Hive开窗函数总结
背景:
平常我们使用 hive或者 mysql时,一般聚合函数用的比较多。但对于某些偏分析的需求,group by可能很费力,子查询很多,这个时候就需要使用窗口分析函数了~
注:hive、oracle提供开窗函数,mysql8之前版本不提供,但Oracle发布的 MySQL 8.0版本支持窗口函数(over)和公用表表达式(with)这两个重要的功能!
版本:Hive 1.1.0 + cdh5.13.0
一、介绍
分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化!到底什么是数据窗口?后面举例会详细讲到!
1. 基础结构:
分析函数(如:sum(),max(),row_number()...) + 窗口子句(over函数)
2. over函数写法:
over(partition by cookieid order by createtime) 先根据cookieid字段分区,相同的cookieid分为一区,每个分区内根据createtime字段排序(默认升序)
注:不加 partition by 的话则把整个数据集当作一个分区,不加 order by的话会对某些函数统计结果产生影响,如sum()
3. 测试数据:
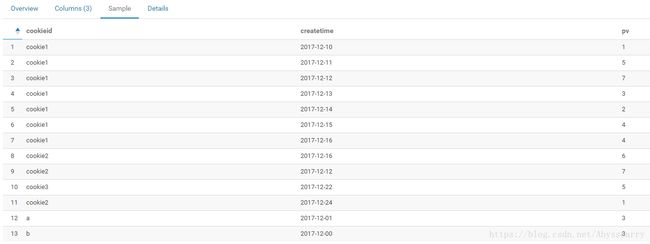
测试表test1只有三个字段 cookieid、createtime、pv
4. 窗口含义:
SELECT cookieid,createtime,pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1, -- 默认为从起点到当前行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv3, --当前行+往前3行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv4, --当前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv5 ---当前行+往后所有行
FROM test1;
结果:
cookieid createtime pv pv1 pv2 pv3 pv4 pv5
a 2017-12-01 3 3 3 3 3 3
b 2017-12-00 3 3 3 3 3 3
cookie1 2017-12-10 1 1 1 1 6 26
cookie1 2017-12-11 5 6 6 6 13 25
cookie1 2017-12-12 7 13 13 13 16 20
cookie1 2017-12-13 3 16 16 16 18 13
cookie1 2017-12-14 2 18 18 17 21 10
cookie1 2017-12-15 4 22 22 16 20 8
cookie1 2017-12-16 4 26 26 13 13 4
cookie2 2017-12-12 7 7 7 7 13 14
cookie2 2017-12-16 6 13 13 13 14 7
cookie2 2017-12-24 1 14 14 14 14 1
cookie3 2017-12-22 5 5 5 5 5 5
注:这些窗口的划分都是在分区内部!超过分区大小就无效了
相信大家看了后就会明白,如果不指定ROWS BETWEEN,默认统计窗口为从起点到当前行;如果不指定ORDER BY,则将分组内所有值累加;
关键是理解 ROWS BETWEEN 含义,也叫做window子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无边界,UNBOUNDED PRECEDING 表示从最前面的起点开始, UNBOUNDED FOLLOWING:表示到最后面的终点
–其他AVG,MIN,MAX,和SUM用法一样
二、SUM 函数
select cookieid,createtime,pv,
sum(pv) over(PARTITION BY cookieid ORDER BY createtime) as pv1
FROM test1

首先 PARTITION BY cookieid,根据cookieid分区,各分区之间默认根据字典顺序排序,ORDER BY createtime,指定的是分区内部的排序,默认为升序
我们可以清晰地看到,窗口函数和聚合函数的不同,sum()函数可以根据每一行的窗口返回各自行对应的值,有多少行记录就有多少个sum值,而group by只能计算每一组的sum,每组只有一个值!
其中sum()计算的是分区内排序后一个个叠加的值,和order by有关!
如果不加 order by会咋样:
select cookieid,createtime,pv,
sum(pv) over(PARTITION BY cookieid) as pv1
FROM test1
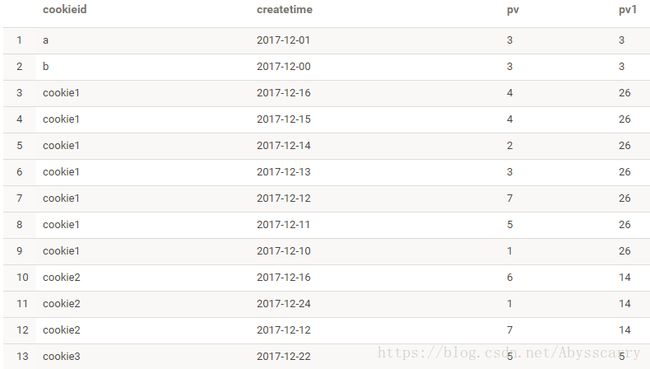
可以看到,如果没有order by,不仅分区内没有排序,sum()计算的pv也是整个分区的pv
注:max()函数无论有没有order by 都是计算整个分区的最大值
三、NTILE 函数
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
注1:如果切片不均匀,默认增加第一个切片的分布
注2:NTILE不支持ROWS BETWEEN
SELECT cookieid,createtime,pv,
NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile1, --分组内将数据分成2片
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile2, --分组内将数据分成3片
NTILE(4) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile3 --将所有数据分成4片
FROM test1

