记___美团爬虫
上一次的淘宝,写到一半被叫去做美团。。。。。。。呵呵了
我就直接,把我记录在wps文档的,记录分享出来了。莫怪
文本最后 是 githup 的代码地址
-
美团 美食 抓取;
- 1:Mysql 遇到的一个问题就是 “self.encoding = charset_by_name(self.charset).encoding”
- 原因在于 我把 python建立的mysql语句 “utf8”写成了“utf-8”
- 2:
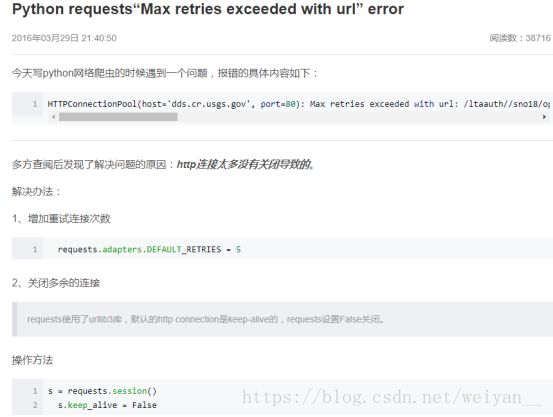
- 请求报错 是太多连接没有关闭,端口被占用了
- 3:

- 注意 这里不一定要纠结是不是代码错了,很有可能是你的数据表的问题。因为修改之后,原先的数据表不删除就写不进去
- 4:
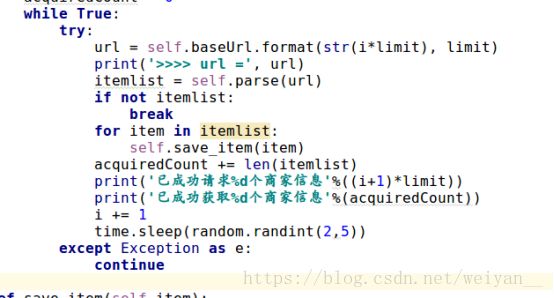
- 对于一个大型的爬虫而言,设置异常时必须的,因为你也不知道在获取网页数据的时候会出现什么情况,一旦出错就会中断爬取,耽误时间。所以 要谨记 异常处理
- 5:美团 api 接口
- 杭州美食第一页 http://hz.meituan.com/meishi/api/poi/getPoiList?cityName=%E6%9D%AD%E5%B7%9E&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=1&userId=&uuid=d7533380281d7c1cc28f.1532572421.0.0.0&platform=1&partner=126&originUrl=http%3A%2F%2Fhz.meituan.com%2Fmeishi%2F&riskLevel=1&optimusCode=1&_token=eJxtj1%2BPmkAUxb%2FLJH0qhZnhj4zJpkG2NGpcBQG1Gx%2BGEQQERBhhcdPv3iHtJvvQ5Cb33t85ybn3HTTzE5giCAmEEujiBkwBkqFsAAnwVii6ivUJ1gyCNWFgn9kEmsSUQNSEz2D6ikxdl1SCjyPxBHhFBEMJQRMepb8qgrpxlLAmanTNhQmknNdTRUkfchln%2FE4rmV1LRcxtminiiP%2Fr30vOn5CcxkX9BTu0zuTiIaNv2MQYy%2FkFDYhrFIiQ0h9DsIEl1dRGcBmB6PRf5x%2F7Snwu8trsXIkpXvRFHqB7n1tuGit237aX0zlbLKtytnN2N7wJrCLHbhCvkpyd5mx2MixCmb0yZjQJcKVrX7uIDbN15BuBfugVazOsY2JSO0Gky5WsZenZhtmw74u6vM3xIiP2vrueV9zbuuahy0qPKSuDvnAddrkVlQf4kl%2BxWetvxeHC1EczeM97d6uG3s13TPvntnmEqdKV9o9hCNng766lr8VD61T7KIebhKBlsbhzZ0lJCOnad2%2FYCeiwiya1GtpvyS%2Fvzp7A7z%2B9vqC0
- 杭州美食第二页http://hz.meituan.com/meishi/api/poi/getPoiList?cityName=%E6%9D%AD%E5%B7%9E&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=2&userId=&uuid=d7533380281d7c1cc28f.1532572421.0.0.0&platform=1&partner=126&originUrl=http%3A%2F%2Fhz.meituan.com%2Fmeishi%2Fpn2%2F&riskLevel=1&optimusCode=1&_token=eJx9T8lu4kAU%2FJe%2BYtGLabCR5uAdkxDAxmwRB9tguwmNHa%2FEo%2Fx7OprMYS4jPanqVZVK7%2F0GpXsGU4yQipAE2ksJpgAP0XAMJFBXwqEyoRNC5bEywhKI%2F9EmijqWQFRuTTB9xQqlkqyS07fiCeEVqwRJGCnoJP1xMaLjk0RGYr5TrgiBrK6LKYRZP%2BQXVjfhfRjnHApeZQwWdwLFIf%2FNAFHFN6JK4NsPhj9Y%2F90X4i1RVLH0Lthl3t2um7rpem3tLSFL34M8KA433dG8RivSZlHpxmxeP%2FvzQWV3DlsqvqwYeEP8xEUfxtPlsE37OPKJmbRLblddD9PVA9fabKHAljT2wH48mK6%2B35yE73idWcVidAzVipuB73r3qzNAJN%2FRtmN0%2F1xoTN87fbNP%2BSO2izUNGf9YHVZeeWARNphqyRwnVh7wnHeJ3qeWGjlzz4qCdauszuGT3GbFzD1mk3ZXwaUfxHI%2BOO%2FyWDWvRbk9niFtX8y%2BNX0j%2FgU%2BvwDmHZlN
