Python小白的进阶之路---Day5
Python小白的进阶之路---Day5
- 1.file
- 1.1打开文件方式(读写两种方式)
- 1.2文件对象的操作方法
- 1.3学习对excel及csv文件进行操作
- 2.os模块
- 3.datatime模块学习
- 4.类和对象
- 5.正则表达式
- 6.re模块
- 7.http请求
参考链接:
https://study.163.com/course/courseLearn.htm?courseId=378003#/learn/video?lessonId=744213&courseId=378003
https://fishc.com.cn/forum.php?mod=viewthread&tid=45279&extra=page%3D1%26filter%3Dtypeid%26typeid%3D403
https://blog.csdn.net/weixin_34024034/article/details/88177249
https://fishc.com.cn/forum.php?mod=viewthread&tid=51725&extra=page%3D1%26filter%3Dtypeid%26typeid%3D403
https://blog.csdn.net/Greta1009/article/details/78953955
https://blog.csdn.net/qq_27171347/article/details/81017817
https://blog.csdn.net/sinat_28576553/article/details/81275650
https://blog.csdn.net/qq_41432935/article/details/82289001
https://blog.csdn.net/zzzzzztt/article/details/80861135
1.file
1.1打开文件方式(读写两种方式)
(1)文件的读取
在Python中,使用open()这个函数来打开文件并返回文件对象。open()函数有许多参数,作为初学者,我们先关注第一个和第二个参数。第一个参数是传入的文件名,如果只有文件名没有路径,会默认在当前文件夹中去找该文件并打开。第二个参数指定文件的打开模式:

>>> f=open('D:\\再别康桥.txt')
>>> f
<_io.TextIOWrapper name='D:\\再别康桥.txt' mode='r' encoding='cp936'>
(2)文件的写入
如果需要写入文件,要确保之前的打开模式有‘w’或‘a’,否则会报错。一定要注意,使用‘w’模式写入文件,此前的文件内容会被彻底删除!如果要在原来的内容上追加,一定要使用’a’模式打开!
>>> f=open('D:\再别康桥.txt')
>>> f
<_io.TextIOWrapper name='D:\\再别康桥.txt' mode='r' encoding='cp936'>
>>> f.read()
'轻轻的我走了, \n正如我轻轻的来; \n我轻轻的招手, \n作别西天的云彩。 \n\n那河畔的金柳, \n是夕阳中的新娘; \n波光里的艳影, \n在我的心头荡漾。 \n\n软泥上的青荇, \n油油的在水底招摇; \n在康河的柔波里, \n我甘心做一条水草!'
>>> f.close()
>>> f=open('D:\再别康桥.txt','a')
>>> f.write('I like it')
9
>>> f.close()
>>> f=open('D:\再别康桥.txt')
>>> f.read()
'轻轻的我走了, \n正如我轻轻的来; \n我轻轻的招手, \n作别西天的云彩。 \n\n那河畔的金柳, \n是夕阳中的新娘; \n波光里的艳影, \n在我的心头荡漾。 \n\n软泥上的青荇, \n油油的在水底招摇; \n在康河的柔波里, \n我甘心做一条水草!I like it'
>>> f=open('D:\再别康桥.txt','w')
>>> f.write('133')
3
>>> f.close()
>>> f=open('D:\再别康桥.txt')
>>> f.read()
'133'
1.2文件对象的操作方法
打开文件并取得文件对象后,就可以利用文件对象的一些方法对文件进行读取或修改等操作。下面是一些常用的文件对象方法:
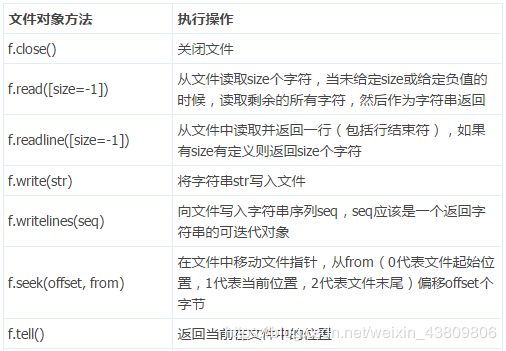
>>> f=open('D:\\再别康桥.txt')
>>> f
<_io.TextIOWrapper name='D:\\再别康桥.txt' mode='r' encoding='cp936'>
>>> f.read()
'轻轻的我走了, \n正如我轻轻的来; \n我轻轻的招手, \n作别西天的云彩。 \n\n那河畔的金柳, \n是夕阳中的新娘; \n波光里的艳影, \n在我的心头荡漾。 \n\n软泥上的青荇, \n油油的在水底招摇; \n在康河的柔波里, \n我甘心做一条水草!'
