Zero-Shot Learning论文阅读笔记(第一周)
Zero-Shot Learning读书笔记(第一周)
- 前言:
- 第一篇:零次学习(Zero-Shot Learning)入门:
- 原文链接
- ZSL的概念、解释
- ZSL需要解决的问题
- 常用数据集
- 基础算法介绍
- ZSL中存在的问题以及解决方法
- 有关ZSL的一些其他的概念
- 第二篇:Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
- 摘要
- 算法简介
- 直接属性预测DAP:
- 间接属性预测 IAP:
- 实验结果
- 引用
- 第三篇:An embarrassingly simple approach to zero-shot learning
- 摘要
- 算法的背景
- 算法流程
- 数据集
- 实验结果
- 引用
- 第四篇:Transductive Multi-View Zero-Shot Learning
- 摘要
- 算法简介
- 实验结果
- 引用
- 第五篇:Semantic Autoencoder for Zero-Shot Learning
- 摘要
- 算法简介
- 数据集和实验结果
- 引用
前言:
近期因加入学校教研室,教授安排的研究方向是Domain adaptation 或Zero-Shot Learning ,我选择的是后者,在此之前虽然我对ZSL有初步的了解,但是仅限于此。今后我将每周更新5-10篇ZSL方向的相关博客或者论文的学习笔记,在此分享出来望共同探讨学习,如有理解上的偏差或错误恳请各位大佬及时指出,谢谢!
第一篇:零次学习(Zero-Shot Learning)入门:
原文链接
https://zhuanlan.zhihu.com/p/34656727?spm=5176.9876270.0.0.399ce44aXsg7cN
ZSL的概念、解释
- 解释:
Zsl希望我们的模型对其从没有见过的类别进行分类,让机器聚类推理能力。其中零次(Zero_shot)是指对于要分类的类别对象,一次也不学习。
-
形象解释:
假设小暗(纯粹因为不想用小明)和爸爸,到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小暗安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小暗有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小暗根据爸爸的提示,在动物园里找到了斑马。 -
实现思路:(转化为一般的图片分类问题,且只考虑图片分类问题)
训练集数据X_tr 及其标签 Y_tr ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致;
测试集数据 X_te及其标签 Y_te ,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一致;
训练集类别的描述 A_tr,以及测试集类别的描述 A_te ;我们将每一个类别 y_i∈ Y ,都表示成一个语义向量 a_i∈ A 的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
在ZSL中,我们希望利用X_tr和Y_tr来训练模型,而模型能具有识别X_te的能力,因此模型需要知道所有类别的描述A_tr和A_te -
Questions:
类别的描述A到底是怎么获取的:
人工专家定义护着海量的附加数据集自动学习 -
ZSL definition:
利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使模型有效。
https://blog.csdn.net/tianguiyuyu/article/details/81948700
ZSL需要解决的问题
获取合适的类别描述A
目前主要是自然语言处理(NLP)方法,难度大,进展慢
建立一个合适的分类模型
方法多,比较容易出成果
常用数据集
- Animal with Attributes(AwA)官网:Animals with Attributes
提出ZSL定义的作者,给出的数据集,都是动物的图片,包括50个类别的图片,其中40个类别作为训练集,10个类别作为测试集,每个类别的语义为85维,总共有30475张图片。但是目前由于版权问题,已经无法获取这个数据集的图片了,作者便提出了AwA2,与前者类似,总共37322张图片。 - Caltech-UCSD-Birds-200-2011(CUB)官网:Caltech-UCSD Birds-200-2011