- 杭州美食第三页
http://hz.meituan.com/meishi/api/poi/getPoiList?cityName=%E6%9D%AD%E5%B7%9E&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=3&userId=&uuid=d7533380281d7c1cc28f.1532572421.0.0.0&platform=1&partner=126&originUrl=http%3A%2F%2Fhz.meituan.com%2Fmeishi%2Fpn2%2F&riskLevel=1&optimusCode=1&_token=eJx9T8lu4kAU%2FJe%2BYtGLabCR5uAdkxDAxmwRB9tguwmNHa%2FEo%2Fx7OprMYS4jPanqVZVK7%2F0GpXsGU4yQipAE2ksJpgAP0XAMJFBXwqEyoRNC5bEywhKI%2F9EmijqWQFRuTTB9xQqlkqyS07fiCeEVqwRJGCnoJP1xMaLjk0RGYr5TrgiBrK6LKYRZP%2BQXVjfhfRjnHApeZQwWdwLFIf%2FNAFHFN6JK4NsPhj9Y%2F90X4i1RVLH0Lthl3t2um7rpem3tLSFL34M8KA433dG8RivSZlHpxmxeP%2FvzQWV3DlsqvqwYeEP8xEUfxtPlsE37OPKJmbRLblddD9PVA9fabKHAljT2wH48mK6%2B35yE73idWcVidAzVipuB73r3qzNAJN%2FRtmN0%2F1xoTN87fbNP%2BSO2izUNGf9YHVZeeWARNphqyRwnVh7wnHeJ3qeWGjlzz4qCdauszuGT3GbFzD1mk3ZXwaUfxHI%2BOO%2FyWDWvRbk9niFtX8y%2BNX0j%2FgU%2BvwDmHZlN
- 现在自己采用的不是API接口,应该是美团稍微简单一些。所以我 使用的还是美团的常用URL
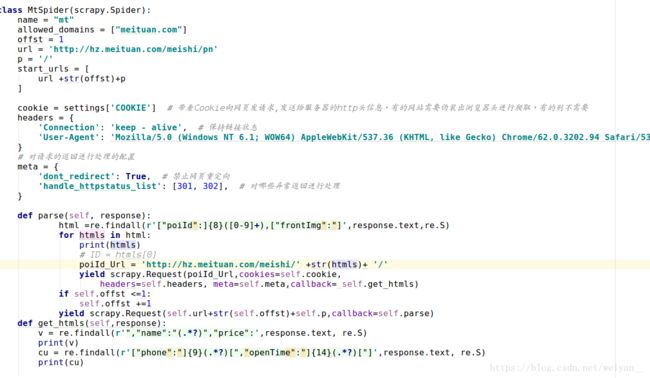
- 一个 经验,就是逻辑要通,不要害怕会写错,有出错才好。因为出错了就会想办法去更正,这一点一滴的积累会让自己对技术成熟的更加向往
- 还有就是 对于反爬虫的应用真的很重要,因为反爬降落了难度就会给自己更多的时间去挖数据,接下来就是各种文本加载技术了。
- 对于美团,个人觉得,最好最快的方式还是处理json文件,再加上多线程那就更快了。唯一一个阻碍就是对于 反爬虫的,最最好是cookies 加上 ip

- 对于 要求来说,存到mysql是一个列表,也不知道会不会有些影响,暂时放着
- ·数据库的问题 用这一点解决了重复入库,但是并没有实现去重

- 反爬虫的问题,这里用的是heard,也不知道能撑多久。我想好用,分布式来看看这个会不会=更好
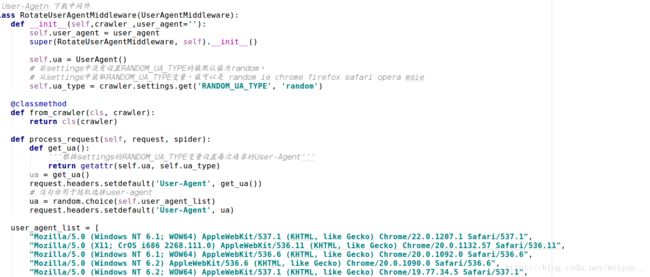
1.现在是 美团酒店
- 这是第三页的ajax
- https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=20&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401532745915720&cityId=50&offset=60&limit=20&startDay=20180728&endDay=20180728&q=&sort=defaults&X-FOR-WITH=A9zBrWbsPy9%2FkB5OsIXp58FacGY2HnPpuTKcnXwAOE7xfmoKm2mgBv%2BakwTPMOHFHHtGB5FENmXhMb4oxlIx1r3vlngfPZbw8hhCc45On662dXFYtNJH7IXqIlwbNW7bjFZ9zV2L%2BCkDc21Batgesg%3D%3D
- https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=20&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401532747143283&cityId=50&offset=0&limit=20&startDay=20180728&endDay=20180728&q=&sort=defaults&X-FOR-WITH=hNIARlUNQ2iElBBJfKlI3Kc03DsgxjQIUSDERw5zzjTOZ6gat08IQND2aGfHUHRd7AgvlOPKbD64wlKL%2FHEyPqd6JOtJeiL6TFEPXkVPa8cdEc6C%2B%2FlrwuQ0ZmIv%2Ba51XkBmzbNfUH8R0Mq0IxcJ5A%3D%3D