>>> f.read()
''
>>> f.close()
>>> f=open('D:\\再别康桥.txt')
>>> f.read(12)
'轻轻的我走了, \n正如我'
>>> f.tell() #一个中文字符占两个字节,一个空格占两个字节
23
>>> f.read(7)
'轻轻的来; \n'
>>> f.tell()
36
>>> f.readline()
'我轻轻的招手, \n'
>>> f.seek(20,0)
20
1.3学习对excel及csv文件进行操作
CSV是一种通用的,相对简单的文件格式,被用户、商业和科学广泛应用。最广泛的应用是在程序之间转移表格数据,而这些程序本身是不兼容的格式上进行操作的。因为大量程序都支持CSV变体,至少是作为一个可选择的输入/输出格式。
CSV”并不是一种单一的、定义明确的格式。因此在实践中,术语“CSV”泛指具有以下特征的任何文件:
- 纯文本,使用某个字符,比如ASCII、Unicode、EBCDIC或GB2312,由记录组成;
- 每条记录被分隔符分隔为字段(典型分隔符有逗号、分号或制表符);
- 有时分隔符可以包括可选的空格;
- 每条记录都有同样的字段序列。
csv的读取:
import csv#导入模块
#打开csv文件
with open("E:/Users/DELL/PycharmProjects/untitled1/销售相关企业信息.csv","r") as csvfile:#r代表read
#读取文件
read = csv.reader(csvfile)
# print(read)
for i in read:#使用遍历的方式来读取文件
print(i)
csv的写入:
with open('./csvtest.csv','w')as csvfile:#这里的w代表write写入
writer = csv.writer(csvfile)
writer.writerow(['id','url','keywords'])
data = [
('1','http://www.xiaoheiseo.com/','小黑'),
('2','http://www.baidu.com/','百度'),
('3','http://www.jd.com/','京东')
]
writer.writerows(data)#多行写入时为writerows 加s
对excel操作从主体上来分类分为读写两类,分别对应两个模块:xlrd和xlwt。
import xlrd #引入模块
#打开文件,获取excel文件的workbook(工作簿)对象
workbook=xlrd.open_workbook("DataSource/Economics.xls") #文件路径
# 导入xlwt模块
import xlwt
#创建一个Workbook对象,相当于创建了一个Excel文件
book=xlwt.Workbook(encoding="utf-8",style_compression=0)
'''
Workbook类初始化时有encoding和style_compression参数
encoding:设置字符编码,一般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中文了。默认是ascii。
style_compression:表示是否压缩,不常用。
'''
2.os模块
OS就是Operating System的缩写,意思是操作系统。对于文件系统的访问,Python一般是通过OS模块来实现的。有了OS模块,不需要关心什么操作系统下使用什么模块,OS模块会帮你做出正确的选择并调用。模块是一个包含所有你定义的函数和变量的文件,其后缀名是py。模块可以被别的程序导入,以使用该模块的函数等功能。
(1)os.模块中关于文件/目录常用的函数使用方法:

>>> import os
>>> os.getcwd()
'D:\\New Folder'
>>> os.listdir('d:\\原来桌面的东西')
['100568007411226.pdf', 'IMG一寸照.jpg', 'MicrosoftOffice-v2003', 'PDF_210794949.pdf', 'ppt模板', 'PS', 'Python-小甲鱼', 'python学习', 'YLYK', '中英文简历', '求职最终版', '浏览器', '鱼c小甲鱼零基础学python全套课后题带目录.doc']
>>> os.chdir('d:\\原来桌面的东西')
>>> os.rename('YLYK','友邻优课')
(2)os.path.模块中关于路径常用的函数使用方法:

3.datatime模块学习
在 Python 中,与时间处理有关的模块包括:time,datetime 以及 calendar。datetime 模块提供了各种类用于操作日期和时间,该模块侧重于高效率的格式化输出。
datetime 模块定义了两个常量:
- datetime.MINYEAR - date 和 datetime 对象所能支持的最小年份,object.MINYEAR 的值为 1
- datetime.MAXYEAR - date 和 datetime 对象所能支持的最大年份,object.MAXYEAR 的值为 9999
datetime 模块中定义的类:
- datetime.date - 表示日期的类,常用属性:year, month, day
- datetime.time - 表示时间的类,常用属性:hour, minute, second, microsecond, tzinfo
- datetime.datetime - 表示日期和时间的类,常用属性: year, month, day, hour, minute, second, microsecond, tzinfo
- datetime.timedelta - 表示时间间隔,即两个时间点(date,time,datetime)之间的长度
- datetime.tzinfo - 表示时区的基类,为上方的 time 和 datetime 类提供调整的基准
- datetime.timezone - 表示 UTC 时区的固定偏移,是 tzinfo 基类的实现
4.类和对象
对象 = 属性(变量)+ 方法(函数)
(1)类和对象是什么关系呢?
