人工智能中卷积神经网络基本原理综述
- 人工智能
- Artificial
- Intelligence
- 卷积神经网络
- Convolutional
- Neural
- Network
- Deep
- Learning
- 深度学习
- 机器学习
- AI
- 人工智能
- 深度学习
- 机器学习
人工智能Artificial Intelligence中卷积神经网络Convolutional Neural Network基本原理综述
人工智能(Artificial Intelligence,简称AI)的Deep Learning(深度学习)通过机器学习,把某一层的输出output当做下一层的输入input。在人工智能中,认为output是机器通过深度学习获得的某种“智慧”。深度学习(Deep Learning)通过神经网络把海量数据分组,然后形成组合分层结果,这样就形成了神经网络,通过层层的深度学习,最终获得理想的结果。人工智能的最终目的,是实现机器能够高效模拟人类大脑进行有效思考,在人类有挑战意义的领域,进化出超越人类认知和思考水平的人工智能。
卷积神经网络(Convolutional Neural Network,简称CNN)基本结构和原理
卷积神经网络是人工神经网络的一种,卷积神经网络是机器深度学习中的一种“前馈神经网络”,前馈是信号量的输入获得,到输出过程是往前方传导的,简言之信号是往前方传递的,所以称之为前馈。前馈用以神经网络的计算输出,不对神经网络调整,每一层中每一个神经元算出该层的输出并向下一层传递到输出层,进而计算出网络的输出结果。Back Propagation神经网络,即BP神经网络。反向传播训练神经网络权值和阈值的调整。网络前向传递计算输出结果时与正确结果存在误差,因此需要Back Propagation调整神经网络的前向计算过程。
卷积神经网络本质上是一种输入到输出的映射网络,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积神经网络加以训练,神经网络就具有输入输出之间的映射能力。卷积神经网络执行的是有监督训练,所以其样本集是由形如:(输入向量,理想输出向量)的向量对构成。这些向量对,可以是从实际运行系统中采集来。在开始训练前,所有的权重都应该用一些不同的小随机数进行初始化。小随机数用来保证神经网络不会因权值过大而进入饱和状态,从而导致训练失败,权值不同用来保证神经网络可以正常地学习。事实上,如果用相同的权值去初始化矩阵,则神经网络无能力学习。