- https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=20&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401532759522322&cityId=50&offset=20&limit=20&startDay=20180728&endDay=20180728&q=&sort=defaults&X-FOR-WITH=8hAtT%2BPr%2Fr9fruMiqXvKUYNdORB7Hh2d5cbvRPRXU%2BdxfBoJ7qX%2F9X8d580DCnxmPs86NvNMcgfwXhCzIKBhNFkisdbjasDM4hIeQx1lrv3amWaB%2FY%2FwwIJPfX%2B84nqrc7JtEU0VoFrfPJ%2F97aW7JQ%3D%3D
- 这是杭州酒店的第一页的城市ajax连接,酒店不与美食相比,更加的严锁。我的第一个想法还是构建url,肯定有很多方法,例如模拟浏览器行为,解析ajax。。。。。
- 偏移量 offset = 这里考虑的是scrapy能不能循环请求,限定数看到不能是offset = 页数 * 20,因为有的城市最后不一定是20.美团是这样设定的,不管你有多少酒店一页最多20,然后往后累加知道最后不足20. 美食就是最多一页32,最多32页。个人理解
- 首先 我想到的是一位大神写的,感觉真不错“token验证”。因为我个人觉得,不能总是学着大家都在都会的技巧,总要掌握一些个别的技巧吧。并没说是让自己成为 群鸡独立 的这样,看怎么理解我说的了,你说对吧??
- 首先 经过试验可以构造ajax进行请求,
- 但是数据有些不对,上面url,发现sort=defaults后面&接的是编码,应该是‘吃喝玩乐。。。。啥啥的’。或者是别的解释,应该不能用在一起,会被检测到。所以,后边的就不要了,取前面一部分
- http://p1.meituan.net/750.0.0/tdchotel/313280169021582a96962dc353e07264132630.jpg
- http://p1.meituan.net/750.0.0/tdchotel/59ecb187de1243e1d37a0b54864da6ab494498.jpg
- http://p1.meituan.net/w.h/tdchotel/313280169021582a96962dc353e07264132630.jpg
- 1,2两张图片 可以发现其实都是 js 产生的。3 图片是打不开的,但是最后的数字是有用,用正则取出来,拼接成1,2类型的url
- https://ihotel.meituan.com/group/v1/poi/933710/imgs?utm_medium=touch&version_name=999.9&classified=true&X-FOR-WITH=5INGtURN7sNam4GpyRmKvyBNXktw8sM4V3zFVKRh0nJQfQaNxQcI87niwOblmDR9qLbYGZ6EI3ev%2BUMSLAUPcPO7C1LHmOjyDYPw74cDEAqLnVZRyPfyCOq6awS0%2BUrEkQQLLMcnKB7OxfcPeGFOyg%3D%3D
- 上面的链接是,图片的url,但是打不开。

- 一个冷知识,关于 双引号和单引号。在scrapy shell 一开始总犯错
- 关于scrapy 请求response 的问题,是不是又先后顺序?for循环是不是不是按照循序来的,一大群基础冷知识。我对自己呵呵哒了。
- 这里代码的意思,我要取出图片的关键条码,tdchotel/和.jpg/png然后组成能打开的url,原先直接一个for循环,造成图片不与酒店对应。原因是图片id居然和详情id不一致,按理说for循环第一次和第二次取出来的值是一样的。但是这里不一样,没办法了,为了一致,只有把详情id取出,在拼接。 诸位 要习惯,程序员不只是要懂代码,还要知道业务,我的工作是对接项目所需要的数据,尽管我很不想这样做
- Scrapy shell 真的是一样好的特别好的工具,不管是正则还是xpath还是bs4 css 甚至还可以response.text 返回直观的信息
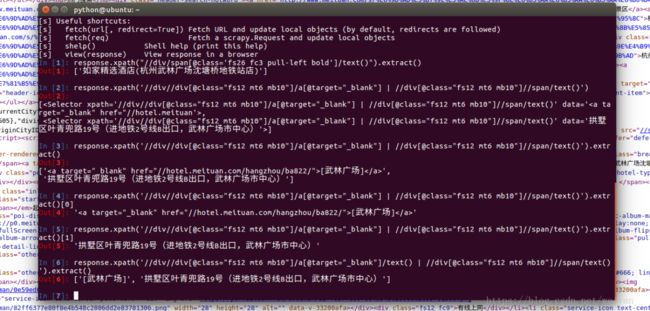
1.
