一、数据库:mysql 数据库
一、SQL,不区分大小写
在数据库中进行操作的脚本,称为sql,结构化查询语言,当前关系型数据库都支持使用sql语言进行操作,也就是说可以通过 sql 操作 oracle,sql server,mysql,sqlite 等等所有的关系型的数据库。
sql语句主要分为:
1 DQL:数据查询语言,用于对数据进行查询,如 select
2 DML:数据操作语言,对数据进行增、删、查、改,如 insert 、update 、delete
3 TPL:事物处理语言,对事物进行处理,包括 begin transaction 、commit 、rollback
4 DCL:数据控制语言,进行授权与权限回收,如 grant 、revoke
5 DDL:数据定义语言,进行数据库、表的管理,如 creat 、drop
6 CCL:指针控制语言,通过控制指针完成表的操作,如 declare cursor
对于web程序员来说,重点是数据的增删查改,必须熟练掌握DQL 、DML 、DDL
SQL是一门特殊的语言,专门用来操作关系数据库,且不区分大小写
二、mysql 对数据库的相关操作
1、mysql -u root -p 进入mysql操作界面
mysql -h 192.168.126.128 -u root -p 访问该主机地址的mysql
2、查看数据库: show databases;

2、创建数据库: create database 数据库 charset=utf8; ( 默认使用拉丁文字符串,不重置的话使用中文会报错)

3、查看创建出来的数据库: show create database 数据库;

4、删除数据库: drop database 数据库;

5、选择数据库: use 数据库;

6、查看正在使用的数据库: select database( );

7、查看默认存储引擎: show variables like"%storage_engine%";

8、查看 mysql 数据库系统支持的储存引擎的类型

9、强调说明
数据库中,名字中带有中横线的,会当成特殊意义,需要使用 ` ` 将其括起来 ( Esc键下面, Tab键上面)

三、mysql 对数据库表的相关操作
1、创建数据库表: create table 表名( 字段1 约束 ,字段2 约束 . . . . . );

① 表名不能为 sql 语言的关键字,一个表中可以有多个字段,定义时,字母大小写均可,各字段之间使用逗号分隔开,最后一个字段后不需要加逗号,字段后面可以加上完整性约束条件
②完整性约束条件:完整性约束条件是对字段进行限制,要求用户对该属性进行的操作符合特定的要求,如果不满足完整性约束条件,数据库系统将不执行用户的操作,其目的是为了保证数据库中数据的完整性
主键 primary key:物理上存储的顺序
非空 not null:此字段不允许填写空值
唯一 unique:此字段的值不允许重复
默认 default:当不填写值时,会使用默认着,填写时,以填写内容为准
外键 foreign key:对关系字段进行约束,当为关系字段填写值时,会到关联的表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并抛出异常(虽然外键约束可以保证数据的有效性,但是在进行数据的增加、修改、删除、查询时,都会降低数据库的性能,所以不推荐使用,那么如何保证数据的有效性呢:在逻辑层进行控制)
auto_increment :标识该属性的值自动增加
③常用数据类型:使用char定义长度时,即使没有写入数据,也会占用字节,使用varchar时,则根据写入的数据占用字节,所以通常使用varchar来定义


2、查看当前数据库中的数据库表: show tables;

3、修改表名: alter table 原表名 rename 新表名; 或 alter table 原表名 rename to 新表名;

4、删除没有被关联的普通数据表: drop table 表名;

5、查看数据表的基本结构 (字段):desc(describe) 表名; 或 show create table 表名; 或 show create table 表名 \G


6、查看表的所有字段数据信息: select * from 表名;

图上,表示当前表的字段中没有任何数据
7、向表中添加新字段:
①向表的末尾添加字段: alter table 表名 add 字段名 数据类型 约束;
②向表的首位添加字段: alter table 表名 add 字段名 数据类型 约束 first;
③向表的指定位置添加字段: alter table 表名 add 字段名 数据类型 约束 after 某一个已存在的字段名;
④一次性添加多个字段:alter table 表名 add (字段名1 数据类型1 约束1,字段名2 数据类型2 约束2 ......)


