as read onlyfile = open ( filename , 'r' )# read all texttext = file . read ( )# close the filefile . close ( )return text# turn a doc into clean tokensdef clean_doc ( doc ) :# split into tokens by white spacetokens = doc . split ( )# remove punctuation from each tokentable = str . maketrans ( '' , '' , string . punctuation )tokens = [ w . translate ( table ) for w in tokens ]# remove remaining tokens that are not alphabetictokens = [ word for word in tokens if word . isalpha ( ) ]# filter out stop wordsstop_words = set ( stopwords . words ( 'english' ) )tokens = [ w for w in tokens if not w in stop_words ]# filter out short tokenstokens = [ word for word in tokens if len ( word ) > 1 ]return tokens# load the documentfilename = 'txt_sentoken/pos/cv000_29590.txt'text = load_doc ( filename )tokens = clean_doc ( text )print ( tokens )运行该示例加载并清除一个电影评论。
打印清洁评论中的标记以供审阅。
12...'creepy', 'place', 'even', 'acting', 'hell', 'solid', 'dreamy', 'depp', 'turning', 'typically', 'strong', 'performance', 'deftly', 'handling', 'british', 'accent', 'ians', 'holm', 'joe', 'goulds', 'secret', 'richardson', 'dalmatians', 'log', 'great', 'supporting', 'roles', 'big', 'surprise', 'graham', 'cringed', 'first', 'time', 'opened', 'mouth', 'imagining', 'attempt', 'irish', 'accent', 'actually', 'wasnt', 'half', 'bad', 'film', 'however', 'good', 'strong', 'violencegore', 'sexuality', 'language', 'drug', 'content']清除所有评论并保存
我们现在可以使用该功能来清理评论并将其应用于所有评论。
为此,我们将在下面开发一个名为process_docs()的新函数,它将遍历目录中的所有评论,清理它们并将它们作为列表返回。
我们还将为函数添加一个参数,以指示函数是处理序列还是测试评论,这样可以过滤文件名(如上所述),并且只清理和返回所请求的那些列车或测试评论。
完整功能如下所列。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from
nltk
.
corpus
import
stopwords
import
string
# load doc into memory
def
load_doc
(
filename
)
:
# open the file as read only
file
=
open
(
filename
,
'r'
)
# read all text
text
=
file
.
read
(
)
# close the file
file
.
close
(
)
return
text
# turn a doc into clean tokens
def
clean_doc
(
doc
)
:
# split into tokens by white space
tokens
=
doc
.
split
(
)
# remove punctuation from each token
table
=
str
.
maketrans
(
''
,
''
,
string
.
punctuation
)
tokens
=
[
w
.
translate
(
table
)
for
w
in
tokens
]
# remove remaining tokens that are not alphabetic
tokens
=
[
word
for
word
in
tokens
if
word
.
isalpha
(
)
]
# filter out stop words
stop_words
=
set
(
stopwords
.
words
(
'english'
)
)
tokens
=
[
w
for
w
in
tokens
if
not
w
in
stop_words
]
# filter out short tokens
tokens
=
[
word
for
word
in
tokens
if
len
(
word
)
>
1
]
return
tokens
# load the document
filename
=
'txt_sentoken/pos/cv000_29590.txt'
text
=
load_doc
(
filename
)
tokens
=
clean_doc
(
text
)
print
(
tokens
)
|
# load all docs in a directory def process_docs(directory, is_trian): documents = list() # walk through all files in the folder for filename in listdir(directory): # skip any reviews in the test set if is_trian and filename.startswith('cv9'): continue if not is_trian and not filename.startswith('cv9'): continue # create the full path of the file to open path = directory + '/' + filename # load the doc doc = load_doc(path) # clean doc tokens = clean_doc(doc) # add to list documents.append(tokens) return documents
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# load all docs in a directory
def
process_docs
(
directory
,
is_trian
)
:
documents
=
list
(
)
# walk through all files in the folder
for
filename
in
listdir
(
directory
)
:
# skip any reviews in the test set
if
is_trian
and
filename
.