- 刚才粗心的,习惯性的按回车键。结果是 Item = HoeltItem() 少了括号
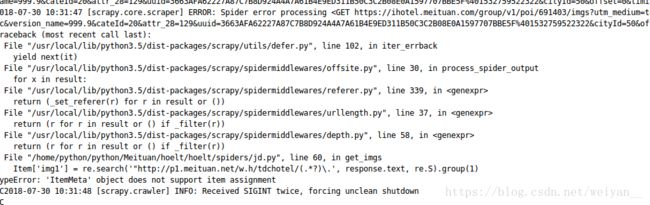
- 这里我请求了两个response,scrapy应该是按照什么特性来请求的。所以 我觉得用 crawlspider 递归请求
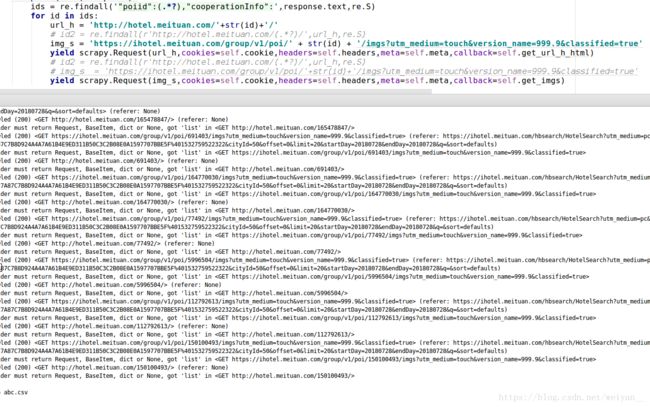
- 昨天看到一个神器 scrapy-splash 就学着用,没想到安装出了问题。Pip3 一直显示已安装,但是并没有。弄了半天,发现直接找到安装的文件,然后删除 再安装 rm -rf

- 对比url,找到城市ID
- 'https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=50&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401532759522322&cityId=50&offset=0&limit=20&startDay=20180728&endDay=20180728&q=&sort=defaults'
- https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=20&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401532745915720&cityId=50&offset=60&limit=20&startDay=20180728&endDay=20180728&q=&sort=defaults
- https://ihotel.meituan.com/hbsearch/HotelSearch?utm_medium=pc&version_name=999.9&cateId=20&attr_28=129&uuid=3663AFA62227A87C7B8D924A4A7A61B4E9ED311B50C3C2B08E0A1597707BBE5F%401533005717401&cityId=807&offset=20&limit=20&startDay=20180731&endDay=20180731&q=&sort=defaults
-
- 不管是酒店,还是美食,到了最后几页,商店的信息都不完整。用re.search().grup(),就会报错,而不会报空。再有 用if 判断每条信息会不会太繁琐了。
- 暂时 先停下,被安排,研究拼多多
-
-
首先相信美团的工程师们 会来csdn溜达,代码我就不去公布了,我自己改成了scrapy,现在打算改scrapy_redis分布式,一个城市一线大概都在两万以上,二线基本是千把个。遇到最大的问题就是302验证码,和空数据。我写了ip池和cookies来应对,然后单纯的空,需要另外看了。谢谢 美团工程师的仁慈了
首先 谢谢你看到这里,希望能留下你的观点和指正
这是 githup https://github.com/weijizhen/meituan_spider