8、删除字段: alter table 表名 drop 字段名;
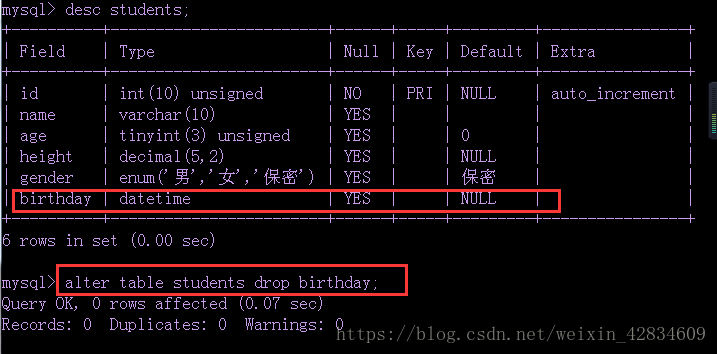

9、修改字段
①修改字段(不重命名): alter table 表名 modify 字段名 数据类型 约束 ;
②修改字段并移到首位 : alter table 表名 modify 字段名 数据类型 约束 first ;
③修改字段并移到指定位置: alter table 表名 modify 字段名 数据类型 约束 after 某个已存在的字段名;
③修改字段(重命名) : alter table 表名 change 原字段名 新字段名 数据类型 约束 ;


10、向表中插入数据
表的字段如下: 其中 sex 字段为枚举类型

①全列插入数据: insert into 表名 values( 数据内容1 ,数据内容2 ) ;
插入数据时,数据的类型需要与对应字段的数据类型一致,字符串需要加上引号,
可以使用 0 、null 、default 三种方法,为主键以及自动增加的 id 字段的值进行占位(不占位的话不符合格式要求,会报错)
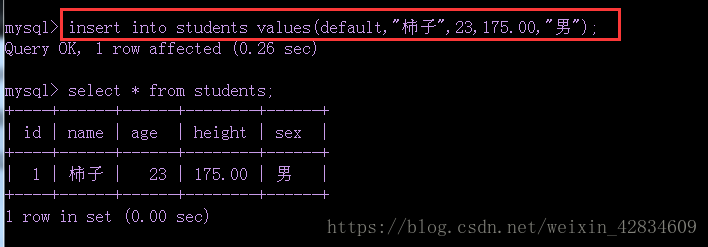
当字段为枚举类型时,也可以这样插入内容:

②部分插入数据: insert into 表名( 字段1,字段2,字段3 ......) values( 值1,值2,值3 ),values( 值1 ',值2 ',值3 ' ) ......

没有赋值的字段,数据库系统会为其插入默认值,如果某个字段没有设置默认值,而且是非空属性,那么就必须为其赋值,否则会报错,通过这种方式也可以随意的设置字段的内容,不一定非要按照定义时的字段顺序,一 一对应的为其赋值
11、更改数据内容: update 列表名 set 字段=值 where 条件;(如果不加上条件,默认全部修改)

12、删除数据 ( 物理删除 ): delete from 表名 where 条件;(删除时需要小心,不加上条件,默认全部删除)(truncate 表名 ; 删除表的全部内容,后面不能加条件,如where)

13、逻辑删除:向表中添加 is_delete 字段,数据类型为 bit ,默认值为 0 ,当默认值修改为1时,表示逻辑删除,可恢复

14、重置表:例如,当表中存在一个自增长的id字段时,若将某一个id=6的记录删除,再次添加数据时,id不会重复,也就是说不会再出现id=6这种情况了,需要使用重置功能,将表重置即可。需要注意的是,重置表会删除表的全部信息。
语法:truncate table 表名;

四、mysql 数据查询
1、基础查询:
①select * from 列表名; 查询列表的全部数据内容
select 列表名.* from 列表名; 查询列表的全部数据内容
select 数据库名.列表名.* from 列表名; 查询列表的全部数据内容

②查询列表的字段1和字段2数据内容
select 列表名.字段1,,列表名.字段2 from 列表名;

③ 去重查询(去重时只看一个字段条件)
select distinct 字段 from 列表名;



④条件查询 (比较运算符,逻辑运算符)
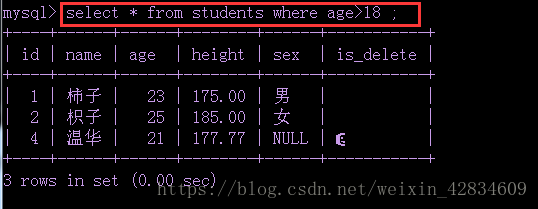
select * from 列表名 where 条件;

⑤模糊查询(kile %表示任意字符, _表示一位字符)
select * from 列表名 where 模糊条件;

⑥范围查询 in表示非连续范围, between ... and ... 表示连续范围
select * from 列表名 where 字段 in (范围) ;


⑦null 查询,使用 is 或 is not 来进行判断,这里需要注意的是 null 与 " " 并不相等
select * from 列表名 where 字段 is null ; 查询某个字段为 null 的信息
select * from 列表名 where 字段 is not null ; 查询某个字段不为 null 的信息

