编程语言复习笔记
编程语言复习笔记
在期末复习的时候将上课课件以及课本内容进行了整理。
-
- 编程语言复习笔记
- 一、课程内容简介&&绪论
- 1.1 语言评价准则
- 1.2 语言的分类
- 1.2.1 过程式语言
- 1.2.2 面向对象语言
- 1.2.3 函数式语言
- 1.2.4 声明式语言
- 1.2.5 脚本语言
- 1.3 语言的实现:抽象机器
- 二、语法与语义
- 2.1 概述
- 2.2 语法的形式化定义
- 2.2.1 上下文无关文法(形式语言内容)
- 2.2.2 巴恩斯范式 BNF
- ==BNF的推导==
- 可能造成二义性的原因
- 解决二义性:
- 扩展BNF——EBNF
- 2.3 属性文法
- 背景概述
- 一个例子引入属性概念
- 属性文法的具体定义
- 例子的详细解析
- 属性文法的计算——语法树的装饰过程
- 2.4动态语义
- 常用的三种语义
- 2.4.1 操作语义
- 思想及步骤
- 一个详细例子
- 2.4.2 指称语义
- 基础&&思想&&步骤
- 一个详细例子
- 与操作语义的相同与差异
- 2.4.3 公理语义
- 基础&&思想
- 形式定义
- 最弱前置条件
- 一个详细例子(还是熟悉的那个)
- 2.5 本章小结
- 1.语法:BNF和EBNF
- 2.静态语义:属性文法及其计算
- 3.动态语义:操作语义、指称语义和公理语义
- 三、名字、绑定和作用域
- 3.1 名字
- 3.2 变量
- 名字:有极少数变量没有
- 地址:与变量关联的内存地址
- 别名:两个变量能够访问相同的内存地址
- 类型:决定了变量的取值范围和操作集合
- 数值:相关联的存储单元的内容
- 3.3 绑定
- 3.3.0 绑定时间:绑定发生的时间称为绑定时间
- 3.3.1 绑定的类型以及类型绑定(数据类型)
- 3.3.2存储绑定和生存期
- 3.3.3 静态变量
- 3.3.4 栈动态变量
- 3.3.5 显式堆动态变量
- 3.3.6 隐式堆动态变量
- 3.3.7 绑定——C语言例子
- 3.4 作用域
- 3.4.1 静态作用域
- 3.4.2 动态作用域
- 作用域小结
- 3.5 引用环境——静态
- 3.6 引用环境——动态
- 3.7 命名常量
- 四、数据类型
- 4.1 概述
- 4.2 基本数据类型
- 4.3 字符串类型
- 4.4 数组类型
- 4.5 记录类型(结构体)
- 4.6 指针和引用类型
- 4.7 抽象数据类型
- 4.8 类型检测
- 五、表达式与赋值语句
- 5.1 概述
- 5.2 算数表达式
- 5.2.1算数表达式的分类
- 5.2.2 优先级规则
- 5.2.3 副作用
- 5.2.4 操作符重载
- 5.2.5 类型转换
- 5.3 关系表达式和布尔表达式
- 5.3.1 关系表达式
- 5.3.2 布尔表达式
- 5.4 短路求值(17年选择题)
- 5.5 赋值语句
- 六、语句级控制结构(填空题考过)
- 6.1 概述
- 6.2 选择语句——双路
- 6.3 选择语句——多重
- 6.4 迭代语句
- 6.4.1 计数控制循环
- 6.4.2 逻辑控制循环
- 6.4.3 基于用户自定义的循环控制机制
- 6.4.4 基于数据结构的循环
- 七、子程序
- 7.1 概述
- 编程语言的两个抽象过程
- 7.2 子程序的基本原理
- 7.2.1基本定义
- 7.2.2 参数
- 7.2.3 子程序的类别
- 7.3 子程序的设计问题(8个)
- 7.3.1 局部变量
- 7.3.2 嵌套子程序
- 7.3.3 传参
- 7.3.4 参数的类型检测
- 7.3.5 子程序作为参数
- 7.3.6 子程序的重载
- 7.3.7 泛型(多态)子程序
- 7.3.8 闭包
- 7.1 概述
- 一、课程内容简介&&绪论
- 编程语言复习笔记
一、课程内容简介&&绪论
- 语法与语义
- 名字、绑定和作用域
- 数据类型
- 表达式与赋值语句
- 控制语句
- 子程序
- 高级语言属性
1.1 语言评价准则
- 可读性
- 整体简单性
- 正交性
- 语法设计:语言的形式能否反映语句的意义
- 可写性