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。卷积神经网络的神经元感知周围神经单元。
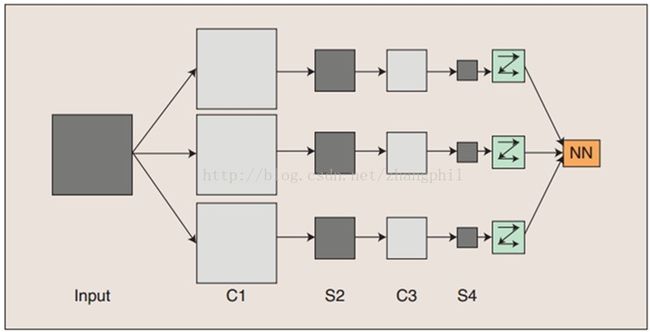
图像通过和三个可训练的滤波器和可加偏置进行卷积,滤波过程如图,卷积后在C1层产生三个特征映射图,然后特征映射图中每组的四个像素再进行求和,加权值,加偏置,通过一个Sigmoid函数得到三个S2层的特征映射图。这些映射图再进入滤波器得到C3层。这个层级结构再和S2一样产生S4。最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络,得到输出。
C层为特征提取层,每个神经元的输入与前一层的局部感受器(探测器)相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;S层是特征映射层,卷积神经网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。卷积运算可以使原信号特征增强,并且降低噪音,这种特征提取结构在识别时对输入样本有较高的畸变容忍能力。
卷积神经网络包含卷积层和池化层。卷积神经网络特征检测层通过数据训练进行学习,避免显示的特征提取,隐式地从训练数据中进行深度学习,同一特征映射面上的神经元权值相同,意味着可以并行训练学习。流行的分类方式多是基于统计特征,这意味着在进行分类前必须提取某些特征。然而,显式的特征提取并不容易,在一些实际问题中也并非总是可靠的。卷积神经网络,避免了显式的特征取样,隐式地从训练数据中进行学习。这使得卷积神经网络明显有别于其他基于神经网络的分类器,通过结构重组和减少权值将特征提取功能融合进多层感知器。
最小化数据预处理:通过感受野和权值共享减少神经网络需要训练的参数个数
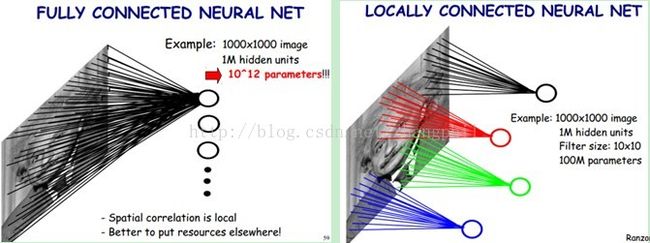
卷积神经网络降低参数数量,目的是降低计算负荷压力。其中一个策略是局部感知,以图像识别为例,如果把一个1000 X 1000的图像作为输入参数,每个隐层神经元都连接感知图像的每一个像素点,如果全连接,那数据就太多,1000x1000x1000000=10^12,计算压力太大,所以要考虑一种有效的方式。局部感知可以解决这个问题,局部感知基于以下基本假设:人类的大脑在认知周围世界时候,是从局部到全局的。任一图像中,某一特定像素点和局部周围的像素关系紧密,而和较远距离的全局像素关系不是非常密切,即平面图像的空间联系是局部的。每一个神经元,没有必要对全局的像素点都要认知,一不必要,二是资源浪费。每一个神经元都无须对全局图像做感受,每个神经元只感受局部的图像,然后在更高层,这些感受到不同局部的神经元综合起来就可以得到全局信息。