startswith
(
'cv9'
)
:
continue
if
not
is_trian
and
not
filename
.
startswith
(
'cv9'
)
:
continue
# create the full path of the file to open
path
=
directory
+
'/'
+
filename
# load the doc
doc
=
load_doc
(
path
)
# clean doc
tokens
=
clean_doc
(
doc
)
# add to list
documents
.
append
(
tokens
)
return
documents
|
我们可以将此功能称为负面培训评论,如下所示:
|
1
|
negative_docs
=
process_docs
(
'txt_sentoken/neg'
,
True
)
|
接下来,我们需要列车和测试文件的标签。我们知道我们有900份培训文件和100份测试文件。我们可以使用Python列表理解为列车和测试集的负(0)和正(1)评论创建标签。
|
1
2
|
trainy
=
[
0
for
_
in
range
(
900
)
]
+
[
1
for
_
in
range
(
900
)
]
testY
=
[
0
for
_
in
range
(
100
)
]
+
[
1
for
_
in
range
(
100
)
]
|
最后,我们希望将准备好的训练和测试集保存到文件中,以便我们以后可以加载它们进行建模和模型评估。
下面命名为save_dataset()的函数将使用pickle API将给定的准备数据集(X和y元素)保存到文件中。
|
1
2
3
4
|
# save a dataset to file
def
save_dataset
(
dataset
,
filename
)
:
dump
(
dataset
,
open
(
filename
,
'wb'
)
)
print
(
'Saved: %s'
%
filename
)
|
完整的例子
我们可以将所有这些数据准备步骤结合在一起。
下面列出了完整的示例。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
from
string
import
punctuation
from
os
import
listdir
from
nltk
.
corpus
import
stopwords
from
pickle
import
dump
# load doc into memory
def
load_doc
(
filename
)
:
# open the file as read only
file
=
open
(
filename
,
'r'
)
# read all text
text
=
file
.
read
(
)
# close the file
file
.
close
(
)
return
text
# turn a doc into clean tokens
def
clean_doc
(
doc
)
:
# split into tokens by white space
tokens
=
doc
.
split
(
)
# remove punctuation from each token
table
=
str
.
maketrans
(
''
,
''
,
punctuation
)
tokens
=
[
w
.
translate
(
table
)
for
w
in
tokens
]
# remove remaining tokens that are not alphabetic
tokens
=
[
word
for
word
in
tokens
if
word
.
isalpha
(
)
]
# filter out stop words
stop_words
=
set
(
stopwords
.
words
(
'english'
)
)
tokens
=
[
w
for
w
in
tokens
if
not
w
in
stop_words
]
# filter out short tokens
tokens
=
[
word
for
word
in
tokens
if
len
(
word
)
>
1
]
tokens
=
' '
.
join
(
tokens
)
return
tokens
# load all docs in a directory
def
process_docs
(
directory
,
is_trian
)
:
documents
=
list
(
)
# walk through all files in the folder
for
filename
in
listdir
(
directory
)
:
# skip any reviews in the test set
if
is_trian
and
filename
.
startswith
(
'cv9'
)
:
continue
if
not
is_trian
and
not
filename
.
startswith
(
'cv9'
)
:
continue
# create the full path of the file to open
path
=
directory
+
'/'
+
filename
# load the doc
doc
=
load_doc
(
path
)
# clean doc
tokens
=
clean_doc
(
doc
)
# add to list
documents
.
