Kubernetes学习之 Hadoop cluster in Kubernetes
花了一个周末完成了hadoop cluster in k8s应用,经过测试能正常跑通wordcount例子。在构建过程中虽然攻克了一个问题又遇一个问题,但是整个过程还是很享受,特别是最后跑通测试用例。
hadoop cluster 启动过程
hadoop 集群是怎么启动的呢,通过实验我发现:hadoop集群的启动是由master根据slaves文件里配置的node hostname通过ssh启动node上的NodeManager和DataNode服务来向master进行注册的。
通过jps命令可以查看

hadoop传统启动:
1. 启动前需要将所有node hostname写master的slaves文件
2. 启动前需要将所有node的hostname和ip 写入master的hosts,以便能够解析hostname
问题:
1.由于node是被动启动,slaves在master启动前需要确定,故集群不能动态扩展。
2.由于node的ip是无法获取到的,所以需要为每个node创建一个server,这样是不妥的。
思考:
创建node容器时如果能主动启动NodeManager和DataNode服务来向master进行注册,并向master的hosts文件中注册hostname和ip,这样就可以解决上面两个问题了。
解决思路:
1.在node容器写一个脚本,用来启动NodeManager和DataNode服务主动向master注册。
2.在master和node容器里各写一个监听服务,用来注册hostname和ip到hosts文件中,这样就不用为node创建server。
build hadoop Docker image
hadoop 配置文件
构建hadoop镜像需要配置4个核心配置文件和一个环境脚本:- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///root/hdfs/namenodevalue>
<description>NameNode directory for namespace and transaction logs storage.description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///root/hdfs/datanodevalue>
<description>DataNode directorydescription>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
#关闭hostname验证,不然可能无法注册到master,因为node的hostname可能还没有注册到master的hosts文件中
<name>dfs.namenode.datanode.registration.ip-hostname-checkname>
<value>falsevalue>
property>
configuration>
2. core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop-master:9000/value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
configuration>
3. yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop-mastervalue>
property>
configuration>4. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>5. hadoop-env.sh
- 基础镜像OS
OS使用的是ubuntu14.04,java环境使用的openjdk7
FROM ubuntu:14.04
MAINTAINER zhangzy65@mail2.sysu.edu.cn
WORKDIR /root
- hadoop镜像
这个Dockerfile是在某个大神的基础上改动的(感谢)
FROM 192.168.31.85:5523/ubuntu-jdk7:14.04
MAINTAINER zhangzy65@mail2.sysu.edu.cn
WORKDIR /root
# install hadoop 2.7.4
COPY hadoop-2.7.2.tar.gz /root
RUN tar -xzvf hadoop-2.7.2.tar.gz && \
mv hadoop-2.7.2 /usr/local/hadoop && \
rm hadoop-2.7.2.tar.gz
# set environment variable
ENV JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
ENV HADOOP_HOME=/usr/local/hadoop
ENV PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
# ssh without key
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs
COPY config/* /tmp/
COPY gotty /bin/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/run-wordcount.sh ~/run-wordcount.sh
RUN chmod +x /tmp/start-master-hadoop.sh && \
chmod +x /tmp/start-worker-hadoop.sh && \
chmod +x /tmp/registerServer &&\
chmod +x /tmp/registerClient &&\
chmod +x ~/run-wordcount.sh && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh && \
chmod +x /bin/gotty
# format namenode
RUN /usr/local/hadoop/bin/hdfs namenode -formatContainer 运行脚本