全部都是鸟类的图片,总共200类,150类为训练集,50类为测试集,类别的语义为312维,有11788张图片。 - Sun database(SUN)官网:SUN Database
总共有717个类别,每个类别20张图片,类别语义为102维。传统的分法是训练集707类,测试集10类。 - Attribute Pascal and Yahoo dataset(aPY)官网:Describing Objects by their Attributes
共有32个类,其中20个类作为训练集,12个类作为测试集,类别语义为64维,共有15339张图片。 - ILSVRC2012/ILSVRC2010(ImNet-2)
利用ImageNet做成的数据集,由ILSVRC2012的1000个类作为训练集,ILSVRC2010的360个类作为测试集,有254000张图片。它由 4.6M 的Wikipedia数据集训练而得到,共1000维。
Zero-Shot Learing问题数据集分享(GoogleNet 提取)
基础算法介绍
- 建立特征空间和语义空间的映射:因为ZSL面临的是一个语义分类的问题,即对于测试集样本X_te分类y_i∈Y,又因为语义描述A和类别Y一一对应,所以只需要关心测试样本X_te的特征空间和语义空间的映射。
- 可以归纳为一个分类问题,最常用的方法是岭回归(均方误差加范数约束)
min‖X_tr W-A_tr ‖^2+ηΩ(W)
Ω为2范数约束。 - 岭回归有效的基础:训练集类别语义A_tr与测试集类别语义A_te之间存在密切联系。
- 如何建立更好的模型:需要了解ZSL中存在着哪些和传统分类的差异。
ZSL中存在的问题以及解决方法
- 领域漂移问题(domain shift problem)
- 问题:同一类别语义中具体实体的差别可能很大。样本的特征维度比语义维度大很多,所以在映射的过程中会丢失信息。
- 解决方法:将映射到语义空间中的样本,再重建回去。以让学习到的映射能保留更多的信息。将目标函数改写
min‖X_tr-W^T A_tr ‖^2+λ‖WX_tr-A_tr ‖^2
- 枢纽点问题(Hubness problem)
- 问题:在高维空间中,某些点会成为大多数点的最邻近点。
- 解决方法:建立语义空间到特征空间的映射:
min‖X_tr-A_tr W‖^2+ηΩ(W)
还可以:使用生成模型,比如子编码器,生成测试集的样本,不存在K-NN的操作,所以不存在hubness problem。
- 语义间隔(semantic gap)
- 问题:样本的特征通常是视觉特征,而语义表示的却是非视觉的,这容易导致样本在特征空间所构成的流型与语义空间中流型不一致——直接学习两者之间的映射变得困难。
- 解决方法:将类别的语义表示调整到样本的流型上,即用类别语义表示类别语义即可。
有关ZSL的一些其他的概念
-
直推式学习(Transductive setting)
在训练模型的时候,我们或许已有测试集的数据,只是没有拿到测试集的样本标签。因此可以通过迁移学习的方法,利用测试集数据的到一些测试类别的先验知识。 -
泛化的ZSL(generalized ZSL)
在现实的问题中,拿到的样本也可能属于训练类别,因此在测试是,同时加入训练类别。
第二篇:Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
摘要
研究了测试集和训练集不相交时的对象分类问题。
在此文章发表之前,没有对于毫无关联的训练集和测试集进行抽样检测的工作,也即是只能对训练集所包含的样本进行分类。作者希望能提出一种不需要任何目标数据类别信息的对象分类方法(无直接训练集)。
提出高维特征的概念,这里的高维特征包括但不限于形状、颜色、地理位置,而且是可以事先学习的。(they can be pre-learned, e.g. from image datasets unrelated to the cur- rent task. )然后,可以根据它们的属性表示(高维语义)检测新类,而不需要新的学习。
实验表明,利用属性层确实可以构建一个不需要目标类训练图像的学习对象检测系统。
该工作在一定程度上实现了迁移学习。
算法简介
- 假设:
( x 1 , l 1 ) , . . . ( x n , l n ) (x_1,l_1),...(x_n,l_n) (x1,l1),...(xn,ln)为训练样本 x x x和相对于的类别标签 l l l的成对数据,一共有 n n n对,属于 k k k个类别,用 Y = { y 1 , y 2 , . . . , y k } Y=\{y_1,y_2,...,y_k\} Y={y1,y2,...,yk}表示。 - 目标:
