java基础面试题及答案
题目链接:http://www.jsondream.com/2016/12/04/java-interview-question.html
答案:
1. Arrays.sort实现原理和Collection实现原理
答:Arrays.sort():快排
Collections.sort() :MergeSort,后来变成了TimSort
2. foreach和while的区别(编译之后)
答:foreach针对确定次数;while不确定次数
3. 线程池的种类,区别和使用场景
答:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
4. 分析线程池的实现原理和线程的调度过程
答:多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力。
假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。
如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。
一个线程池包括以下四个基本组成部分:
A、线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
B、工作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
C、任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
D、任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
线程池技术正是关注如何缩短或调整T1,T3时间的技术,从而提高服务器程序性能的。它把T1,T3分别安排在服务器程序的启动和结束的时间段或者一些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。
线程池不仅调整T1,T3产生的时间段,而且它还显著减少了创建线程的数目,重用线程池中的线程。
按照优先级调度线程。
5. 线程池如何调优
答:使用线程池的核心问题在于应该使用多少线程。利特尔法则、拆分线程池
6. 线程池的最大线程数目根据什么确定
答:corePoolSize: tasks*tasktime个线程数
queueCapacity: corePoolSize/tasktime)*responsetime
maxPoolSize: (每秒任务-queueCapacity)*(每秒单个线程处理任务数量)
7. 动态代理的几种方式
答:代理模式的作用是:为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个客户不想或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。
动态代理:在程序运行时,运用反射机制动态创建而成。每一个动态代理类都必须要实现InvocationHandler这个接口。
jdk动态代理:jdk动态代理是由Java内部的反射机制来实现的,应用前提,必须是目标类基于统一的接口
cglib动态代理:动态代理框架,借助asm来实现的
8. HashMap的并发问题
答:HashMap是非线程安全的,可能造成死循环。
9. 了解LinkedHashMap的应用吗
答:LinkedHashMap是HashMap的一个子类,它保留插入的顺序,输入顺序和输出顺序相同。底层使用hash表和双向链表来存储。Eg。LRU缓存
10. 反射的原理,反射创建类实例的三种方式是什么?