用法举例:
统计一个cookie,pv数最多的前1/3的天:
SELECT cookieid,createtime,pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS ntile
FROM test1;
取 ntile = 1 的记录,就是我们想要的结果!
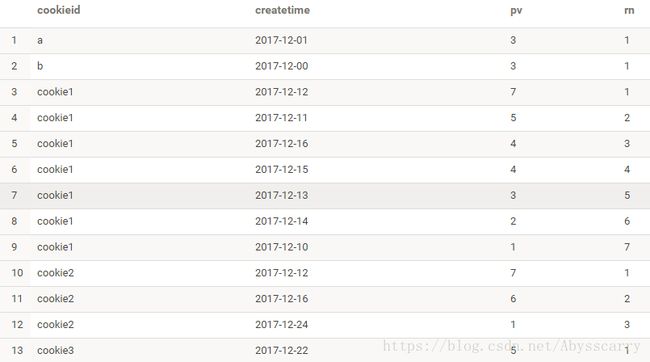
四、ROW_NUMBER 函数
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列
ROW_NUMBER() 的应用场景非常多,比如获取分组内排序第一的记录、获取一个session中的第一条refer等。
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn
FROM test1;
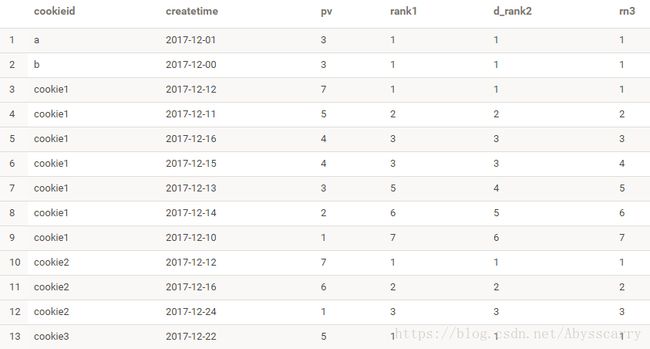
五、RANK 和 DENSE_RANK 函数
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
我们把 rank、dense_rank、row_number三者对比,这样比较清晰:
SELECT cookieid,createtime,pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS d_rank2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM test1
六、CUME_DIST 函数
cume_dist 返回小于等于当前值的行数/分组内总行数
比如,我们可以统计小于等于当前薪水的人数,所占总人数的比例
SELECT cookieid,createtime,pv,
round(CUME_DIST() OVER(ORDER BY pv),2) AS cd1,
round(CUME_DIST() OVER(PARTITION BY cookieid ORDER BY pv),2) AS cd2
FROM test1;

注:cd1没有partition,所有数据均为1组!
七、PERCENT_RANK 函数
percent_rank 分组内当前行的RANK值-1/分组内总行数-1
注:一般不会用到该函数,可能在一些特殊算法的实现中可以用到吧
SELECT cookieid,createtime,pv,
PERCENT_RANK() OVER(ORDER BY pv) AS rn1
from test1

八、LAG 和 LEAD 函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
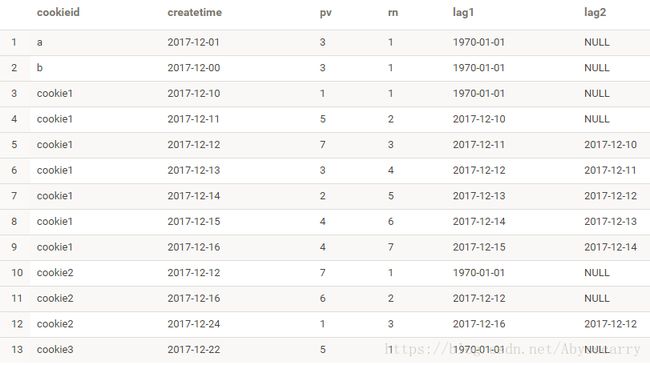
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01') OVER(PARTITION BY cookieid ORDER BY createtime) AS lag1,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS lag2
FROM test1;
LEAD 函数则与 LAG 相反:
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
九、FIRST_VALUE 和 LAST_VALUE 函数
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS first
FROM test1;

LAST_VALUE 函数则相反:
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值
这两个函数还是经常用到的(往往和排序配合使用),比较实用!
参考文章:http://lxw1234.com/archives/category/hive