学习一个分类器 f : X → Z f:X\to Z f:X→Z,其中 Z = { z 1 , . . . , z L } Z=\{z_1,...,z_L\} Z={z1,...,zL}给测试分为 L L L类,其中 Y Y Y是训练集中包含的类别, Z Z Z是测试集中包含的类别,两者没有交集。
换言之,我们需要建立 Y Y Y和 Z Z Z之间的关系。 - 流程:
-
- 因为在训练时没有关于Z的信息,所以文章建立一个人工定义的属性层 A A A,该属性层要较好的表现训练样本的类别信息且应该是高维的。比如“有斑纹”,“有尾巴”等。
- 该属性层的作用:将基于图片的低维特征的分类器转化为高维语义特征。使得训练出来的分类器分类能力更广,有突破类别边界的能力。
- 如何进行迁移学习,构造属性层呢?文章提出了DAP和IAP两种模型。
直接属性预测DAP:
在样本和训练类标之间加入一个属性表示层 A A A,利用监督学习的方式,通过训练集 Y Y Y对应的属性向量进行训练可以学到从样本 x x x到生成 A A A的属性参数 β \beta β。在测试阶段,可以得到测试样本对应的属性向量 A A A,对比测试集 Z Z Z类别的属性向量,即可得到对于不可见数据的预测类别,从而实现迁移学习。

对于DAP模型,可以用概率图模型的知识进行建模。首先,每一个训练类别y都可以表示为长度为m的属性向量ay=(a1,…,am),且该属性向量为二值属性。
之后,可以通过监督学习,得到image-attribute层的概率表示,p(a|x),它是样本x对于所有am的后验概率的乘积。在测试时,每一个类别z可以用一个属性向量az表示。利用贝叶斯公式即可得到概率公式 p ( z ∣ x ) p(z|x) p(z∣x)。
p ( z ∣ x ) = ∑ a ∈ { 0 , 1 } M p ( z ∣ a ) p ( a ∣ x ) = p ( z ) p ( a z ) ∏ m = 1 M p ( a m z ∣ x ) p ( z | x ) = \sum _ { a \in \{ 0,1 \} ^ { M } } p ( z | a ) p ( a | x ) = \frac { p ( z ) } { p ( a ^ { z } ) } \prod _ { m = 1 } ^ { M } p ( a _ { m } ^ { z } | x ) p(z∣x)=a∈{0,1}M∑p(z∣a)p(a∣x)=p(az)p(z)m=1∏Mp(amz∣x)
由于类别Z是未知的,所以可以假设它的先验概率相同,即每个p(z)的值是相同的,因此可以去除掉公式中的p(z)。对于先验概率p(a),可以使用训练时学习到的属性层值得平均值表示,作者称在实验中,该值固定为0.5时,可以得到comparable result.最终由X->Z的推测,可以使用MAP prediction:
f ( x ) = argmax l = 1 , … , L ∏ m = 1 M p ( a m z l ∣ x ) p ( a m z l ) f ( x ) = \underset { l = 1 , \ldots , L } { \operatorname { argmax } } \prod _ { m = 1 } ^ { M } \frac { p ( a _ { m } ^ { z _ { l } } | x ) } { p ( a _ { m } ^ { z _ { l } } ) } f(x)=l=1,…,Largmaxm=1∏Mp(amzl)p(amzl∣x)
也就是说,DAP可以理解为一个三层模型:第一层是原始输入层,例如一张电子图片(可以用像素的方式进行描述);第二层是p维特征空间,每一维代表一个特征(例如是否有尾巴、是否有毛等等);第三层是输出层,输出模型对输出样本的类别判断。在第一层和第二层中间,训练p个分类器,用于对一张图片判断是否符合p维特征空间各个维度所对应的特征;在第二层和第三层间,有一个语料知识库,用于保存p维特征空间和输出y的对应关系,这个语料知识库是事先人为设定的。
DAP的缺点:
- 算法引入了中间层,核心在于尽可能得判定好每幅图像所对应的特征,而不是直接去预测出类别;因此DAP模型在判定属性时可能会做得很好,但是在预测类别时却不一定;
- 无法利用新的样本逐步改善分类器的功能;
- 无法利用额外的属性信息(如Wordnet等)
间接属性预测 IAP:
在训练阶段,和传统的监督训练一样,只是在其标签 Y Y Y上,学习一层属性表示层 A A A,在测试阶段,利用标签层 Y Y Y和属性层 A A A就可以推出测试数据的类别 Z Z Z.