⑧排序查询 order by ( asc 升序,desc 降序)
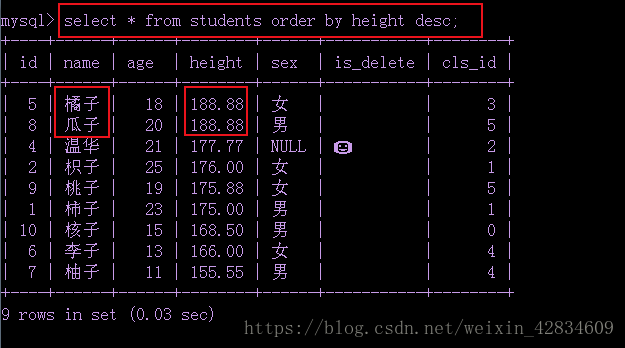
select * from 列表名 order by height desc; 按照身高,降序查询所有信息
select * from 列表名 order by height desc,age desc; 先按照身高,降序查询所有信息,若身高相同,再按照年龄降序查询

⑨聚合函数
⑴ count ( * ) 查询总数量
select count( * ) from 表名;

⑵ min(字段) 求此字段的最小值 , max(字段) 求此字段的最大值
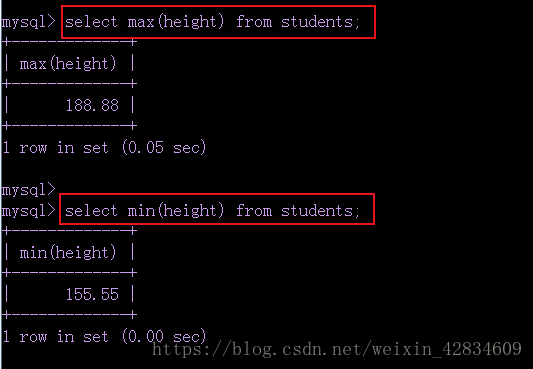
⑶ sum( 字段 ) 求此字段的和, avg( 字段 ) 求此字段的平均值

⑷ 分组: group by 字段
Ⅰ 分组:字段相同的数据放到一个组中( 执行效果与去重相同 ),分组后,分组依据显示在结果集中,其他字段不会显示,且分组时会升序排列

Ⅱ 分组 与 group_concat( ) 配合使用,可以依据分组,显示出指定内容

Ⅲ 分组 与 聚合函数配合使用:

Ⅳ having 条件
配合分组使用,having 后面跟的是筛选条件,与 where类似,where 是对 from 后面的表进行筛选,而 having 是对 group by的结果进行筛选

⑸ limit 限制查询结果数: limit x 限制查询 x 个数据 limit x,y 限制从第 x 处查询( 从第0个开始),且限制查询 y 个数据


拓展:通过 limit 来显示分页的查询结果
pageSize=3 表示每页显示3个数据, pageNow 表示当前处于第几页,allSum 表示所有符合查询结果的数据
if allSum%pageSize == 0:
pageNow = allSum / pageSize
else:
pageNow = allSum / pageSize + 1
select * from students limit ( pageNow - 1 ) * pageSize,pageSize
2、高级查询
①链接查询 内连接: inner join ... on.... 左连接: left join ... on.... 右连接: right join ... on....

首先,看一个两个表的数据:

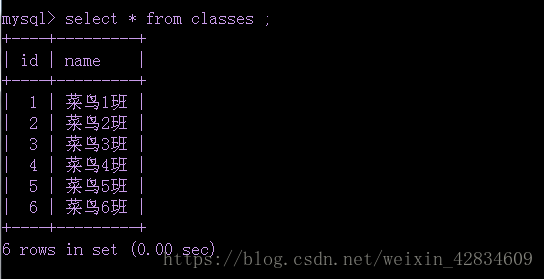
⑴内连接:查询结果为匹配到的共同数据

⑵左连接:查询结果为匹配到的共同数据,左表的全部数据,右表没有的使用 null 填充

⑶右连接:查询结果为匹配到的共同数据,右表的全部数据,左表没有的使用 null 填充

使用时,也可以改个名(只针对此次操作)

②自关联查询
查询全国的省份:

查询广东省的城市:

查询广州市的市区:

③子查询:在一个 select 语句中,嵌入了另一个 select 语句 ,这个嵌入的 select 语句,被称为子查询语句
子查询嵌入到主查询中,作用是辅助主查询( 充当条件或数据源 ),子查询是一条完整的 select 语句
查询所有大于平均身高的学生的信息:

子查询中出现的关键字:
any / some 主查询 where 字段 = any( 子查询); 查询结果中匹配到任意一个即可,等价于 in
all 主查询 where 字段 = all( 子查询); 等于里面所有的条件
主查询 where 字段 <> all( 子查询); 不等于里面所有的条件
in 主查询 where 字段 = in ( 子查询); 查询结果中匹配到任意一个即可,
主查询 where 字段 = not in ( 子查询); 查询结果中不能匹配到其中任何一个,

五、视图、事务、索引
1、视图:本质就是对一个查询的 sql 语句的封装
① 创建一个视图: create view 视图名 as select * from 表名;


② 删除一个视图: drop view 视图名

2、事务:事务是并发控制的基本单位,是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。 例如: 银行的转账工作,从一个账户扣钱并将钱转到另一个账户,只有两个操作都完成,转账工作才完成
①事务的四大特性( ACID ):
原子性:事务中的全部操作在数据库中都是不可分割的,要么全部完成,要么均不执行
一致性:几个并行执行的事务,其执行结果必须与按某一顺序串执行的结果一致
隔离性:事务的执行不受其他事务的干扰,事务执行的中间结果对其他事物必须是透明的
持久性:对于任意已提交的事物,系统必须保证该事物对数据库的改变不被丢失,即使数据库出现故障
②开启事务后,对数据库的更新操作不会立即影响到数据库,只有在成功之后,执行提交操作,才会将变化提交给源数据库
③使用事务时,需要注意的是:表的引擎类型必须是 innodb 类型,才可以使用事务,(innodb 是 mysql 的默认引擎)
修改表的存储引擎为 innodb引擎: alter table 表名 engine = innodb;
④ begin 开启事务, commit 提交事务 , rollback 回滚事务

从图上,我们可以看出,当 begin 开启事务后,对表进行了更新操作,虽然再次查询表数据时显示出来刚刚更新的数据,但实际上,在数据库中并没有对刚刚更新的数据进行更新,它仅仅是缓存了起来,

只有我们 commit 提交数据之后,数据库才会更新缓存中变更的数据

同理,使用 rollback 则放弃缓存中变更的数据
3、索引:索引是一种特殊的文件,它包含着对数据表所有记录的引用指针
创建索引: 如果指定字段类型是字符串,需要指定长度;如果字段类型不是字符串,则不需要指定长度
create index 索引名 on 表名( 字段名( 长度 ) );
删除索引: drop index 索引名 on 表名;
使用索引需要注意的是:只有当表的数据结构够复杂,数据量较大时,才能体现出索引的优势所在,当表的结构简单,使用索引反而效果不佳

六、数据备份与还原
1、备份: mysqldump -u username -p dbname table1 table2 > backupname.sql
其中,dbname参数表示数据库名称, table1、table2参数表示表的名称,没有该参数时将备份整个数据库,backupname.sql 参数备份文件的名称,通常后缀为 .sql ,文件名前面可以加上一个绝对路径
下面是备份 192.168.242.150 主机的 mysql 数据库中,一个叫做 python1807A 的数据库,

2、还原: mysql -u root -p dbname < backupname.sql

七、python 与 mysql 交互
1、流程图( python3 使用前需要先导入 pymysql包 )

2、Connection对象
①用于建立与数据库的连接,创建对象调用 connect 方法
格式: connect( 参数列表 )
⑴参数 host:连接的 mysql 主机,如果是本机,则为 " localhost " ⑵参数 port:连接的 mysql 主机的端口号,默认是3306
⑶参数 database:数据库的名称 ⑷ 参数 user:连接的用户名
⑸ password:连接的密码 ⑸ 参数 charset:通信采用的编码方式,推荐使用utf8
②Connection对象的方法:
close( ) 关闭连接
commit( ) 提交
rollback( ) 回滚
cursor( ) 返回Cursor对象,用于执行sql 语句,并获得结果
3、Cursor对象:通过调用 Connection 对象的 cursor 方法获取,用于执行 sql 语句,如:select、insert、update、delete
①对象的属性:
connection 获得当前连接对象
rowcount 只读属性,表示最近一次 execute( ) 执行后受影响的行数
②Cursor对象的方法:
close( ) 关闭
execute( ) 执行语句
fetchone( ) 执行查询语句时,获取查询结果集的第一个行数据,返回一个元组
fetchall( ) 执行查询语句时,获取查询结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回
4、实例

需要注意的是,占位时如果字段类型是字符串,需要使用引号引住,且传参时,需要使用列表传参,
还有一点值得注意的是,双引号内不允许再次出现双引号,