append
(
tokens
)
return
documents
# save a dataset to file
def
save_dataset
(
dataset
,
filename
)
:
dump
(
dataset
,
open
(
filename
,
'wb'
)
)
print
(
'Saved: %s'
%
filename
)
# load all training reviews
negative_docs
=
process_docs
(
'txt_sentoken/neg'
,
True
)
positive_docs
=
process_docs
(
'txt_sentoken/pos'
,
True
)
save_dataset
(
[
trainX
,
trainy
]
,
'train.pkl'
)
# load all test reviews
negative_docs
=
process_docs
(
'txt_sentoken/neg'
,
False
)
positive_docs
=
process_docs
(
'txt_sentoken/pos'
,
False
)
testX
=
negative_docs
+
positive_docs
testY
=
[
0
for
_
in
range
(
100
)
]
+
[
1
for
_
in
range
(
100
)
]
save_dataset
(
[
testX
,
testY
]
,
'test.pkl'
)
|
运行该示例分别清除文本电影审阅文档,创建标签,并分别为train.pkl和test.pkl保存列车和测试数据集的准备数据。
现在我们准备开发我们的模型了。
开发多渠道模型
在本节中,我们将开发一个用于情感分析预测问题的多通道卷积神经网络。
本节分为3部分:
- 编码数据
- 定义模型。
- 完整的例子。
编码数据
第一步是加载已清理的训练数据集。
可以调用以下名为load_dataset()的函数来加载pickle训练数据集。
|
1
2
3
4
5
|
# load a clean dataset
def
load_dataset
(
filename
)
:
return
load
(
open
(
filename
,
'rb'
)
)
trainLines
,
trainLabels
=
load_dataset
(
'train.pkl'
)
|
接下来,我们必须在训练数据集上安装Keras Tokenizer。我们将使用此标记器来定义嵌入层的词汇表,并将审阅文档编码为整数。
下面的函数create_tokenizer()将创建一个给定文档列表的Tokenizer。
|
1
2
3
4
5
|
# fit a tokenizer
def
create_tokenizer
(
lines
)
:
tokenizer
=
Tokenizer
(
)
tokenizer
.
fit_on_texts
(
lines
)
return
tokenizer
|
我们还需要知道输入序列的最大长度作为模型的输入并将所有序列填充到固定长度。
下面的函数max_length()将计算训练数据集中所有评论的最大长度(单词数)。
|
1
2
3
|
# calculate the maximum document length
def
max_length
(
lines
)
:
return
max
(
[
len
(
s
.
split
(
)
)
for
s
in
lines
]
)
|
我们还需要知道嵌入层的词汇量大小。
这可以从准备好的Tokenizer计算,如下:
|
1
2
|
# calculate vocabulary size
vocab_size
=
len
(
tokenizer
.
word_index
)
+
1
|
最后,我们可以整数编码并填充干净的电影评论文本。
下面名为encode_text()的函数将编码和填充文本数据到最大查看长度。
|
1
2
3
4
5
6
7
|
# encode a list of lines
def
encode_text
(
tokenizer
,
lines
,
length
)
:
# integer encode
encoded
=
tokenizer
.
texts_to_sequences
(
lines
)
# pad encoded sequences
padded
=
pad_sequences
(
encoded
,
maxlen
=
length
,
padding
=
'post'
)
return
padded
|
定义模型
用于文档分类的标准模型是使用嵌入层作为输入,接着是一维卷积神经网络,池化层,然后是预测输出层。
卷积层中的内核大小定义了卷积在输入文本文档中传递时要考虑的单词数,从而提供分组参数。
用于文档分类的多通道卷积神经网络涉及使用具有不同大小的内核的标准模型的多个版本。这允许一次以不同的分辨率或不同的n-gram(单词组)处理文档,同时模型学习如何最好地整合这些解释。
Yoon Kim在其2014年题为“ 用于句子分类的卷积神经网络 ”的论文中首次描述了这种方法。
在本文中,Kim尝试了静态和动态(更新)嵌入层,我们可以简化方法,而只关注使用不同的内核大小。
使用Kim的论文中的图表可以最好地理解这种方法:

用于文本的多通道卷积神经网络的描述。
摘自“用于句子分类的卷积神经网络”。
在Keras中,可以使用功能API定义多输入模型。
我们将定义一个带有三个输入通道的模型,用于处理4克,6克和8克的电影评论文本。
每个频道由以下元素组成:
- 输入层,用于定义输入序列的长度。
- 嵌入图层设置为词汇表的大小和100维实值表示。
- 一维卷积层,具有32个滤波器,内核大小设置为一次读取的字数。
- Max Pooling图层用于合并卷积图层的输出。
- 展平图层以将三维输出减少为二维以进行连接。
三个通道的输出连接成一个矢量,并由Dense层和输出层处理。
下面的函数定义并返回模型。作为定义模型的一部分,将打印已定义模型的摘要,并创建模型图的图并将其保存到文件中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# define the model
def
define_model
(
length
,
vocab_size
)
:
# channel 1
inputs1
=
Input
(
shape
=
(
length
,
)
)
embedding1
=
Embedding
(
vocab_size
,
100
)
(
inputs1
)
conv1
=
Conv1D
(
filters
=
32
,
kernel_size
=
4
,
activation
=
'relu'
)
(
embedding1
)
drop1
=
Dropout
(
0.5
)
(
conv1
)
pool1
=
MaxPooling1D
(
pool_size
=
2
)
(
drop1
)
flat1
=
Flatten
(
)
(
pool1
)
# channel 2
inputs2
=
Input
(
shape
=
(
length
,
)
)
embedding2
=
Embedding
(
vocab_size
,
100
)
(
inputs2
)
conv2
=
Conv1D
(
filters
=
32
,
kernel_size
=
6
,
activation
=
'relu'
)
(
embedding2
)
drop2
=
Dropout
(
0.5
)
(
conv2
)
pool2
=
MaxPooling1D
(
pool_size
=
2
)
(
drop2
)
flat2
=
Flatten
(
)
(
pool2
)
# channel 3
inputs3
=
Input
(
shape
=
(
length
,
)
)
embedding3
=
Embedding
(
vocab_size
,
100
)
(
inputs3
)
conv3
=
Conv1D
(
filters
=
32
,
kernel_size
=
8
,
activation
=
'relu'
)
(
embedding3
)
drop3
=
Dropout
(
0.5
)
(
conv3
)
pool3
=
MaxPooling1D