- 简单性和正交性:较少量的基本结构和一套组合基本结构的一致规则 (即正交性),比简单地提供大量基本结构好得多
- 对抽象的支持
-
- 过程抽象:子程序实现排序,多处使用
- 数据抽象:用结构node表现二叉树的节点
- 表达性:较简捷程序实现大量计算
- 可靠性:任何情况下都能按设计的那样执行
- 类型检查
- 静态类型检查:编译时检查,例如JAVA
- 动态类型检查:运行时检查,例如JavaScript
- 异常处理:拦截运行时错误的措施,例如除零操作
- ==别名==:两个或者多个不同的名称访问同一个内存单元
- 成本(培训成本啊,编写成本啊啥的),重点成本:
-
- 用语言编程程序的成本
- 可靠性差的成本
- 维护程序的成本
- 其他特性(常用语言都有):
- 可移植性:JAVA是可移植的,C语言需要重新编译
- 普遍性:C语言是一种通用的语言,可用于系统开发和应用程序
- 定义良好性:JAVA有良好的官方文档
1.2 语言的分类
对于计算过程可以有多种不同看法,由此产生了不同的计算模型(范型),基于不同计算范型产生了不同的语言类(语言范型)
主要范型有:
- 过程式语言(命令式语言)
- 函数式语言
- 面向对象语言
- 声明式语言(Declarative)
- 脚本语言
1.2.1 过程式语言
计算看成一系列操作的执行 ,基本计算元素是一组基本操作。计算在一个环境里进行,操作的效果就是改变环境的状态。
语言提供一组描述组合操作的手段,提供的抽象手段是定义新操作(定义过程)
写程序是描述操作执行的顺序过程,描述状态和状态的变化
1.2.2 面向对象语言
计算看成是一批独立对象相互作用的效果 。
面向对象语言提供:
-
- 描述(定义)对象及其行为的机制
- 描述对象之间相互作用的机制
比较纯的面向对象语言:
- 基于类 的语言:Java
- 基于 对象 的语言:JavaScript,通过原型概念定义新的类似对象
1.2.3 函数式语言
计算看成对数据的函数变换。
基本计算元素是一组基本函数,提供各种函数组合机制(复合,函数选择),抽象手段是定义新函数(允许递归定义)
1.2.4 声明式语言
基本思想是:只描述需要做什么,不描述怎么做
包含:
-
- 逻辑式语言
- 关系式语言
- 基于约束的语言
1.2.5 脚本语言
- 提供一批高级数据结构,提供灵活的变量、函数、对象等机制
- 采用解释方式实现,使用灵活方便
- 许多脚本语言提供了高级的文本处理功能
- 例:shell、PHP、Perl、Python
1.3 语言的实现:抽象机器
机器语言可以看做是计算机硬件的“抽象”
高级语言可看作是一种“抽象计算机” 的机器语言
常用的实现方式:编译和解释
- 编译:将程序翻译成机器语言,翻译慢,执行快

- 解释:对程序进行解释执行,无翻译,执行慢

- 混合实现:将程序翻译成中间语言,并解释执行,较小翻译代价,较快执行速度
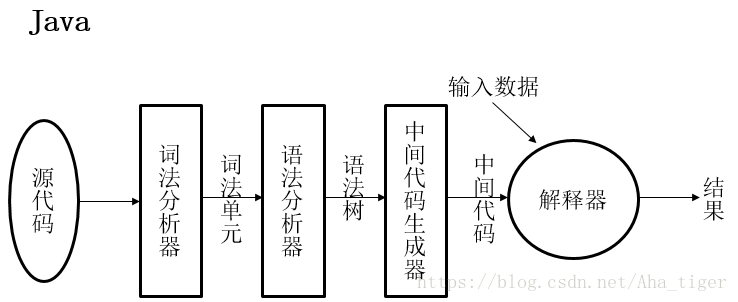
- 编译:将程序翻译成机器语言,翻译慢,执行快
二、语法与语义
2.1 概述
- 描述语言的难处之一:所有人都必须能理解这种概述
- 类似自然语言,程序语言描述也分为语法和语义(考点):
-
- 语法:语言的表达式、语句和程序单元的形式
- 语义:这些表达式、语句和程序单元的意义
- 语言是句子的集合
- 句子是由字符表中的字符组成的串
2.2 语法的形式化定义
2.2.1 上下文无关文法(形式语言内容)
定义:上下文无关文法G是一个四元组(V,T,P,S)
- V——非终结符的非空有穷集合,为了定义语言而引入的辅助符号
- T——终极符的非空有穷集合,可以出现在语言的句子中,且 V∩T=ϕ V ∩ T = ϕ
- S—— S∈V S ∈ V , 为文法G的开始符号
- P——形如 α−>β α − > β 的产生式的非空有穷集合,其中 α∈V,β∈(V∪T)∗ α ∈ V , β ∈ ( V ∪ T ) ∗
2.2.2 巴恩斯范式 BNF
BNF提供了两类符号:终结符和非终结符
终结符:被定义的语言的符号,最终可以出现在程序中
非终结符:是为了定义语言的语法而引入的辅助符号
一个非终结符表示语言中的一个语法类:
< stmt >表示语句
