hive常见的几种文件存储格式与压缩方式的结合-------Parquet格式+snappy压缩 以及ORC格式+snappy压缩文件的方式
一.使用Parquet存储数据
数据使用列存储之前是普通的行存储,下面是行存储的的文件大小,这个HDFS上的数据
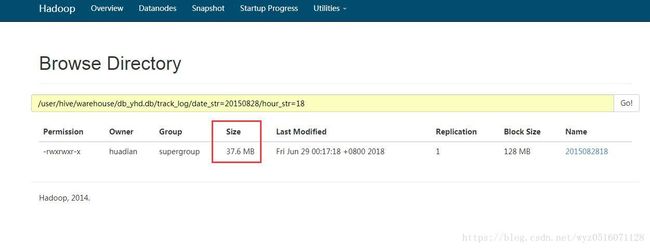
使用parquet列存储,可以将文件的大小减小化。下面具体讲parquet存储数据的代码以及加载数据的格式。
数据库代码:
create table if not exists db_yhd.track_log_parquet(
id STRING,
url STRING,
referer STRING,
keyword STRING,
type STRING,
guid STRING,
pageId STRING,
moduleId STRING,
linkId STRING,
attachedInfo STRING,
sessionId STRING,
trackerU STRING,
trackerType STRING,
ip STRING,
trackerSrc STRING,
cookie STRING,
orderCode STRING,
trackTime STRING,
endUserId STRING,
firstLink STRING,
sessionViewNo STRING,
productId STRING,
curMerchantId STRING,
provinceId STRING,
cityId STRING,
fee STRING,
edmActivity STRING,
edmEmail STRING,
edmJobId STRING,
ieVersion STRING,
platform STRING,
internalKeyword STRING,
resultSum STRING,
currentPage STRING,
linkPosition STRING,
buttonPosition STRING
)
PARTITIONED BY(date_str String,hour_str STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS Parquet
加载数据
INSERT OVERWRITE TABLE db_yhd.track_log_parquet PARTITION (date_str="20150828",hour_str="18") IF NOT EXISTS
SELECT id,url,referer,keyword,type,guid,pageId,moduleId,linkId,attachedInfo,sessionId,trackerU,trackerType,ip,trackerSrc,cookie,orderCode,trackTime,endUserId,firstLink,sessionViewNo ,productId,curMerchantId ,provinceId,cityId,fee,edmActivity,edmEmail,edmJobId,ieVersion,platform,internalKeyword,resultSum,currentPage,linkPosition,buttonPosition
FROM
db_yhd.track_log
WHERE
date_str="20150828" and hour_str="18"
测试结果截图:
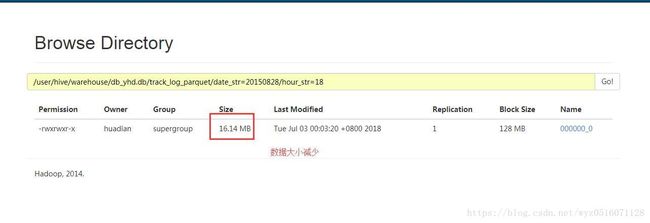
二.使用Parquet格式+snappy压缩
也可以使用parquet格式+snappy压缩格式实现文件的压缩,减少数据的大小,增加数据的加载速度。
压缩代码:
set parquet.compression=snappy;
create table if not exists db_yhd.track_log_parquet_snappy(
id STRING,
url STRING,
referer STRING,
keyword STRING,
type STRING,
guid STRING,
pageId STRING,
moduleId STRING,
linkId STRING,
attachedInfo STRING,
sessionId STRING,
trackerU STRING,
trackerType STRING,
ip STRING,
trackerSrc STRING,
cookie STRING,
orderCode STRING,
trackTime STRING,
endUserId STRING,
firstLink STRING,
sessionViewNo STRING,
productId STRING,
curMerchantId STRING,
provinceId STRING,
cityId STRING,
fee STRING,
edmActivity STRING,
edmEmail STRING,
edmJobId STRING,
ieVersion STRING,
platform STRING,
internalKeyword STRING,