(
pool_size
=
2
)
(
drop3
)
flat3
=
Flatten
(
)
(
pool3
)
# merge
merged
=
concatenate
(
[
flat1
,
flat2
,
flat3
]
)
# interpretation
dense1
=
Dense
(
10
,
activation
=
'relu'
)
(
merged
)
outputs
=
Dense
(
1
,
activation
=
'sigmoid'
)
(
dense1
)
model
=
Model
(
inputs
=
[
inputs1
,
inputs2
,
inputs3
]
,
outputs
=
outputs
)
# compile
model
.
compile
(
loss
=
'binary_crossentropy'
,
optimizer
=
'adam'
,
metrics
=
[
'accuracy'
]
)
# summarize
print
(
model
.
summary
(
)
)
plot_model
(
model
,
show_shapes
=
True
,
to_file
=
'multichannel.png'
)
return
model
|
首先运行该示例将打印准备好的训练数据集的摘要。
|
1
2
3
|
Max document length: 1380
Vocabulary size: 44277
(1800, 1380)
|
接下来,打印已定义模型的摘要。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_1 (InputLayer) (None, 1380) 0
____________________________________________________________________________________________________
input_2 (InputLayer) (None, 1380) 0
____________________________________________________________________________________________________
input_3 (InputLayer) (None, 1380) 0
____________________________________________________________________________________________________
embedding_1 (Embedding) (None, 1380, 100) 4427700 input_1[0][0]
____________________________________________________________________________________________________
embedding_2 (Embedding) (None, 1380, 100) 4427700 input_2[0][0]
____________________________________________________________________________________________________
embedding_3 (Embedding) (None, 1380, 100) 4427700 input_3[0][0]
____________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 1377, 32) 12832 embedding_1[0][0]
____________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 1375, 32) 19232 embedding_2[0][0]
____________________________________________________________________________________________________
conv1d_3 (Conv1D) (None, 1373, 32) 25632 embedding_3[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 1377, 32) 0 conv1d_1[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 1375, 32) 0 conv1d_2[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 1373, 32) 0 conv1d_3[0][0]
____________________________________________________________________________________________________
max_pooling1d_1 (MaxPooling1D) (None, 688, 32) 0 dropout_1[0][0]
____________________________________________________________________________________________________
max_pooling1d_2 (MaxPooling1D) (None, 687, 32) 0 dropout_2[0][0]
____________________________________________________________________________________________________
max_pooling1d_3 (MaxPooling1D) (None, 686, 32) 0 dropout_3[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 22016) 0 max_pooling1d_1[0][0]
____________________________________________________________________________________________________
flatten_2 (Flatten) (None, 21984) 0 max_pooling1d_2[0][0]
____________________________________________________________________________________________________
flatten_3 (Flatten) (None, 21952) 0 max_pooling1d_3[0][0]
____________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 65952) 0 flatten_1[0][0]
flatten_2[0][0]
flatten_3[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 10) 659530 concatenate_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 11 dense_1[0][0]
====================================================================================================
Total params: 14,000,337
Trainable params: 14,000,337
Non-trainable params: 0
____________________________________________________________________________________________________
|
该模型相对较快,并且在训练数据集上显示出良好的技能。
|
1
2
3
4
5
6
7
8
9
10
11
|
...
