hadoop完全分布式搭建HA(高可用)
首先创建5台虚拟机(最少三台),并且做好部署规划
ip地址 |
主机名 |
安装软件 |
进程 |
192.168.xx.120 |
master |
jdk,hadoop,zookeeper |
namenode,ZKFC,Resourcemanager |
192.168.xx.121 |
master2 |
jdk,hadoop,zookeeper |
namenode,ZKFC,Resourcemanager |
192.168.xx.122 |
slave1 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
192.168.xx.123 |
slave2 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
192.168.xx.124 |
slave3 |
jdk,hadoop,zookeeper |
natanode,nodemanager,zookeeper,Journalnode, |
一、首先设置防火墙防火墙
立即关闭防火墙service iptables stop

设置防火墙开机不启动 chkconfig iptables off
![]()
设置 selinux 将SELINUX 改为disabled

二、编辑主机名映射
vi/etc/hosts

下载 ssh包获取scp命令
yuminstall openssh-clients

将hosts远程拷贝至后面四台机器
scp /etc/hostsmaster2:/etc/hosts

三、设置五台机器时间同步
最小化安装没有ntpdate这个软件,首先用yum命令下载
yum –y installntp

设置master 与指定时间服务器同步
ntpdate cn.pool.ntp.org设置后面4台机器与master同步
修改master ntp配置文件
vi /etc/ntp.conf
讲restrict 上的网段改为自己的网段
注释server 服务器
在最下面添加两行server 和fudge内容
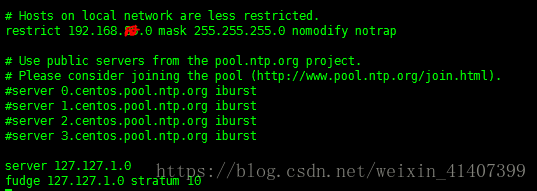
启动ntpd ,并设置为开机启动
关闭后面几台ntpd,并设置为开机不启动

同步master时间服务器
ntpdate master
四、创建普通用户
adduser hadoop
passwd hadoop 设置密码

五、SSH免密登录
切换到普通用户
在五台机器上都输入ssh-keygen –t rsa,然后一直按回车

将秘钥拷贝到五台机器上
ssh-copy-id master
ssh-copy-id master2
ssh-copy-id slave1

ssh-copy-id slave2

ssh-copy-id slave3

测试能否免密登录,设置成功!
![]()
在其他四台机器上重复以上操作
六、安装jdk
我这里是最小化安装不需要检查系统自己看装的jdk,如果不是需要卸载
通过下面两行命令查找卸载
rpm –qa |grep jdk
rpm –e –nodep
修改/opt/文件夹用户
chown –R hadoop:hadoop /opt/
创建 /opt/software文件夹,这个文件夹用来存放压缩包, 创建/opt/modules这个文件用来存放解压的软件
上传jdk到software

解压jdk到modules
![]()
配置环境变变量,切换到root用户vi /etc/profile 也可以在普通用户下修改vi ~/.bash_profile,在最后添加

保存退出,输入 source /etc/profile ,然后输入java -version验证版本

将java scp至其他几台机器
![]()
将配置文件scp至其他几台机器
![]()
七、进入slave1主机,安装配置zookeeper
上传zookeeper到software文件夹,并解压到modules
修改zookeeper配置文件
![]()
![]()
修改dataDir 路径,增加server配置信息
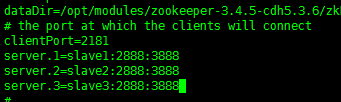
创建zkData文件夹并创建myid文件,在slave1输入1
scp zookeeper文件夹到slave2和slave3下
修改slave2和slave3 的myid文件
启动zookeeper,并验证状态

启动 bin/zkCli.sh,配置完成!

八、安装配置hadoop
上传hadoop到software文件夹,并解压到modules
![]()
配置hadoop环境变量
root vi /etc/profile, 记得source /etc/profile

修改hadoop 配置文件
修改 etc/hadoop 下的环境变量文件增加java环境变量
hadoop-env.sh mapred-env.sh yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.7.0_79
修改core-site.xml文件
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/opt/modules/App/hadoop-2.5.0/data/tmp
hadoop.http.staticuser.user
hadoop
ha.zookeeper.quorum
slave1:2181,slave2:2181,slave3:2181
修改hdfs-site.xml文件
dfs.replication
3
dfs.permissions.enabled
false
dfs.nameservices
ns1
dfs.blocksize
134217728
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
master:8020
dfs.namenode.http-address.ns1.nn1
master:50070
dfs.namenode.rpc-address.ns1.nn2
master2:8020
dfs.namenode.http-address.ns1.nn2
master2:50070
dfs.namenode.shared.edits.dir
qjournal://slave1:8485;slave2:8485;slave3:8485/ns1
dfs.journalnode.edits.dir
/opt/modules/hadoop-2.5.0-cdh5.3.6/data/journal
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.ha.automatic-failover.enabled
true
修改mapred-site.xml.template名称为mapred-site.xml并修改
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
配置 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmcluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
master
yarn.resourcemanager.hostname.rm2
master2
yarn.resourcemanager.zk-address
slave1:2181,slave2:2181,slave3:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
配置slaves

scp hadoop到其他四台机器,拷贝之前删除share/doc文件
![]()
分别在master和master2的yarn-site.xml上添加
yarn.resourcemanager.ha.id
rm1
yarn.resourcemanager.ha.id
rm2

启动zookeeper

启动journalnode sbin/hadoop-deamon.sh startjournalnode
格式化master namenode bin/hdfs namenode –format
启动 master namenode sbin/hadoop-deamon.sh startnamenode
在master2上同步master namenode元数据 bin/hdfs namenode -bootstrapStandby
启动master2 namenode sbin/hadoop-deamon.sh startnamenode
此时进入 50070 web页面,两个namenode都是standby状态,这是可以先强制手动是其中一个节点变为active bin/hdfs haadmin –transitionToActive–forcemanual

此时master变为active

手动故障转移已经完成,接下来配置自动故障转移
先把整个集群关闭,zookeeper不关,输入bin/hdfs zkfc –formatZK,格式化ZKFC
在slave1上登录zookeeper
![]()
输入ls / ,发现多了一个hadoop-ha节点,这是配置应该没有问题

启动集群, 在master 输入 sbin/start-dfs.sh

此时一个节点stanby 一个节点active


现在kill掉master namenode进程, 刷新master页面

master自动切换为active,配置成功!
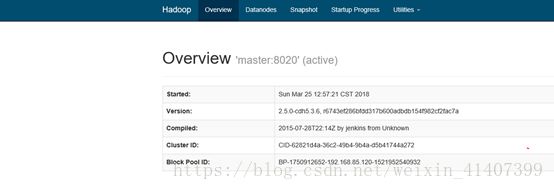
启动yarn,测试resourcemanager ha ,master1输入 sbin/start-yarn.sh

master2输入 sbin/yarn-daemaon.sh start resourcemanager
在web 端输入master2:8088自动跳转
![]()
Kill master rm进程

master2:8088 active

wordcount程序测试,在本地创建一个测试文件,并上传到hdfs上


![]()

查看输出文件 hadoop fs –cat /output1/part*,运行成功

关闭active rm ,再次运行wordcount


关闭active namenode,查看文件

查看成功,rm nn HA配置成功!