- < expr >表示表达式
一个语言的BNF语法定义由一组产生式(或规则)组成,其本质是一个上下文无关文法
产生式的形式是:
左部 → → 右部
- 左部:总是一个非终结符
- 右部:用 | 分隔的一个或多个终结符和非终结符的序列。<…>用于表示非终结符
一个简单的文法:
< program > ->< stmts >
< stmts >->< stmt >|< stmt >;< stmts >
< stmt >->< var >=< expr >
< var >->a|b|c|d
< expr>->< term>+< term>|< term>-< term>
< term>->< var>|const
==BNF的推导==
推导是一个或一系列产生式的应用
句型:由开始符号经过推导得到的字符串 例如:a=b+< var >
句子:只有终结符的句型 例如:a=b+const
最左推导:每次总是替换句型最左边的非终结符
最右推导:每次总是替换句型最右边的非终结符
推导树:推导的树形结构表示,例如
a=b+const的语法树:
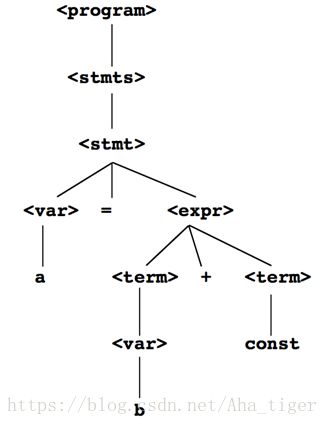
- 最左推导就是树的最左遍历
最右推导就是树的最右遍历
关于推导的练习 PPT
考虑下列BNF: < expr >-> < expr >+< expr >| < var >; < var >->a|b|c ;
写出其最左推导:
< expr >
=>< expr>+< expr>
=>< expr>+< expr>+< expr>
=>< var>+< expr>+< expr>
=>a+< expr>+< expr>
=>a+< var>+< expr>
=>a+b+< expr>
=>a+b+< var>
=>a+b+c写出其最右推导:
< expr>
=>< expr>+< expr>
=>< expr>+< expr>+< expr>
=>< expr>+< expr>+< var>
=>< expr>+< expr>+c
=>< expr>+< var>+c
=>< expr>+b+c
=>< var>+b+c
=>a+b+c画出推导树:

存在两颗推导树,说明存在二义性。
二义性:文法生成的句型有两个或多个语法树,例子为上图,在这里是结合性造成的。
可能造成二义性的原因
优先级
结合性
二义性:< expr> -> < expr> + < expr> | const
非二义性:< expr> -> < expr> + const | const
++与+:a+++b
if-then-else:
if < cond> then if < cond> then < stmt> else < stmt>
最后的else与谁匹配
解决二义性:
- 用==不同的非终结符==表示==不同的优先级==
- 低优先级的符号先出现
//例子
//二义性:
< expr>->< expr>< op>< expr>|const
< op>->+|-|*|/
//非二义性:
< expr>->< expr>< op_L>< term>|< term>
< term>->< term>< op_H>const|const
< op_L>->+|-
< op_H>->*|/
//非二义性(允许括号):
< expr>->< expr>< op_L>< term>|< term>
< term>->< term>< op_H>< factor>|< factor>
< factor>->const|’(‘< expr>’)’
< op_L>->+|-
< op_H>->*|/
==设计无二义性的BNF的练习(PPT)==
- 请设计一个描述布尔逻辑表达式的无二义性的BNF(考虑优先级和结合性)
- n请设计一个描述if语句的无二义性的BNF
1)左结合+(or,and,not)优先级依次变高
< expr>->< expr> or < term> | < term>
< term>->< term> and < factor> | < factor>
< factor>-> not < factor> | true | false
2)?