Epoch 6/10
1800/1800 [==============================] - 30s - loss: 9.9093e-04 - acc: 1.0000
Epoch 7/10
1800/1800 [==============================] - 29s - loss: 5.1899e-04 - acc: 1.0000
Epoch 8/10
1800/1800 [==============================] - 28s - loss: 3.7958e-04 - acc: 1.0000
Epoch 9/10
1800/1800 [==============================] - 29s - loss: 3.0534e-04 - acc: 1.0000
Epoch 10/10
1800/1800 [==============================] - 29s - loss: 2.6234e-04 - acc: 1.0000
|
已定义模型的图表将保存到文件中,清楚地显示模型的三个输入通道。
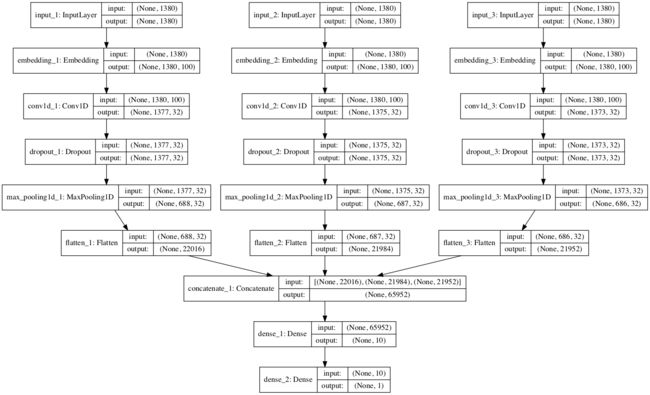
文本多通道卷积神经网络图
该模型适用于许多时期并保存到文件model.h5中以供以后评估。
评估模型
在本节中,我们可以通过预测未见测试数据集中所有评论的情绪来评估拟合模型。
使用上一节中开发的数据加载函数,我们可以加载和编码训练和测试数据集。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# load datasets
trainLines
,
trainLabels
=
load_dataset
(
'train.pkl'
)
testLines
,
testLabels
=
load_dataset
(
'test.pkl'
)
# create tokenizer
tokenizer
=
create_tokenizer
(
trainLines
)
# calculate max document length
length
=
max_length
(
trainLines
)
# calculate vocabulary size
vocab_size
=
len
(
tokenizer
.
word_index
)
+
1
print
(
'Max document length: %d'
%
length
)
print
(
'Vocabulary size: %d'
%
vocab_size
)
# encode data
trainX
=
encode_text
(
tokenizer
,
trainLines
,
length
)
testX
=
encode_text
(
tokenizer
,
testLines
,
length
)
print
(
trainX
.
shape
,
testX
.
shape
)
|
我们可以加载保存的模型并在训练和测试数据集上进行评估。
下面列出了完整的示例。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
from
pickle
import
load
from
numpy
import
array
from
keras
.
preprocessing
.
text
import
Tokenizer
from
keras
.
preprocessing
.
