JAVA集合--深入浅出
首先看图,对JAVA集合形成一个知识结构图,方便理解
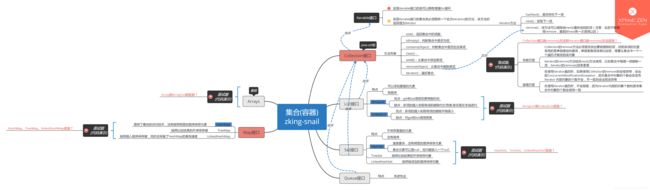
从图中可以看到 List,Set 都是Collection接口的子类,Map是一个单独的集合,以下是我个人的自我总结
实现Iterable接口的类可以拥有增强for循环(增强for循环就是fore)
Collection接口的remove()方法和Iterator接口的remove()方法区别:
明确Collection接口的remove有参
①性能方面
Collection的remove方法必须首先找出要被删除的项,找到该项的位置采用的是单链表结构查询,单链表查询效率比较低,需要从集合中一个一个遍历才能找到该对象;
Iterator的remove方法结合next()方法使用,比如集合中每隔一项删除一项,Iterator的remove()效率更高
②容错方面
在使用Iterator遍历时,如果使用Collection的remove则会报异常,会出现ConcurrentModificationException,因为集合中对象的个数会改变而Iterator 内部对象的个数不会,不一致则会出现该异常
在使用Iterator遍历时,不会报错,因为iterator内部的对象个数和原来集合中对象的个数会保持一致
List接口特点:可以添加重复元素,有顺序
ArryList和LinkedList的区别:
ArrayList(数组结构):
优点:get和set调用花费常数时间,也就是查询的速度快;
缺点:新项的插入和现有项的删除代价昂贵,也就是添加删除的速度慢
LinkedList(链表结构):
优点:新项的插入和和现有项的删除开销很小,即添加和删除的速度快
缺点:对get和set的调用花费昂贵,不适合做查询
Array与ArrayList有什么区别:
①.ArrayList是Array的复杂版本
②.存储的数据类型:Array只能存储相同数据类型的数据,而ArrayList可以存储不同数据类型的数据
③.长度的可变:Array的长度是固定的,而ArrayList的长度是可变的(每次增长为原来的1.5倍实际增长的量会越来越大)
Set接口特点:不保存重复元素,没有顺序
HashSet、TreeSet、LinkedHashSet区别:
①.需要速度快的集合,使用HashSet
②.需要集合有排序功能,使用TreeSet
③.需要按照插入的顺序存储集合,使用LinkedHashSet
Queue接口特点:先进先出
由queue引伸
队列(先进先出),堆栈(先进后出)
Looper循环,根据queue的特点一个个去拿
massage消息
Handler映射器 主线程:更新UI 线程间通信机制
子线程:执行耗时操作
子-looper-queue-massage-子-handler-主
Map接口:可以这样理解,Map是就是一个集合没有他自己就是父类,相当于Set和List特性的总体,以Set做Key,List做Value
key不可重复,value可重复
HashMap、TreeMap、linkedHashMap区别:
①.在Map中插入、删除和定位元素,HashMap是最好的选择
②.需要集合有排序功能,使用TreeMap更好
③.需要按照插入的顺序存储集合,使用LinkedHashMap
这个和Set的三个子类相同
HashMap和HashSet区别:

HashMap的实现原理:
通过put和get存储和获取对象,存储对象时,我们将K/V传给put方法时,它调用hashcode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量。获取对象时,我们将K传递给get,他调用hashcode计算hash从而得到bucket位置,并进一步调用equals()方法确认键值对。
最后总结:List、Set、Map之间的区别

集合操作实例之集合打乱顺序
以下实例演示了如何使用 Collections 类 Collections.shuffle() 方法来打乱集合元素的顺序:
import java.util.*;
public class Main {
public static void main(String[] args) {
List
for (int i = 0; i < 10; i++)
list.add(new Integer(i));
System.out.println("打乱前:");
System.out.println(list);
for (int i = 1; i < 6; i++) {
System.out.println("第" + i + "次打乱:");
Collections.shuffle(list);
System.out.println(list);
}
}
}
以上就是我的个人心得分享