实验结果
DAP的准确率达到40.5%,IAP的准确率为27.8%。下图为每个不同属性的预测准确率。
 Quality of individual attribute predictors (trained on train classes, tested on test classes), as measured by by area under ROC curve (AUC). Attributes with zero entries have constant values for all test classes of the split chosen, so their AUC is undefined.
Quality of individual attribute predictors (trained on train classes, tested on test classes), as measured by by area under ROC curve (AUC). Attributes with zero entries have constant values for all test classes of the split chosen, so their AUC is undefined.
引用
Lampert C H , Nickisch H , Harmeling S . Learning to detect unseen object classes by between-class attribute transfer[C]// 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009.
第三篇:An embarrassingly simple approach to zero-shot learning
摘要
文章描述了一种关于ZSL的新方法,且只需要一行代码就可以实现,但是它能够在标准数据集上胜过当时最先进的方法。
该方法基于一个更通用的框架,该框架将特征(features)属性(attributes)和类(classes)之间的关系建模为一个具有两个线性层的网络,其中顶层的权重不是通过学习得到的,而是由环境给出的。通过将这些方法转换为域适应(domain adaptation)方法,文章进一步提供了这类方法的泛化误差的学习边界。
算法的背景
- 基础框架:
语义属性(高维属性):对应多个共享对象,实现抽象概括。这些属性在多个类之间共享,可以被机器检测到,也可以被人类理解。 - 挑战:如何创造以一个组合属性或者高维概念signature,来对每一个类打标签。
- Zero-shot Learning 两阶段本质:训练和推理
- 训练:对属性训练,获取属性的相关知识。
- 推理:将这些知识用于在一组以前未见过的类中对实例进行分类
文章指出了目前情况下推理过程中存在的弊端:许多方法盲目地假设所有属性都传递相同数量的信息,并且能够以相同的精度进行预测,因此,它们在推理规则中被平均地使用。然而,这些假设在现实世界中很少成立。
- 文章所作出的改进点:提出了一个能够集成这两个阶段的框架,克服了像前面描述的那样需要做出不切实际的假设。引入的这个框架是基于将特征、属性和类之间的关系建模的两层线性模型。第一层包含描述特征和属性之间关系的权重,并在训练阶段学习。第二层对属性和类之间的关系建模,并使用类的指定属性签名进行固定。由于可见类和不可见类是不同的,所以第二层是可互换的。
- 文章算法的优点:
- 模型的性能与现有技术相当,甚至更好。
- 模型在训练和推理阶段都是有效的。
- 非常容易实现:一行代码用于学习,另一行代码用于训练。
算法流程
文章使用签名举证 S S S和训练实例的学习矩阵 V V V,从特征空间映射到属性空间。在推理阶段,文章使用矩阵 V V V,加上不可见类 S ′ S' S′的label,得到了最终的线性模型 W ′ W' W′。算法框架概要如下图所示:

详细流程暂略
数据集
包括动物、场景、对象等等…
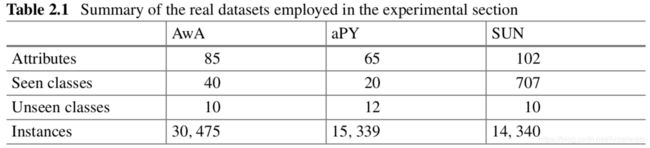
实验结果
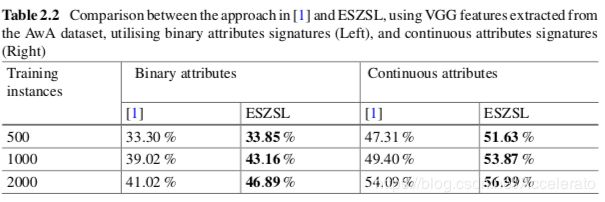
[1]:Akata,Z.,Perronnin,F.,Harchaoui,Z.,Schmid,C.:Label-embeddingforattribute-basedclas- sification. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2013)

引用
Romera-Paredes B , Torr P H S . An embarrassingly simple approach to zero-shot learning[C]// Proceedings of the 32nd international conference on Machine learning (ICML '15). JMLR.org, 2015.