sequence
import
pad_sequences
from
keras
.
models
import
load_model
# load a clean dataset
def
load_dataset
(
filename
)
:
return
load
(
open
(
filename
,
'rb'
)
)
# fit a tokenizer
def
create_tokenizer
(
lines
)
:
tokenizer
=
Tokenizer
(
)
tokenizer
.
fit_on_texts
(
lines
)
return
tokenizer
# calculate the maximum document length
def
max_length
(
lines
)
:
return
max
(
[
len
(
s
.
split
(
)
)
for
s
in
lines
]
)
# encode a list of lines
def
encode_text
(
tokenizer
,
lines
,
length
)
:
# integer encode
encoded
=
tokenizer
.
texts_to_sequences
(
lines
)
# pad encoded sequences
padded
=
pad_sequences
(
encoded
,
maxlen
=
length
,
padding
=
'post'
)
return
padded
# load datasets
trainLines
,
trainLabels
=
load_dataset
(
'train.pkl'
)
testLines
,
testLabels
=
load_dataset
(
'test.pkl'
)
# calculate max document length
length
=
max_length
(
trainLines
)
# calculate vocabulary size
vocab_size
=
len
(
tokenizer
.
word_index
)
+
1
print
(
'Max document length: %d'
%
length
)
print
(
'Vocabulary size: %d'
%
vocab_size
)
# encode data
trainX
=
encode_text
(
tokenizer
,
trainLines
,
length
)
testX
=
encode_text
(
tokenizer
,
testLines
,
length
)
print
(
trainX
.
shape
,
testX
.
shape
)
# load the model
model
=
load_model
(
'model.h5'
)
# evaluate model on training dataset
loss
,
acc
=
model
.
evaluate
(
[
trainX
,
trainX
,
trainX
]
,
array
(
trainLabels
)
,
verbose
=
0
)
print
(
'Train Accuracy: %f'
%
(
acc*
100
)
)
# evaluate model on test dataset dataset
loss
,
acc
=
model
.
evaluate
(
[
testX
,
testX
,
testX
]
,
array
(
testLabels
)
,
verbose
=
0
)
print
(
'Test Accuracy: %f'
%
(
acc*
100
)
)
|
运行该示例将在训练和测试数据集上打印模型的技能。
|
1
2
3
4
5
6
|
Max document length: 1380
Vocabulary size: 44277
(1800, 1380) (200, 1380)
Train Accuracy: 100.000000
Test Accuracy: 87.500000
|
我们可以看到,正如预期的那样,训练数据集的技能非常出色,这里的准确率为100%。
我们还可以看到模型对看不见的测试数据集的技能也非常令人印象深刻,达到87.5%,高于2014年论文中报告的模型的技能(尽管不是直接的苹果对苹果比较)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from
nltk
.
corpus
import
stopwords
import
string
# load doc into memory
def
load_doc
(
filename
)
:
# open the file as read only
file
=
open
(
filename
,
'r'
)
# read all text
text
=
file
.
read
(
)
# close the file
file
.
close
(
)
return
text
# turn a doc into clean tokens
def
clean_doc
(
doc
)
:
# split into tokens by white space
tokens
=
doc
.
split
(
)
# remove punctuation from each token
table
=
str
.
maketrans
(
''
,
''
,
string
.
punctuation
)
tokens
=
[
w
.
translate
(
table
)
for
w
in
tokens
]
# remove remaining tokens that are not alphabetic
tokens
=
[
word
for
word
in
tokens
if
word
.
isalpha
(
)
]
# filter out stop words
stop_words
=
set
(
stopwords
.
words
(
'english'
)
)
tokens
=
[
w
for
w
in
tokens
if
not
w
in
stop_words
]
# filter out short tokens
tokens
=
[
word
for
word
in
tokens
if
len
(
word
)
>
1
]
return
tokens
# load the document
filename
=
'txt_sentoken/pos/cv000_29590.txt'
text
=
load_doc
(
filename
)
tokens
=
clean_doc
(
text
)
print
(
tokens
)
|