五分钟看懂XLNet基本思想以及为什么它优于BERT
https://www.toutiao.com/a6707592689329635843/
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
下图给出了XLNet的一些对比结果。

本文主要介绍XLNet模型的基本思想,并与BERT做了简单的对比。原文发表在Medium上。我们做了翻译,并对其中一部分难以理解的地方做了一点修改。
什么是XLNet?
首先,XLNet是一个与BERT有点像的模型,并非完全的一个新东西。 但XLNet是一个非常有前途的模型。简单来说,XLNet是一种通用的自回归预训练方法。
那么什么是自回归(AR)语言模型?
AR语言模型是一种使用情景信息(context,也可以说是上下文)来预测下一个词的模型。注意,情景信息通常有两个方向,一个是前向的,一个是后向的。以一句话为例:
“我 爱 吃 大 苹果”
假如这里的目标是“吃”,那么它的前向情景就是“我”和“爱”。后向就是“大”和“苹果”。


前段时间的GPT和GPT-2都是AR语言模型。
AR语言模型非常适合生成式NLP任务。但是AR模型有一个非常大的缺点,它只能利用前向情景的信息,这显然不符合实际。那么XLNet的提出就是希望把后向信息也利用起来。
XLNet和BERT有什么区别?
与AR语言模型不同,BERT被归类为自动编码器(AE)语言模型。
AE语言模型旨在从corrupted的输入中重建原始数据。

corrupted的输入意味着我们使用[MASK]将原始token替换掉。 目标是预测到获得原始句子。
AE语言模型的优点是它可以看到前向和后向的上下文。
但AE语言模型也有其缺点。 它在预训练中使用[MASK],但在微调时间内,实际数据中不存在这种人工符号,导致预训练 - 微调差异。 [MASK]的另一个缺点是它假设预测的(屏蔽的)token独立于其他未屏蔽的token。 但我们知道在真正的自然语言中并非如此。
作者想要强调的是,XLNet提议是一种让AR语言模型从双向上下文中学习的新方法,以避免MASK方法在AE语言模型中带来的缺点。
XLNet如何工作?
AR语言模型只能向前或向后使用上下文,那么如何让它从双向上下文中学习呢?
语言模型包括两个阶段,即预训练阶段和微调阶段。 XLNet专注于预训练阶段。 在预训练阶段,它提出了一个名为置换语言建模的新目标。 我们可以从这个名称知道基本思想,它使用的是排列的思想。

这里我们举一个例子来解释。假设有一个序列,其顺序为[x1,x2,x3,x4]。 这种序列的所有排列如下。

因此对于这4个token的(N)句子,有24(N!)种排列。
场景是我们想要预测x3。 因此在24个排列中有4个模式,x3在第1个位置,第2个位置,第3个位置,第4个位置。
[x3, xx, xx, xx]
[xx, x3, xx, xx]
[xx, xx, x3, xx]
[xx, xx, xx, x3]
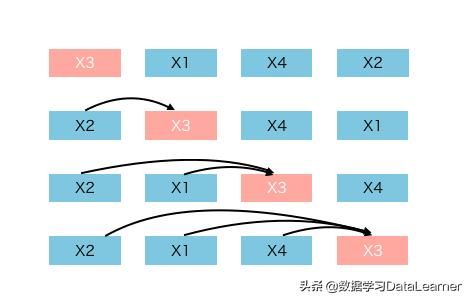
从这里可以看到,x3的前向情景突然间多了很多可能,几乎所有的前后文情景都在各种排列中出现了。这下就能克服AR只能利用前向情景信息的缺点了。简直不要太机智了。
当然,实际实现比上面的解释复杂得多,在此不再赘述。 但是你应该得到关于XLNet的最基本和最重要的想法。
来自XLNet的启示
就像BERT将MASK方法带给公众一样,XLNet表明排列方法是语言模型目标的一个很好的选择。 可以预见,未来有更多的工作可以探索语言模型的目标。
原文地址:https://towardsdatascience.com/what-is-xlnet-and-why-it-outperforms-bert-8d8fce710335