第四篇:Transductive Multi-View Zero-Shot Learning
摘要
文章指出ZSL的现状与不足之处:大多数现有的ZSL都是通过在带注释的训练集和不带注释的不同类的目标数据集之间共享的中间层语义表示来实现转移学习。从底层特征空间到语义表示空间的映射是从辅助数据集学习而来的,在进行应用时没有对目标数据集进行自适应。
文章具体阐述了传统方法的两个限制,并给出了相应的解决方法:
首先,由于具有不相交且可能不相关的类,将辅助数据集(训练集)学习的映射语义函数在直接应用于目标数据集时会存在偏差。也就是领域漂移(domain shift )问题【注:domain shift 这一概念由该文章首次提出】,并提出了一个新的框架——直推式多视图嵌入transductive multi-view embedding来解决这个问题。
以AwA数据集为例,现在尝试通过训练“是否有尾巴”这一特征。斑马是40个训练集中的有尾巴的十个类中的一个,图中蓝色为预测特征,红色为原型特征。从图中不难看出,虽然斑马都是“有尾巴的”,但是他们之间也存在很大的差异,而对于训练集的猪类来说,虽然猪有尾巴,但是猪的原型与其他成员实例之间有非常大的差距,这就是领域漂移问题,导致了传统ZSL很难预测成功。而采用本为给出的直推式多视图嵌入方法,则可以取得较好的效果。

第二个限制是原型稀疏性(prototype sparsity)问题,即对于每个目标类,在给定语义表示的情况下,通常只有一个原型可用于零样本学习。针对这一问题,文章提出了一种新的异构多视图标签传播 novel heterogeneous multi-view hypergraph label propagation
方法,用于在换向嵌入空间中进行零样本学习。它有效地利用了不同语义表示提供的互补信息,以一致的方式利用了多个表示空间的流形结构。
以下图(b)和(c)为例,对于传统ZSL,一个类只有一个标签,然而同一类中不同个体之间的差异往往是巨大的。这样做的显然会导致较大的类内差异和类间相似性。即使单个原型集中在语义表示空间的类实例之间,现有的ZSL分类器仍然难以分配正确的类标签。也就是说,每个类一个原型不足以表示类内部的可变性或帮助消除类间相重叠特征所带来的歧义。

文章通过大量的实验证明新方法的优越性:
该方法较好的解决了领域漂移的的问题,利用了多种不同语义表征之间的互补性。在对三个标准图像和视频数据集的对比实验中发现,利用文中提出的方法实验效果显著优于现有方法。
算法简介
暂略
实验结果
暂略
引用
Fu Y , Hospedales T , Xiang T , et al. Transductive Multi-view Zero-Shot Learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(11):1-1.