< stmt>->< matched>|< unmatched>
< matched>->if< logic_expr> then < matched> else < matched>|any non-if statement
< unmatched>->if then | if then < matched> else < unmatched>
扩展BNF——EBNF
! EBNF只是增加了可读性和可写性,并没有增加表达能力
- 用圆括号()表示多个选项:< expr>->< expr>( + | - ) < term>
- 用方括号[ ]表示可选部分:< if_stmt>->if< cond> then< stmt> [ else < stmt> ]
- 用花括号{ }表示0次或者多次重复:< ident>->letter{ letter|digit }
1)BNF 和 对应的EBNF
//BNF
< expr> -> < expr> + < term>
| < expr> - < term>
| < term>
< term> -> < term> * < factor>
| < term> / < factor>
| < factor>
//EBNF (左结合)
< expr> -> < term> {(+ | -) < term>}
< term> -> < factor> {(* | /) < factor>}
2)将 EBNF 转为 BNF
//EBNF
S->A{bA}
A->a[b]B
B->(c|d)e
//BNF
S->SbA|A
A->aB|abB
B->ce|de
==设计描述布尔逻辑表达表达式的EBNF==
//二义性
< bExpr>->< bExpr>(and|or)< bExpr>
< bFactor>-> not< bFactor>| true | false
//非二义性
< bExpr>->[< bExpr> or]< bTerm>
< bTerm>->[< bTerm> and]< bFactor>
< bFactor>->(not< Factor>|true|false)
2.3 属性文法
背景概述
- 有些语言的结构特点很难用BNF描述
- 类型兼容性规则:例如java中浮点数不能给整型变量赋值,反之则可以,BNF很难实现
- 变量声明规则:变量必须在使用前声明
- 这类语言规则成为==静态语义规则==
- 与程序执行过程中的意义只有间接关系
- 在编译时进行分析
- Knuth在1968年提出了==属性文法==
- 添加静态语义属性的上下文无关文法
- 既可以描述语法,也可以描述静态语义
一个例子引入属性概念
例子:形如id = id+id的赋值语句
- id的类型是整数或者浮点数
- +号两边的id的类型必须一样
- =左边id的类型必须匹配右边表达式的类型
- 右边的表达式的==类型==必须匹配它的==期望类型==
BNF:
< ass_stmt>->< var>=< expr>
< expr> ->< var> +< var>
< var> -> id
为了满足上述要求,需要:
- 表达式或变量的==实际类型==
- 表达式的==期望类型==
这些需求解的信息成为语义属性,简称属性
属性文法的具体定义
属性文法是具有以下附加特性的文法
每个文法符号X都有一个属性集A(X):
- ==综合属性==:沿语法树自底向上传递的语义信息==(-> 是综合属性)==
- ==继承属性==:沿语法树自顶向下、从左到右传递语义信息==(赋值= 是继承属性)==
- ==本质属性==:叶子结点(即终结符)的综合属性
每条产生式有一个==计算属性==的语义函数集
- 每条产生式有一个==分析静态语义==可能为空的谓词函数集
例子的详细解析
例子:形如id = id+id的赋值语句
- id的类型是整数或者浮点数
- +号两边的id的类型必须一样
- =左边id的类型必须匹配右边表达式的类型
- 右边的表达式的==类型==必须匹配它的==期望类型==
BNF:
< ass_stmt>->< var>=< expr>
< expr> ->< var> + < var>
< var> -> id
属性
==实际类型==:与< var>、< expr>相关的综合属性;id的本质属性
==期望类型==:与< expr>相关的继承属性
属性文法
< ass_stmt>->< var>=< expr>
函数:==< expr>.expected_type = < var>.actual_type==
函数是从左到右继承属性==(赋值= 是继承属性)==
因为< var>在声明时已经指定了类型,所以< expr>的期望类型要符合那个指定的类型
< expr> -> < var>[1] + < var>[2]
函数:==< expr>. actual_type = < var>[1].actual_type==
函数是有底向上的综合属性==(-> 是综合属性)==