resultSum STRING,
currentPage STRING,
linkPosition STRING,
buttonPosition STRING
)
PARTITIONED BY(date_str String,hour_str STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS Parquet
加载数据
INSERT OVERWRITE TABLE db_yhd.track_log_parquet_snappy PARTITION (date_str="20150828", hour_str="18" ) IF NOT EXISTS
SELECT id,url,referer,keyword,type,guid,pageId,moduleId,linkId,attachedInfo,sessionId,trackerU,trackerType,ip,trackerSrc,cookie,orderCode,trackTime,endUserId,firstLink,sessionViewNo ,productId,curMerchantId ,provinceId,cityId,fee,edmActivity,edmEmail,edmJobId,ieVersion,platform,internalKeyword,resultSum,currentPage,linkPosition,buttonPosition
FROM
db_yhd.track_log
WHERE
date_str="20150828" and hour_str="18"
测试结果截图:
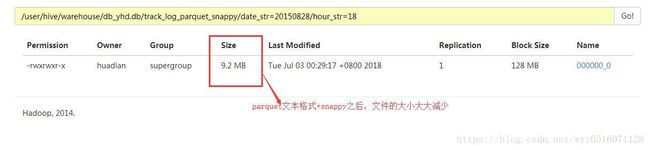
三.使用ORC格式存储 + snappy压缩
可以使用orc文本格式+snappy压缩格式下面是它的具体实现方法:
SQL语句:
create table if not exists db_yhd.track_log_orc_snappy(
id STRING ,
url STRING,
referer STRING,
keyword STRING,
type STRING,
guid STRING,
pageId STRING,
moduleId STRING,
linkId STRING,
attachedInfo STRING,
sessionId STRING,
trackerU STRING,
trackerType STRING,
ip STRING,
trackerSrc STRING,
cookie STRING,
orderCode STRING,
trackTime STRING,
endUserId STRING,
firstLink STRING,
sessionViewNo STRING,
productId STRING,
curMerchantId STRING,
provinceId STRING,
cityId STRING,
fee STRING,
edmActivity STRING,
edmEmail STRING,
edmJobId STRING,
ieVersion STRING,
platform STRING,
internalKeyword STRING,
resultSum STRING,
currentPage STRING,
linkPosition STRING,
buttonPosition STRING
)
PARTITIONED BY(date_str String,hour_str STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY")
加载数据:
INSERT OVERWRITE TABLE db_yhd.track_log_orc_snappy PARTITION (date_str="20150828", hour_str="18" ) IF NOT EXISTS
SELECT id,url,referer,keyword,type,guid,pageId,moduleId,linkId,attachedInfo,sessionId,trackerU,trackerType,ip,trackerSrc,cookie,orderCode,trackTime,endUserId,firstLink,sessionViewNo ,productId,curMerchantId ,provinceId,cityId,fee,edmActivity,edmEmail,edmJobId,ieVersion,platform,internalKeyword,resultSum,currentPage,linkPosition,buttonPosition
FROM
db_yhd.track_log
WHERE
date_str="20150828" and hour_str="18"
测试结果截图:
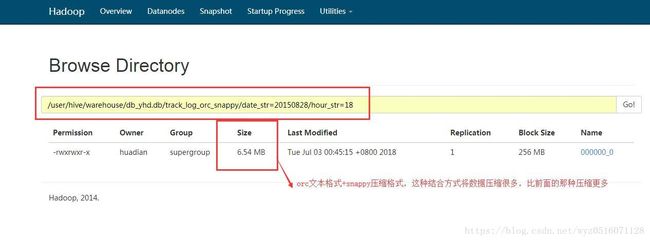
4.总结
以上这三种方式虽然对数据进行了大幅度的压缩,但是还是没有改变元数据的分割性,原来的值没有改变。虽然文件的大小压缩越小越好,但是,在压缩中不能改变数据的分割性以及原文件的数据内容需保持不变。以上是比较常见的组合压缩方式。