python爬虫——多线程的简单实例
python爬虫——多线程的简单实例
1.先附上没有用多线程的包图网爬虫的代码
import requests
from lxml import etree
import os
import time
start_time = time.time()#记录开始时间
for i in range(1,7):
#1.请求包图网拿到整体数据
response = requests.get("https://ibaotu.com/shipin/7-0-0-0-0-%s.html" %str(i))
#2.抽取 视频标题、视频链接
html = etree.HTML(response.text)
tit_list = html.xpath('//span[@class="video-title"]/text()')#获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src')#获取视频链接
for tit,src in zip(tit_list,src_list):
#3.下载视频
response = requests.get("http:" + src)
#给视频链接头加上http头,http快但是不一定安全,https安全但是慢
#4.保存视频
if os.path.exists("video1") == False:#判断是否有video这个文件夹
os.mkdir("video1")#没有的话创建video文件夹
fileName = "video1\\" + tit + ".mp4"#保存在video文件夹下,用自己的标题命名,文件格式是mp4
#有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " +fileName)#打印出来正在保存哪个文件
with open (fileName,"wb") as f:#将视频写入fileName命名的文件中
f.write(response.content)
end_time = time.time()#记录结束时间
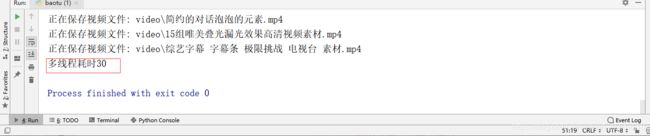
print("耗时%d秒"%(end_time-start_time))#输出用了多少时间
2.将上述代码套用多线程,先创建多线程
data_list = []#设置一个全局变量的列表
# 创建多线程
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#调用get_index()
def run(self) -> None:
self.get_index()
#拿到网址后获取所需要的数据并存入全局变量data_list中
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# 访问网址
# 将返回的数据转成lxml格式,之后使用xpath进行抓取
html = etree.HTML(resp.content)
tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接
for tit, src in zip(tit_list, src_list):
data_dict = {}#设置一个存放数据的字典
data_dict['title'] = tit#往字典里添加视频标题
data_dict['src'] = src#往字典里添加视频链接
# print(data_dict)
data_list.append(data_dict)#将这个字典添加到全局变量的列表中
except Exception as e:
# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取
self.q.put(url)
print(e)
3.用队列queue,queue模块主要是多线程,保证线程安全使用的
def main():
# 创建队列存储url
q = queue.Queue()
for i in range(1,6):
# 将url的参数进行编码后拼接到url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# 将拼接好的url放入队列中
q.put(url)
# 如果队列不为空,就继续爬
while not q.empty():
# 创建3个线程
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
4.创建存储方法
#提取data_list的数据并保存
def save_index(data_list):
if data_list:
for i in data_list:
# 下载视频
response = requests.get("http:" + i['src'])
# 给视频链接头加上http头,http快但是不安全,https安全但是慢
# 保存视频
if os.path.exists("video") == False: # 判断是否有video这个文件夹
os.mkdir("video") # 没有的话创建video文件夹
fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4
# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件
with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中
f.write(response.content)
5.最后就是调用函数了
if __name__ == '__main__':
start_time = time.time()
# 启动爬虫
main()
save_index(data_list)
end_time = time.time()
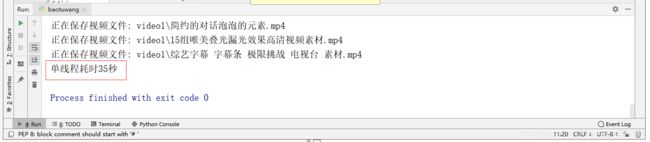
print("耗时%d"%(end_time-start_time))
6.附上完整的多线程代码
import requests
from lxml import etree
import os
import queue
import threading
import time
data_list = []#设置一个全局变量的列表
# 创建多线程
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#调用get_index()
def run(self) -> None:
self.get_index()
#拿到网址后获取所需要的数据并存入全局变量data_list中
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# 访问网址
# 将返回的数据转成lxml格式,之后使用xpath进行抓取
html = etree.HTML(resp.content)
tit_list = html.xpath('//span[@class="video-title"]/text()') # 获取视频标题
src_list = html.xpath('//div[@class="video-play"]/video/@src') # 获取视频链接
for tit, src in zip(tit_list, src_list):
data_dict = {}#设置一个存放数据的字典
data_dict['title'] = tit#往字典里添加视频标题
data_dict['src'] = src#往字典里添加视频链接
# print(data_dict)
data_list.append(data_dict)#将这个字典添加到全局变量的列表中
except Exception as e:
# 如果访问超时就打印错误信息,并将该条url放入队列,防止出错的url没有爬取
self.q.put(url)
print(e)
def main():
# 创建队列存储url
q = queue.Queue()
for i in range(1,7):
# 将url的参数进行编码后拼接到url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# 将拼接好的url放入队列中
q.put(url)
# 如果队列不为空,就继续爬
while not q.empty():
# 创建3个线程
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
#提取data_list的数据并保存
def save_index(data_list):
if data_list:
for i in data_list:
# 下载视频
response = requests.get("http:" + i['src'])
# 给视频链接头加上http头,http快但是不安全,https安全但是慢
# 保存视频
if os.path.exists("video") == False: # 判断是否有video这个文件夹
os.mkdir("video") # 没有的话创建video文件夹
fileName = "video\\" + i['title'] + ".mp4" # 保存在video文件夹下,用自己的标题命名,文件格式是mp4
# 有特殊字符的话需要用\来注释它,\是特殊字符所以这里要用2个\\
print("正在保存视频文件: " + fileName) # 打印出来正在保存哪个文件
with open(fileName, "wb") as f: # 将视频写入fileName命名的文件中
f.write(response.content)
if __name__ == '__main__':
start_time = time.time()
# 启动爬虫
main()
save_index(data_list)
end_time = time.time()
print("耗时%d"%(end_time-start_time))
7.这2个爬虫我都设置了开始时间和结束时间,可以用(结束时间-开始时间)来计算比较两者的效率。