谓词: < var>[1]. actual_type == < var>[2].actual_type
< expr>. expected_type == < expr>.actual_type
< var> -> id
- 函数:< var>.actual_type = id.actual_type
id.actual_type = lookup(符号表,id)
< var>.actual_type是自底向上的综合属性(->)
id.actual_type 是叶子节点的本质属性
属性文法的计算——语法树的装饰过程
- 只有综合属性:自底向上
- 只有继承属性:自顶向下(从左到右)
- 两者都有:自底向上和自顶向下
还是最初的例子id=id+id,其BNF为:
< ass_stmt>->< var>=< expr>
< expr> ->< var> +< var>
< var> -> id
对应的语法树为:
2.4动态语义
动态语义:编程语言中表达式、语句和程序单元的意义
常用的三种语义
- 操作语义
- 指称语义
- 公理语义
2.4.1 操作语义
思想及步骤
- 思想:用抽象的方法描述语句的执行效果,以免语义依赖于语言实现所用的具体计算机
- 步骤:
- 设计一个抽象机及其状态
- 定义每一个语句对状态的改变(或抽象机指令)
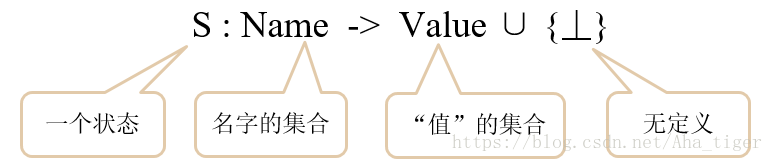
描述机器状态最简单的形式化模型:从合法名字集合到“值”的映射
例如:当x取值3,y取值5,z取值0时的状态为 {x->3, y->5, z->0}
形式化定义:
一个详细例子
示例语言的BNF:
< stmt> -> SKIP
| < var> = val
| < stmt>;< stmt>
| IF < cond> THEN < stmt> ELSE < stmt>
| WHILE < cond> DO < stmt> END
SKIP
SKIP的语义规则:SKIP语句不做任何操作
即: SKIP,S=>S (表示状态无改变)
< var> = val
赋值语句语义规则:语句var=val将变量var的值改为val,其他变量不变
即:var = val, S => S[var->val]。
例: x=2, {x->3, y->5, z->0} => {x->2, y->5, z->0}
< stmt>;< stmt>
复合语句语义规则:先执行语句1,再执行语句2
即:stmt1, S => S1 stmt2, S1 => S2 ——-> stmt1;stmt2, S => S2
例:x=2;y=2, {x->3, y->5, z->0} => {x->2, y->2, z->0} (一步到位)
IF < cond> THEN < stmt> ELSE < stmt>
IF语句语义规则:如果条件为真,则执行语句1,否则执行语句2
- cond=true stmt1, S => S1 则:IF cond THEN stmt1 ELSE stmt2; S => S1
- cond=false stmt2, S => S2 则:IF cond THEN stmt1 ELSE stmt2;S => S2
WHILE < cond> DO < stmt> END
WHILE语句语义规则:如果条件cond为真,则执行语句stmt,直到cond为假
cond=true stmt; S => S1
WHILE cond DO stmt END; S1 => S2
即上两句的作用为:WHILE cond DO stmt END;S => S2
cond=false
即无作用:WHILE cond DO stmt END; S => S
练习题2道
1.考虑下列程序
count =n;
sum=0;
WHILE count > 0 DO
sum=sum + count;
count=count - 1;
END
在状态{n->3}和{n->-1}下的操作语义
答案:
记整个程序为P。
count = n, {n->3} => {n->3, count->3}
sum=0, {n->3, count->3} => {n->3, count->3, sum->0}
{n=3, count->3, sum->0}下,count>0成立,且 sum=sum+count; count=count-1, {n->3, count->3, sum->0} => {n->3, count->2, sum->3}
{n=3, count->2, sum->3}下,count>0成立,且 sum=sum+count; count=count-1, {n->3, count->2, sum->3} => {n->3, count->1, sum->5}
{n=3, count->1, sum->5}下,count>0成立,且 sum=sum+count; count=count-1, {n->3, count->1, sum->5} => {n->3, count->0, sum->6}
