Python爬虫获取PPT模板
多风格PPT任君挑
作为一个资深直男,审美风格一直被好友所诟病。然而直男的另一大特点就是,爱咋咋,反正已经这样了,这种破罐子破摔的心理需要适当的改变了。毕业前夕为了将四五十页的论文压缩到十几页的PPT上真是愁白了头,看着别人高大上的图标,醒目的背景,酷炫的动态效果吊炸天,心想一个PPT而已,至于吗,Ctrl+C—>Ctrl+V不就解决了吗。何必费那么大周折。嘴上这么说,心理也是极其渴望能做的一手好PPT的。初入职场,本以为可以逃离毕业答辩时的无措,紧张,转正在即,PPT还没做?模板还没下?赶紧百度,噼里啪啦找了半天终于发现一个免费网址,网页上挑了半天找了一个合适的下载下来开始准备答辩内容。每次需要每次去找真的很麻烦,这不是一个专业程序员的做法,作为一个职场人,以后工作汇报少不了要做PPT,如果每次都去找模板确实费时费力,于是乎利用一个周末把那家网站上的PPT全部Down下来,没事多写一些工作总结,模板用的多了,自然就直男的审美会提高的。
下面分享一下解析网页,下载PPT的流程。
1多方查找,找到免费网站(感恩)
网址:http://www.1ppt.com
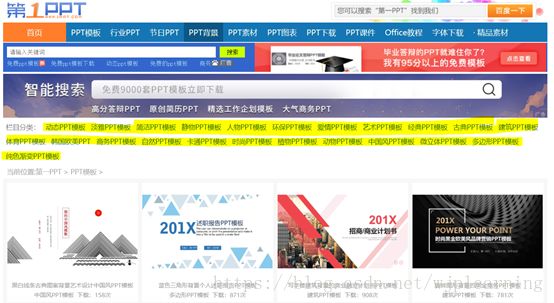
图1:主页
本文主要对主页标黄的23种Style进行下载。
2爬虫思路
整体思路:
- 首先对主页网页进行解析,获取23种style的网址
- 对每一种style进行解析,获取每一种style的每一页的网址
- 对每一页进行解析获取每一个PPT的网址
- 对每一个PPT网址解析,获取下载链接下载PPT到本地。
下载的实现也是基于这四步一步步进行分析,测试。最后进行代码整合和相应的异常处理等。
3爬虫流程
3.0.爬虫必备
import requests, os
from lxml import etree
requests用来获取网页源代码,lxml库的etree用来解析网页结构,十分的方便好用,相关文档查看:https://lxml.de/
基础方法:
- 每打开一个网页都要获取源代码所以把获取网页源代码封装在一个方法内
def get_url_text(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding htmlText = r.text except Exception: print("Error") return None return htmlText
- 解析网页的模式基本一样,首先:将源代码文本转换为HTML结构,其次:解析对应的内容
html = etree.HTML(htmlText, etree.HTMLParser()) urls = html.xpath("表达式")
3.1.风格解析
审查元素,分析源代码的结构,找到23种风格的网址。
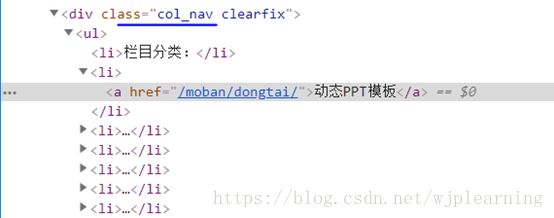
网页结构很清晰,解析网址:
def get_moban_url(url): urls = None htmlText = get_url_text(url) if htmlText: html = etree.HTML(htmlText, etree.HTMLParser()) urls = html.xpath("//div[@class='col_nav clearfix']//ul//li//a/@href") return urls
注://div[@class='col_nav clearfix']//ul//li//a/@href表达式的//相当于整个文本的当前目录,从整个文本里面找到class=’ col_nav clearfix’的div标签,然后找div下的ul标签然后根据表达式一层一层往下找,我们需要的是a标签下的网址,所以到达a后用一个/就可以了。
3.2.页码解析
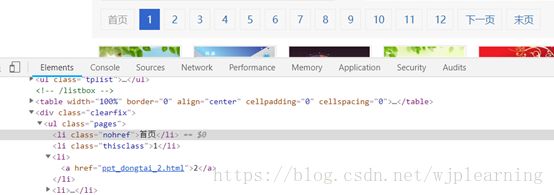
查看每一个风格下有多少页,通过分析发现,首页,下一页,末页都在要查找的标签之内,而且还有很多其他不需要的标签。
['ppt_dongtai_2.html', 'ppt_dongtai_3.html', 'ppt_dongtai_4.html', 'ppt_dongtai_5.html', 'ppt_dongtai_6.html', 'ppt_dongtai_7.html', 'ppt_dongtai_8.html', 'ppt_dongtai_9.html', 'ppt_dongtai_10.html', 'ppt_dongtai_11.html', 'ppt_dongtai_12.html', 'ppt_dongtai_2.html', 'ppt_dongtai_12.html']
需要做相应的处理(确保页数拼接正确的网址!):
n = len(urls) - 1 urls = ['ppt_%s_%d.html' % (style, i) for i in range(1, n + 1)]
整体代码:
def get_style_url(url, style): urls = None htmlText = get_url_text(url) if htmlText: html = etree.HTML(htmlText, etree.HTMLParser()) urls = html.xpath("//ul[@class='pages']//li//a/@href") n = len(urls) - 1 urls = ['ppt_%s_%d.html' % (style, i) for i in range(1, n + 1)] return urls
3.3.页面解析

每一页大概有30个PPT对应的结构如上图:解析如下
urls = html.xpath("//ul[@class='tplist']//li//a/@href")
结果:
![]()
发现很多重复和如黄色标记非正式格式:做相应的处理如下:
urls = [url for url in set(urls) if url.__contains__('.html')]
整体代码:
def get_style_page(url): urls = None htmlText = get_url_text(url) if htmlText: html = etree.HTML(htmlText, etree.HTMLParser()) urls = html.xpath("//ul[@class='tplist']//li//a/@href") # print(urls, len(urls)) urls = [url for url in set(urls) if url.__contains__('.html')] return urls
3.4.下载链接解析
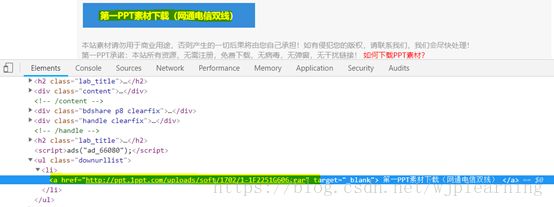
每一个单独的PPT点进去如上图,解析上面的下载链接如下:
urls = html.xpath("//ul[@class='downurllist']//li//a/@href")
整体代码:
def get_down_url(url): urls = None htmlText = get_url_text(url) if htmlText: html = etree.HTML(htmlText, etree.HTMLParser()) urls = html.xpath("//ul[@class='downurllist']//li//a/@href") return urls[0]
3.5.下载PPT
获取下载链接后可以下载了,代码如下:
def down_ppt(url, path): if url: filename = path + url.split('/')[-1] try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding htmlContent = r.content # 下载文件用content以二进制方式写入文件。 with open(filename, "wb") as f: f.write(htmlContent) except Exception: print(url + "下载失败!") else: print(url + "下载成功")
4源代码
def main(): # 1 获取所有风格的网址 url_1 = 'http://www.1ppt.com/moban/' urls_1 = get_moban_url(url_1) # ['/moban/dongtai/', '/moban/danya/', ,,,,] for item in urls_1: url_2 = 'http://www.1ppt.com' + item style = item.split('/')[-2] try: if not os.path.exists(style): os.mkdir(style) else: print(style + "文件夹已存在!") continue except Exception: print(style + "文件夹创建失败!") # 2.对某一风格进行解析获取多少页的网址 pages = get_style_url(url_2, style) # ['ppt_dongtai_1.html', 'ppt_dongtai_2.html',,,,] for page in pages: url_3 = 'http://www.1ppt.com/moban/%s/%s' % (style, page) # 3 对某一风格的每一页进行解析 ppt_html = get_style_page(url_3) # ['/article/41754.html', '/article/32755.html', ,,,] for html in ppt_html: url_4 = 'http://www.1ppt.com' + html # 4 对每一个PPT进行获取下载网址并下载 down_url = get_down_url(url_4) down_ppt(down_url, style + '/') print(style + "完成下载!")
说明:其实上面每个方法都有重复的地方,可以进一步的整合。代码用到下载,读写,操作文件等需要进行异常处理,防止因为某一个下载失败而中断进程。还有一个不足之处就是,每一个风格都有很多页而我直接先获取有多好页然后拼接网址,也可以使用selenium库模拟点击click操作!相关内容读者自行百度。
5结果展示