MYSQL基础命令
一.
1.存储引擎:使用不同的存储机制, 索引技巧, 锁定水平, 并且最终提供广泛的不同的功能;这些不同的技术以及配套的相关功能在MYSQL被称为存储引擎, 也叫表类型。
2.利用数据库练习的时候,全部大写,这是一种规范, 例如;
3.虽然MYSQL支持多个存储引擎, 但小企业及个人工作者只需了解INNODE存储引擎即可。该引擎是第一个提供外键约束的表引擎。
其优势:提供了良好的事务管理能力, 崩溃修复能力, 和并发控制;
缺点:其读写效率较差, 占据的数据空间相对较大;
4.MYSQL支持的数据类型: 数字类型, 字符串类型(字符), 日期和时间类型;
数字类型: int , small int, medium int , big int, float, double .....;
字符串类型: char varchar(*), text(适合存储长文本), blob(适合存储二进制);
在这里说一下 char类型和varchar的区别,char类型存储要比varchar快,但varchar比char类型要节约空间。
举例:
char(20),你的数据无论是几个字节,都要占用这20个字节的空间。但char类型检索的时候速度较快。
varchar(20), 你的数据最大字节数是20个字节, 但小于20字节的,占几个字节,就用几个字节。
还有 set, enum;
5. CREATE DATABASE 数据库名称;
名称不能有单独的数字组成, 最长可为64个字符, 不可使用MYSQL作为数据库名称。
windows 下对大小写并不敏感, linux下对大小写敏感;
6. SHOW DATABASES;查看数据库;
7.USE 数据库名;选择数据库;
8. DROP DATABASE 数据库名称 删除数据库。
应谨慎操作, 没有恢复的可能(除非事先备份);
二.数据表相关操作
1.建表 CREATE TABLE 表名(
..... ..... ..... ,
..... .......... ,
..... ..........);
属性解释:
1. unsigned 无符号,全为正数,数据范围扩大一倍
2.zerofill 填充0, 一般配合位数使用, int(3), 不够三位左侧补零
3.auto_increment 自增, 一般id使用。
4.null 默认属性 这一列的值可以为空
5.not null 这一列的值不允许为空
6.default 默认值
示例:
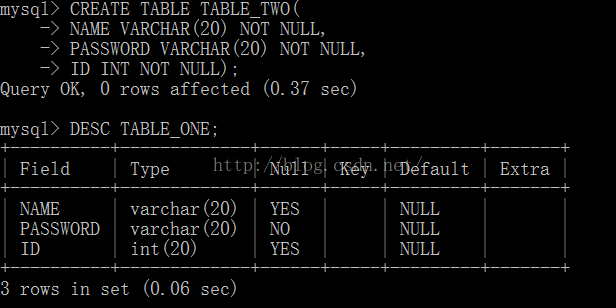
在这里说一下int(20)的含义, 这个20百度解释的是最大位数,但经过实测如果某一列为int(3),那么123可以存进去, 123456789也可以存进去。那么这个int(20)的20是什么意思呢,其实这里的20与长度无关,只是在不够20位的时候前面补零,但不够20位的时候我们也没有看到零啊,那是因为mysql默认不显示前面补得零。
创建的时候 ID INT(3) ZEROFILL NOT NULL就可以显示零了。
2.查看表结构 SHOW COLUMNS FROM 表名 FROM 数据库名;
DESCRIBE 表名 (列名);
3.重命名表结构 RENAME TABLE 旧名 TO 新名;
4.删除表结构 DROP TABLE (IF EXISTS) 表名;
5.清空表数据 DELETE FROM 表名;
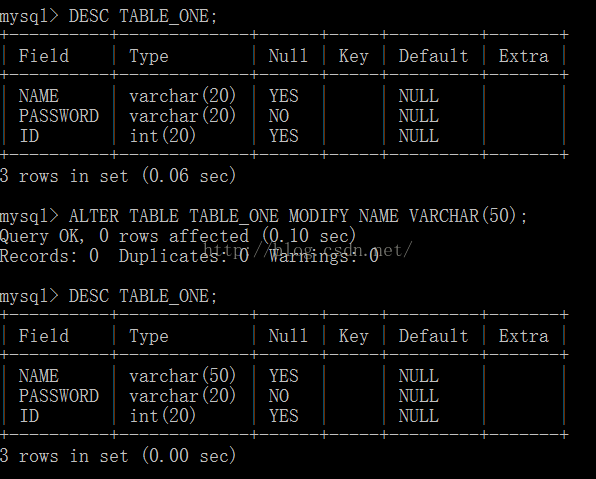
6.修改表结构 ALTER TABLE 表名 接下来的一系列操作
{
ADD, MODIFY, DROP, RENAME, CHANGE
}
示例修改表结构:
三. 数据表相关操作:
1.插入信息:INSERT INTO 表名 VALUES(*****) //这是插入所有列的信息。
INSERT INTO 表名(某一列) VALUES(*****) //只插入某一列,其余信息为空;
举例:

2.修改数据记录: UPDATE 表名 SET 某列=新值 WHERE 某条件;

3.删除记录 DELETE FROM 表名 WHERE 条件;
4.查询记录 SELECT * FROM 表名; //查找全部记录;
SELECT 某列名称(查询多列时用,隔开) FROM 表名 WHERE 某条件 ///满足某条件下的查询;
SELECT DISTINCT 某列名称(查询多列时用,隔开) FROM 表名 WHERE 某条件 ///列表去重;
SELECT * FROM 表名 ORDER BY 某列(根据某列的值排序) DESC\ASC(降序或者升序); ///根据排序结果输出 NULL的值默认为最小
SELECT * FROM 表名 ORDER BY 某列(根据某列的值排序) DESC\ASC(降序或者升序) LIMIT n(限制n条语句输出);
SELECT * FROM 表名 ORDER BY 某列(根据某列的值排序) DESC\ASC(降序或者升序) LIMIT n, m; ///从第n-1条数据输出, 共输出m条记录;
SELECT * FROM 表名 WHERE 某列的名称 LIKE ('h%'); ///模糊查询, 匹配头一个字母是h的记录, %匹配一个或多个字符, -只能匹配一个字符;
GROUP BY 必须放在ORDER BY 之前, 一旦出现GROUP则不能使用WHERE, 而HAVING则可以用于列出条件代替WHERE
5.使用聚合函数查询:
SELECT COUNT(*) FROM 表名;

SELECT SUM(某列的值) FROM 表名; ///某个字段的取值综合;
SELECT AVG(某列的值) FROM 表名; ///某个字段的平均值;
SELECT MAX(某列的值) FROM 表名;
SELECT MIN(某列的值) FROM 表名; ///某个字段的最大最小值;
CONCAT("A",""B);CONCAT函数用来连接两个字符串
6.外连接和内链接
1、内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符)。包括相等联接和自然联接。
内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。例如,检索 students和courses表中学生标识号相同的所有行。
下面是比较复杂的的一个子查询。该查询将两个表联系在了一起,先是查询出第二大人口大国是谁,然后用聚合函数查询属于该国家的城市有多少个。

2、外联接。外联接可以是左向外联接、右向外联接或完整外部联接。
在 FROM子句中指定外联接时,可以由下列几组关键字中的一组指定:
1)LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
2)RIGHT JOIN 或 RIGHT OUTER JOIN
右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
3)FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
3、交叉联接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
FROM 子句中的表或视图可通过内联接或完整外部联接按任意顺序指定;但是,用左或右向外联接指定表或视图时,表或视图的顺序很重要。有关使用左或右向外联接排列表的更多信息,请参见使用外联接。
例子:
-------------------------------------------------
a表 id name b表 id job parent_id
1 张3 1 23 1
2 李四 2 34 2
3 王武 3 34 4
a.id同parent_id 存在关系
--------------------------------------------------
1) 内连接
select a.*,b.* from a inner join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
2)左连接
select a.*,b.* from a left join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
3 王武 null
3) 右连接
select a.*,b.* from a right join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
4) 完全连接
select a.*,b.* from a full join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
3 王武 null
7.联合查询
SELECT * 列名 FROM 表名
UNION
SELECT * 列名 FROM 表名;
举例:
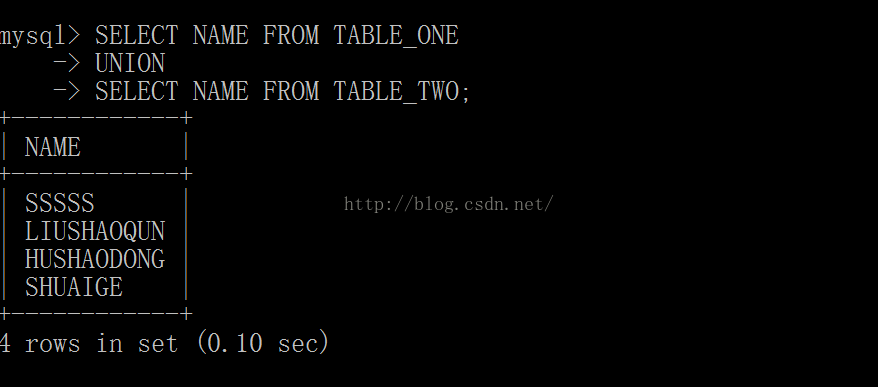
UNION 同时也是sql语句注入的一种特别好用的手段。
导入数据库命令行
\.. 文件位置\文件名称