第五篇:Semantic Autoencoder for Zero-Shot Learning
摘要
文章指出了现有的零样本学习主要是学习从特征空间(feature space)到语义层次空间(semantic embedding space)的映射函数,这种映射函数只关心被训练类的语义表示或分类。当应用于测试数据时,因为没有训练数据,所以ZSL会遇到一个普遍的问题:领域漂移问题(domain shift problem).
文章提出了一种新方法:基于学习的语义自编码方案Semantic AutoEncoder (SAE)。文章的核心思想是
自编码器在进行编码时,像现有的ZSL模型一样,将视觉特征向量投射到目标空间中。然而,解码器施加了一个额外的约束,即程序必须能够重建原始的视觉特性。
也就是说,
SAE在编码和和解码时,使用了原始数据作为约束,即编码后的数据能够尽可能恢复为原来的数据。
文章提出的编码器和解码器时线性同步的,且取得了较好的效果:在6个基准数据集上的大量实验表明,文章提出的SAE优于现有的ZSL模型,具有较低的计算成本。此外,当SAE应用于监督聚类问题时,它也优于当时最先进的算法。
算法简介
- 下图是一个最简单的自编码器框架,其中 X X X为样本, S S S为自编码器的隐层,这个隐层即可以表示原样本的标签,也有着清晰的语义,X^是隐层还原样本的表示。

- 语义自编码器的构成:
文章所介绍的自编码器中的隐层只有一层,而且维数要小于训练样本的属性的维数。设输入层到隐层的映射为 W W W,隐层到输出层的映射为 W ∗ W^* W∗, W W W和 W ∗ W^* W∗是对称的,即有 W ∗ = W T W^*=W^T W∗=WT,由于文章的目标是输入和输出尽可能相似,所以有 min W , W T ∥ X − W T W X ∥ F 2 \operatorname { min } _ { W , W ^ { T } } \| X - W ^ { T } W X \| _ { F } ^ { 2 } minW,WT∥X−WTWX∥F2
同时,文章希望隐层可以包含语义,也就是说能表示类标签or样本属性。所以加入 W X = S WX=S WX=S的约束条件,其中 S S S是事先约定好的语义向量。这也是自编码器从非监督学习向监督学习的转变。
此时目标函数可以表示为
min w , w T ∥ X − W T W X ∥ F 2 s.t. W X = S \operatorname { min } _ { w , w ^ { T } } \| X - W ^ { T} W X \| _ { F } ^ { 2 } \quad \text { s.t. } \quad W X = S minw,wT∥X−WTWX∥F2 s.t. WX=S

具体目标函数最优化求见过程相关的方程函数解析暂略
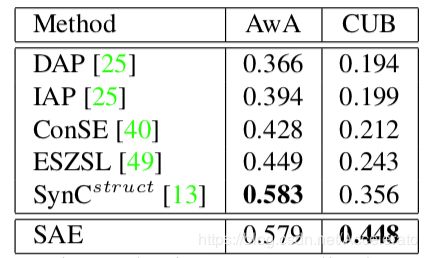
数据集和实验结果
本文使用的6个数据集如下所示:
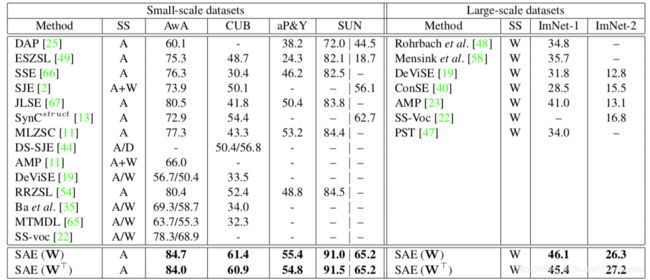
不同算法的实验结果如下,可见本文给出的效果最好。
引用
原文:https://arxiv.org/pdf/1704.08345.pdf
Kodirov E , Xiang T , Gong S . Semantic Autoencoder for Zero-Shot Learning[J]. 2017.
参考:
https://blog.csdn.net/u011070272/article/details/73498526