类和对象的关系就如同模具和用模具制造出来的物品之间的关系。一个类为它的全部对象给出了一个统一的定义,而它的每个对象则是符合这种定义的一个实体,因此类和对象的关系就是抽象和具体的关系。
(2)函数和方法有什么区别呢?
方法和函数其实几乎完全一样,但有一点区别是方法默认有一个 self 参数,这个参数的作用是绑定方法!当你调用方法时,对象会将自身作为第一个参数传给self,接收到这个self参数时,Python就知道这是哪个参数在调用方法啦。
(3)面向对象(object oriented)的特征:
- 封装:对外部隐藏对象的工作细节。例如调用方法,只知道方法名称和功能,却不知道技术细节。
- 继承:子类自动共享父类之间数据和方法的机制。
- 封装:对外部隐藏对象的工作细节。例如调用方法,只知道方法名称和功能,却不知道技术细节。
- 多态:可以对不同类的对象调用相同的方法,产生不同的结果。
- 当我们不希望对象的属性或方法被外部直接调用我们该怎么办呢?
我们可以在属性或方法名字前面加双下划线。 - 什么是组合? Python
继承机制很有用,但容易把代码复杂化以及依赖隐含继承。因此,我们可以经常使用组合来代替继承。组合其实很简单,直接在类定义中把需要的类放进去实例化就可以了。 - 类对象是在什么时候产生?
当你这个类定义完的时候,类定义就变成类对象,可以直接通过‘类名.属性’或‘类名.方法名()’引用,或使用相关的属性或方法。
5.正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。正则表达式用的最多的两个函数是re.match()和re.search()
(1)使用re.match()
match()视图从字符串的起始位置对模式进行匹配;如果匹配成功, 就返回一个匹配对象, 如果匹配失败, 就返回 None;匹配对象的group()方法能够显示那个成功的匹配。
使用语法:
re.match(pattern, string[, flags=0])
参数说明:
- 匹配的正则表达式. 直接传入一个字符串, python 会把这个字符串作为正则表达式来对待
- 要匹配的字符串.
- 标志位:用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
注意:match()匹配是从字符串的开始位置匹配, 如果开始不匹配则不会匹配成功, 返回一个 None
(2)使用re.search()
re.match()总是从字符串的开始位置开始匹配, 所以很多情况下能够匹配的概率不大;re.search()是在字符串中搜索正则表达式模式, 任何位置都可以.。返回的是第一次出现的匹配情况(因为正则字符串中可能会多处匹配);他的参数和re.match()是一样的, 返回值也是一个匹配对象。
区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
6.re模块
不同的语言均有使用正则表达式的方法,Python是通过re模块来实现的。re模块中除了常用的两个函数re.match()和re.search()外, 还有一些其他经常用到的函数。
-
拆分字符串:
re.split(pattern, string) -
替换字符串1:
re.sub(pattern, repl, string)
用repl去替换满足模式的子字符串,返回值就是替换后的新的字符串。 -
替换字符串2:
re.subn(pattern, repl, string)
和re.sub()是一样的, 但是返回值是一个元组,包含新字符串和替换的次数。 -
找到所有匹配1:
re.findall(pattern, string)
在字符串找到所有的匹配子字符串, 如果有分组, 则返回与分组匹配的字符串, 如果使用了不止一个分组, 返回的列表中, 每一项都是一个元组 -
找到所有的匹配2:
re.finditer(pattern, string)
与re.findall是一样的, 只是re.finditer()返回的是一个迭代器.
7.http请求
HTTP请求步骤为:
- 域名解析
- 发起TCP的3次握手
- 建立TCP连接后发起http请求
- 服务器端响应http请求,浏览器得到html代码
- 浏览器解析html代码,并请求html代码中的资源
- 浏览器对页面进行渲染呈现给用户
SOCKET访问web http:
import socket
url = 'www.sina.com.cn'
port = 80
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((url, port))
request_url = 'GET / HTTP/1.1\r\nHost: www.sina.com.cn\r\nConnection: close\r\n\r\n'
sock.send(request_url.encode())
response = b''
rec = sock.recv(1024)
while rec:
response += rec
rec = sock.recv(1024)
print(response.decode())
SOCKET访问https:
import socket
import ssl
url = 'dps-precheck-h.camcard.com'
port = 443
sock = ssl.wrap_socket(socket.socket())
sock.connect((url, port))
request_url = 'GET /api/v1/block/block_info?id=dpsv45_9aeb8b0e953711e7af605254003cf65b HTTP/1.1\r\nHost: dps-precheck-h.camcard.com\r\nConnection: close\r\n\r\n'
sock.send(request_url.encode())
response = b''
rec = sock.recv(1024)
while rec:
response += rec
rec = sock.recv(1024)
print(response.decode())
Python中将这些步骤被封装成了完整的模块,直接调用即可进行。以python3为例,类似模块有:urllib,urllib3,httplib,requests等。