查看服务器的基本信息 \s
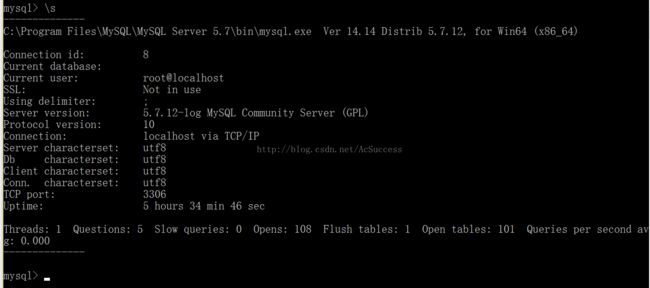
Server characterset: utf8
//服务器字符集
Db characterset: utf8
//数据库字符集
Client characterset: utf8
//客户端字符集
Conn. characterset: utf8
//客户端连接字符集
Collation-server = utf8_general_ci
//服务器和数据库校验字符集
查看数据库字符集 SHOW CREATE DATABASE 数据库名称;
查看表字符集 SHOW CREATE TABLE 表名;
索引分主键索引和普通索引两种。
主键索引只有一个, 而普通索引可以有多个,添加索引的目的是为了加快搜索速度,减少遍历数目。
如图:创建了一个id带有主键索引的表
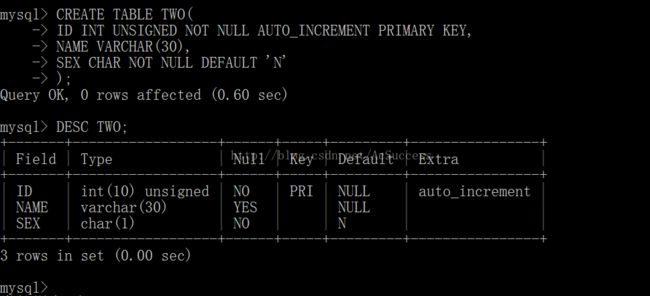
主键索引在开始设计的时候,就会存在,没必要后期再加,后期添加的只能是普通索引。
查看表中的索引:
SHOW INDEX FROM 表名;
添加普通索引:
ALTER TABLE 表名 ADD INDEX 索引名(要添加索引的列);
删除普通索引:
ALTER TABLE 表名 DROP INDEX 索引名;
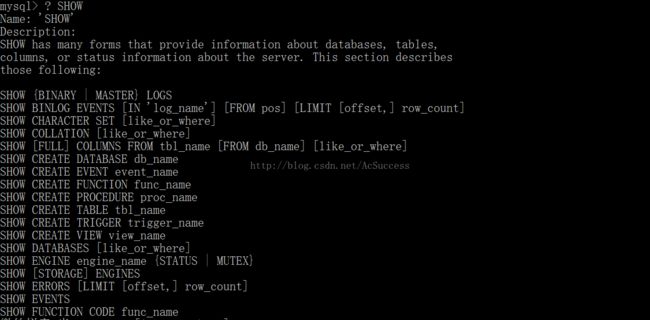
如果临时忘记某个命令的语法是什么样子的,忘记怎么写了?
这时可采用 ?命令名称 来查看此命令的各种语法
如图:查看SHOW的语法