神经网络中的参数经过局部感知后,有些时候数据集可能仍然非常大。此时可以考虑第二种方案,权值共享。假设图像中有1000X1000=1000000(一百万)个像素点,经过处理,每个神经元100(卷积操作)个特征相同,那么此时要处理的1000000数据集问题就缩减为处理100的问题,数据量大大降低。局部感受野是10X10,隐层每个感受野只需要和这10X10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来降低四个0(数量级)。
隐层的每一个神经元都连接10X10个像素点,即每一个神经元存在10 X 10=100个连接权值参数。如果每个神经元这100个参数是相同的呢?也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有100个参数,不管隐含层的神经元个数有多少,两层间的连接我只有100个参数,这就是卷积神经网络权值共享。
权值共享降低了网络的复杂度,避免了特征提取和分类过程中模型重建开销。权值共享的方式:假设针对图像,设定100个提取(学习)特征,这100个提取特征与图像中的不同区域及位置没有关系,是打算要深度学习的特征。图像的一块(局部感受野)作为层级结构中最低层的输入,信号再依次传输到不同的层,每层通过一个数字滤波器(或探测器)去获取感知数据的最显著的特征。
举例,假设从一个图像中取出8 X 8的像素样本中首先训练机器学习到的特征作为探测器,然后再回归到图像中的任一区域。举例,假设从图像中选取一小块8 X 8的区域,通过对8 X 8的小区域学习到的特征与1000 X 1000的图形做卷积,从而就得到该完整图像中任一位置的有价值的输出值,激活值。
下图展示了3 X 3的卷积核在5 X 5的图像上做卷积的过程。每一次卷积均以固定的算式算出激活值,假设激活值越大越符合要求的条件,那么通过这种筛选方式就可以筛出需要的图像:
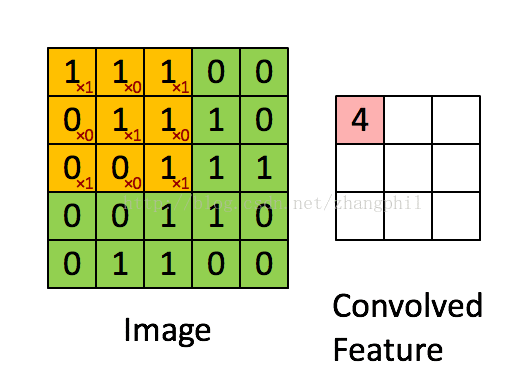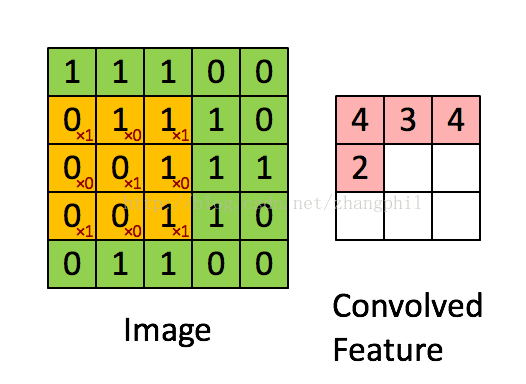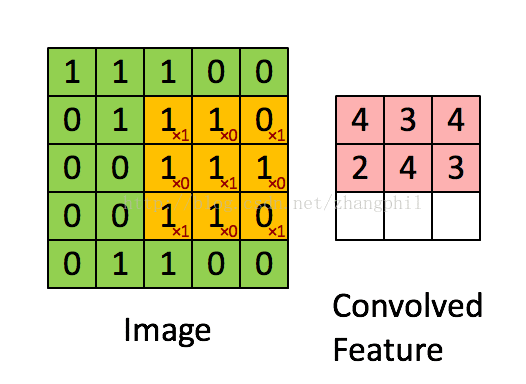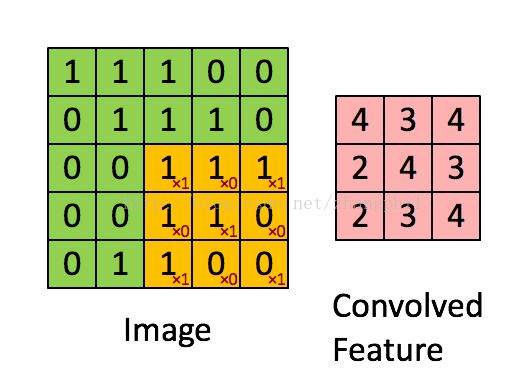
卷积神经网络中的多核卷积