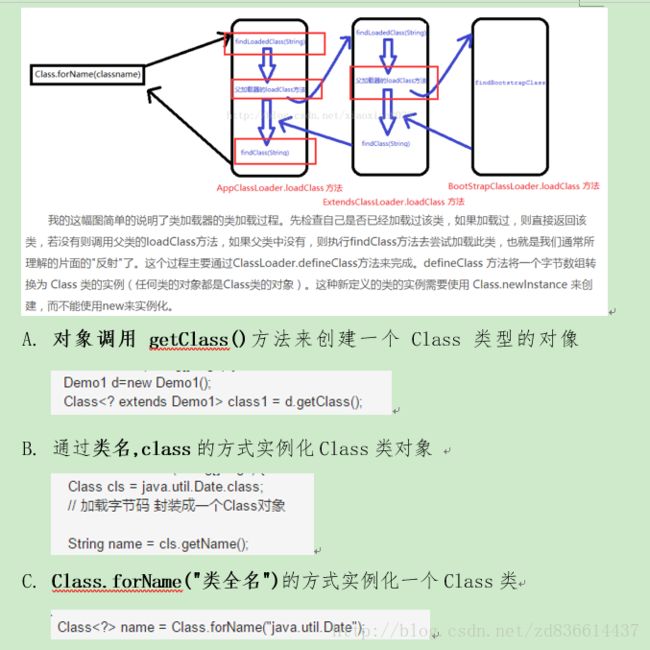
A. 对象调用getClass()方法来创建一个Class类型的对像
B. 通过类名,class的方式实例化Class类对象
C. Class.forName(“类全名”)的方式实例化一个Class类
11. cloneable接口实现原理,浅拷贝or深拷贝
cloneable接口:实现浅拷贝
浅拷贝(位拷贝):同一片内存空间。内存泄露、相互影响
深拷贝(值拷贝):重新分配内存空间,值一致
12. Java NIO (New IO)使用
非阻塞
在NIO中有几个核心对象需要掌握:缓冲区(Buffer)、通道(Channel)、选择器(Selector)。
缓冲区:在NIO库中,所有数据都是用缓冲区处理的
通道:通道是一个对象,通过它可以读取和写入数据,将数据从通道读入缓冲区,再从缓冲区获取这个字节
选择器:能检测一个或多个通道 (channel) 上的事件,并将事件分发出去。
13. hashtable和hashmap的区别及实现原理,hashmap会问到数组索引,hash碰撞怎么解决
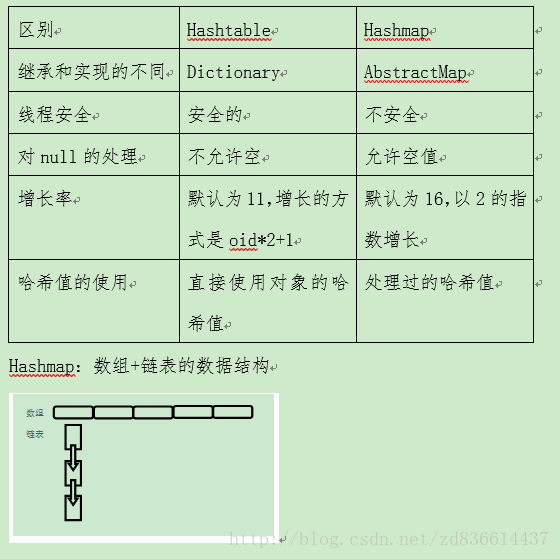
Put过程:
A. 先获取key对象的hashcode值进行处理
B. 将处理后的hashcode对table的length-1进行取余获得index即在数组中的索引位置
C. 然后对该位置的Entry进行判断,若该位置为空,那么插入新的Entry。
D. 若当前Entry不为空,那么根据key.equals()对该链表进行遍历,若是该key对象存在,则用新值代替旧值,否则在链表尾端插入新的Entry。
处理冲突的方式:开放地址法、拉链法、建立公共溢出区
14. arraylist和linkedlist区别及实现原理

区别 Arraylist Linkedlist
数据结构 动态数组 链表
随机访问 快 慢
Add、remove 慢 快
实现原理
ArrayList原理:
当元素超出数组内容,会产生一个新数组,将原来数组的数据复制到新数组中,再将新的元素添加到新数组中。
ArrayList:是按照原数组的50%来延长,构造一个初始容量为10的空列表
LinkedList原理:
不可以在初始化时候指定大小,每次向其中加入元素时候,容量自动加1。
15. 反射中,Class.forName和ClassLoader区别

16. String,Stringbuffer,StringBuilder的区别?
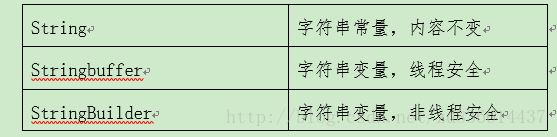
基本原则:
a.如果要操作少量的数据,用String ;单线程操作大量数据,用StringBuilder ;多线程操作大量数据,用StringBuffer。
b.不要使用String类的”+”来进行频繁的拼接
c.在构造 StringBuffer 或 StringBuilder 时应尽可能指定它们的容量。
17. 有没有可能2个不相等的对象有相同的hashcode
可能。结合直接寻址和链式寻址的哈希表,挂在一个链表上的hashcode值相等
18. 简述NIO的最佳实践,比如netty,mina
19. TreeMap的实现原理
TreeMap的实现是红黑树算法的实现,红黑树更是一颗自平衡的排序二叉树。
TreeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。
在TreeMap的put()的实现方法中主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
红黑二叉树而言它主要包括三大基本操作:左旋、右旋、着色。