- master 启动脚本
#!/bin/bash
#启动ssh服务
service ssh start
#获取容器IP
ip=`ifconfig eth0 | grep 'inet addr' | cut -d : -f 2 | cut -d ' ' -f 1`
sed -i "s/hadoop-master/$ip/" $HADOOP_HOME/etc/hadoop/core-site.xml
sed -i "s/hadoop-master/$ip/" $HADOOP_HOME/etc/hadoop/yarn-site.xml
#启动master节点hadoop
$HADOOP_HOME/sbin/start-dfs.sh &
$HADOOP_HOME/sbin/start-yarn.sh &
#启动hosts注册服务(这个服务是用自己go语言写的)
/tmp/registerServer &
/bin/gotty --port 8000 --permit-write --reconnect /bin/bash
- node 启动脚本
#!/bin/bash
service ssh start
#传进master的server名
sed -i "s/hadoop-master/$1/" $HADOOP_HOME/etc/hadoop/core-site.xml
sed -i "s/hadoop-master/$1/" $HADOOP_HOME/etc/hadoop/yarn-site.xml
#启动NodeManager和DataNode服务
/usr/local/hadoop/sbin/hadoop-daemon.sh start datanode &
/usr/local/hadoop/sbin/yarn-daemon.sh start nodemanager &
#启动向master注册hostname和ip的服务
/tmp/registerClient $1
#为了容器启动后不退出(如果脚本执行完,容器就结束了)
tail -f /dev/null
hadoop ymal 文件
- master yaml
master server 需要代理hadoop所有端口,端口可以去官网查询,这里基本都开启了
kind: ReplicationController
apiVersion: v1
metadata:
name: hadoop-master
namespace: zhang
spec:
replicas: 1
selector:
component: hadoop-master
template:
metadata:
labels:
component: hadoop-master
spec:
containers:
- name: hadoop-master
image: 192.168.31.85:5523/hadoop:2.7.2
command: ["/tmp/start-master-hadoop.sh"]
ports:
- containerPort: 3333
- containerPort: 8000
- containerPort: 8088
- containerPort: 50070
resources:
requests:
cpu: 100m
memory: 2000Mi
---
kind: Service
apiVersion: v1
metadata:
name: zzymaster
namespace: zhang
spec:
type: NodePort
ports:
- port: 9000
name: hdfs
- port: 19888
name: jobhistory
- port: 50010
name: hdfs2
- port: 50020
name: hdfs3
- port: 50075
name: hdfs5
- port: 50090
name: hdfs6
- port: 10020
name: mapred2
- port: 8030
name: yarn1
- port: 8031
name: yarn2
- port: 8032
name: yarn3
- port: 8033
name: yarn4
- port: 8040
name: yarn5
- port: 8042
name: yarn6
- port: 49707
name: other1
- port: 2122
name: other2
- port: 31010
name: hdfs7
- port: 8020
name: hdfs8
- name: terminal
port: 8000
nodePort: 31001
- name: cluster
port: 8088
nodePort: 31002
- name: information
port: 50070
nodePort: 31003
- name: register
port: 3333
targetPort: 3333
selector:
component: hadoop-master
- node yaml
启动hadoop最少需要分配一个G的内存,否则NodeManager无法启动
kind: ReplicationController
apiVersion: v1
metadata:
name: hadoop-worker
namespace: zhang
spec:
replicas: 1
selector:
component: hadoop-worker
template:
metadata:
labels:
component: hadoop-worker
spec:
containers:
- name: hadoop-worker
image: 192.168.31.85:5523/hadoop:2.7.2
command: ["/tmp/start-worker-hadoop.sh", "zzymaster"]
resources:
requests:
cpu: 100m
memory: 2000Mi
hadoop cluster 测试结果
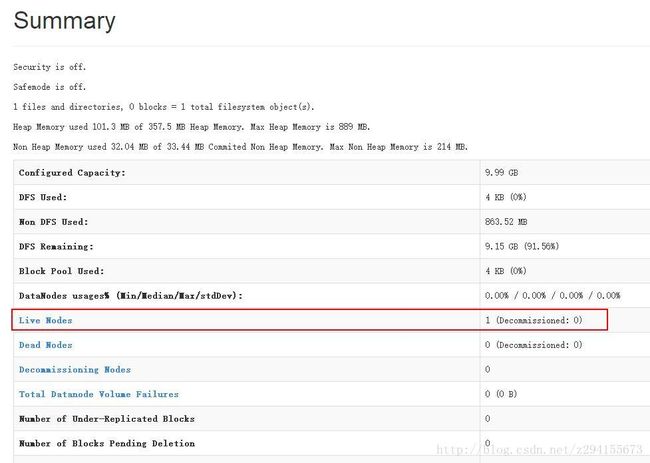
hadoop web

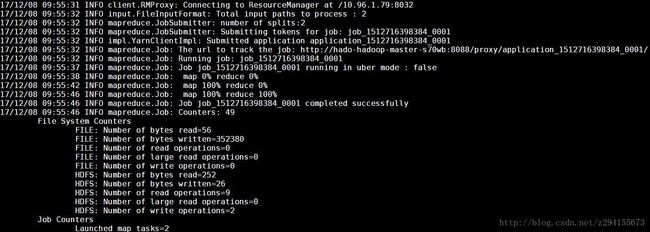
运行wordcount
总结
采用这种模式,hadoop集群可以通过k8s动态扩展,如果你有更好的方法,不吝赐教。