实际的运用中,往往要多层卷积,多层卷积越往层级高的地方,特征越具有全局意义,单层卷积学习到的特征更多的是局部性特征。如果用100个参数时,只有一个10 X 10的卷积核,这样的特征提取是不充分的。这样只提取一种特征,现实中需要提取多种特征。假如一种滤波器,也就是一种卷积核,去提取图像的一种特征,比如某个方向边缘。那需要提取不同的特征,就需要加多几种滤波器(探测器)。所以当加到100种滤波器,每种滤波器的参数不一样,表示它提出输入图像的不同特征,例如不同的边缘。这样每种滤波器去卷积完整图像就得到对图像不同特征的映射Feature Map。因此100种卷积核就有100个Feature Map。这100个Feature Map就组成了一层神经元。100种卷积核乘以每种卷积核共享100个参数=100x100=10K,每一层也就是1万个参数。
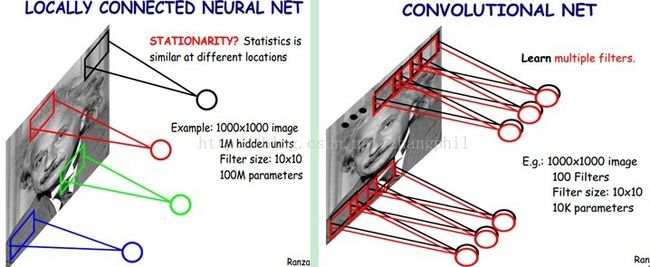
不同的颜色代表不同的卷积核,也即不同的颜色表达不同的滤波器,每一个卷积核算出的结果形成一幅全新的图像。
再假设针对图像设定更多的卷积核,比如32个,这也就意味着可以学习32个特征。多个卷积核时候,32个卷积核,生成32幅图像。这32幅图可以认为是完整图像的不同通道。
通过卷积算出特征后,开始利用特征进行分类,理论上可以用所有提取到的特征训练分拣器,但这里计算机要处理的数据太多太多。比如一个96 X 96像素图像,假设已经学习得到400个定义的8 X 8输入的特征,每一个特征和图像卷积都会得到一个 (96−8+1)×(96−8+1)=7921维的卷积特征,由于有 400 个特征,所以每个样例就会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过三百多万特征输入的分类器任务量太大,并且容易出现过拟合 (over-fitting)。
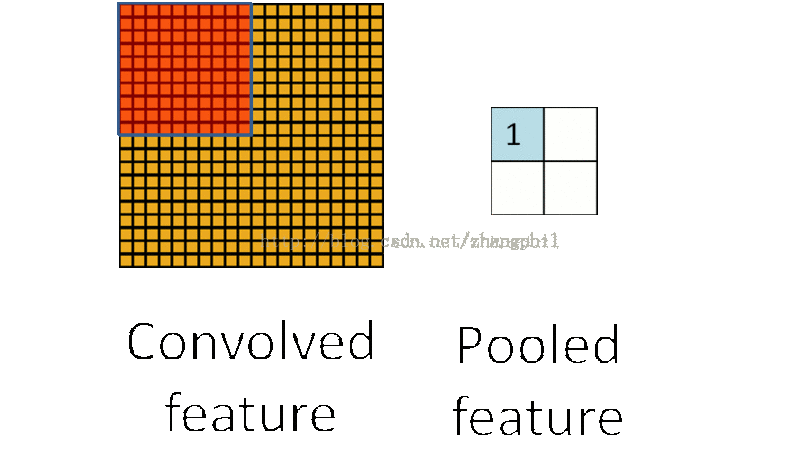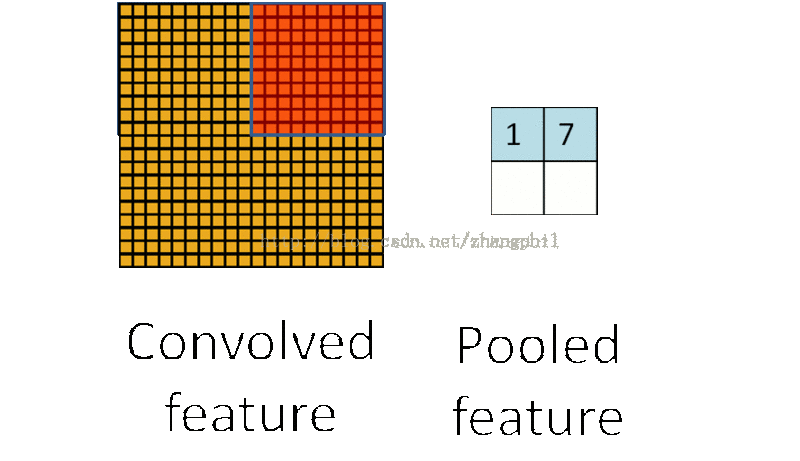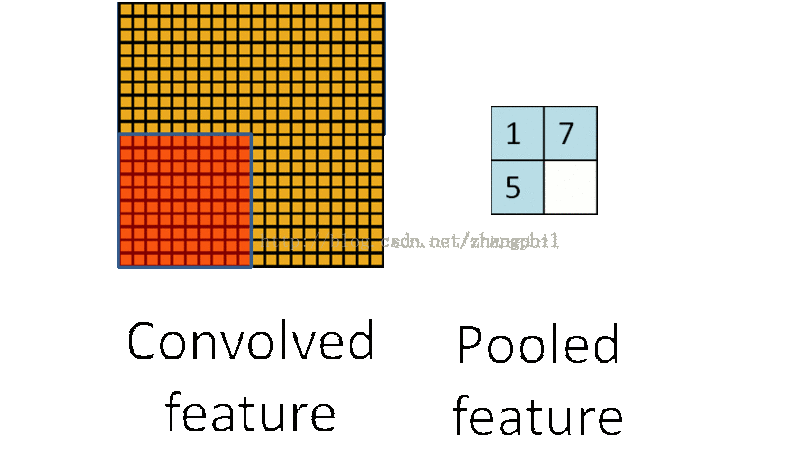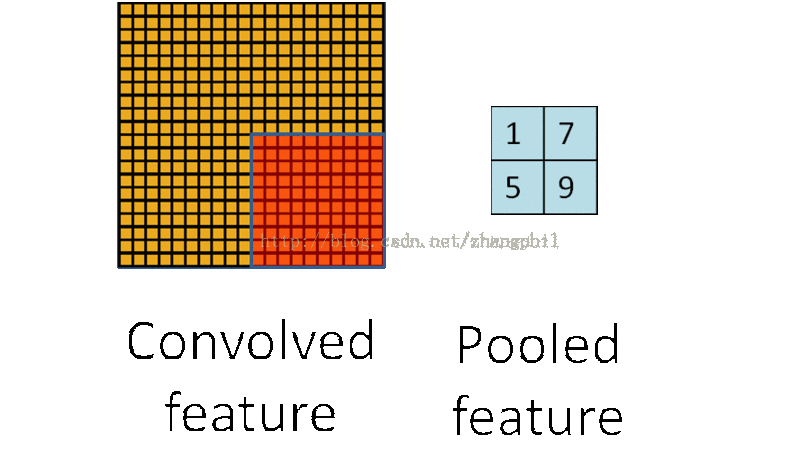
卷积后的特征值,在完整图像的不同区域极有可能仍然适用,因此为了描述一个大图像的特征,可以针对不同位置的特征进行聚合统计。比如可以计算图像中某一块区域的平均值(或者最大值),这些概略性的特征统计,第一可以大大降低需要计算的维度,第二还可以从一定程度上改善拟合结果。这种聚合的计算过程就叫做池化 (Pooling),或称之为平均池化或者最大池化 (依据计算池化的方式):