{n=3, count->0, sum->6}下,count>0不成立,那么WHILE … END, {n->3, count->0, sum->6} => {n->3, count->0, sum->6}
因此,WHILE … END, {n->3, count->3, sum->0} => {n->3, count->0, sum->6}
故有P, {n->3} => {n->3, count->0, sum->6}
2.请使用此语言设计FOR语句并定义其操作语义
思路是将For循环转换成While循环。
FOR(stmt1; cond; stmt2)
stmt;
等价于:
stmt1;
WHILE (cond) DO stmt;
stmt2 END
所以:
如果stmt1; S => S1。
且WHILE (cond) DO stmt; stmt2 END; S1 => S2。
那么FOR (stmt1; cond; stmt2) stmt, S => S2
2.4.2 指称语义
基础&&思想&&步骤
基础:递归函数理论
思想:定义一个语义函数(指称函数),把程序的意义映射到某种意义清晰的数学对象 (就像用中文解释英文)
步骤:
- 为每个语言实体定义一个数学对象(语义域)
- 定义一个将语言实体的实例映射到该数学对象的实例的函数
简单例子——二进制数的语义:
BNF:< binary> -> ‘0’ | ‘1’ | < binary> ‘0’ | < binary> ‘1’
语义域:自然数集合
语义函数 Mbin M b i n :
- Mbin M b i n (‘0’) = 0
- Mbin M b i n (‘1’) = 1
- Mbin M b i n (< binary>‘0’) = 2 * Mbin M b i n (< binary>)
- Mbin M b i n (< binary>‘1’) = 2 * Mbin M b i n (< binary>) + 1
一个详细例子
示例语言的BNF:
< stmt> -> SKIP
| < var> = val
| < stmt>;< stmt>
| IF < cond> THEN < stmt> ELSE < stmt>
| WHILE < cond> DO < stmt> END
其操作语义为:< stmt>,S=>S
其中,< stmt>是输入,S=>S是输出,=>是状态到状态的函数
所以对于指称语义来说,==语义域==是状态到状态的函数空间
==语义函数==:M
SKIP
SKIP语句: M(SKIP)(S) = S
一个(恒等)状态函数,对任意输入状态返回状态本身
< var> = val
赋值语句: M(var = val)(S) = S[var -> val]
该语义函数对任意输入状态S都返回S[var -> val]
例:M(x=2)({x->3, y->5, z->0})= {x->2, y->5, z->0}
< stmt>;< stmt>
复合语句: M(stmt1;stmt2)(S) = (M(stmt2)ºM(stmt1))(S)
= M(stmt2)(M(stmt1)(S))
stmt1的语义函数和stmt2的语义函数的复合
例:M(x=2;y=2)({x->3, y->5, z->0})
= (M(y=2) º M(x=2)) ({x->3, y->5, z->0})
= M(y=2) ( M(x=2) ({x->3, y->5, z->0}) )
= M(y=2) ({x->2, y->5, z->0})
= {x->2, y->2, z->0}
IF < cond> THEN < stmt> ELSE < stmt>
条件语句:
M(IF cond THEN stmt1 ELSE stmt2)(S) =
-
- M(stmt1)(S) 如果在S状态下cond为真
- M(stmt2)(S) 如果在S状态下cond为假
对任意输入状态S,如果cond在S状态下为真,返回stmt1的语义函数作用于S的结果M(stmt1)(S) ,否则返回M(stmt2)(S)
例:P: IF x > 0 THEN x = x+1 ELSE x = x-1
M(P)({x->1}) = M(x=x+1)({x->1}) = {x->2}
M(P)({x->-1}) = M(x=x-1)({x->-1}) = {x->-2}
-
WHILE < cond> DO < stmt> END
条件语句:
M(WHILE cond DO stmt END)(S) =
-
- M(stmt; WHILE cond DO stmt END)(S) 如果在S状态下cond为真
- S 如果在S状态下cond为假
对任意输入状态S,如果cond在S状态下为真,返回stmt的语义函数与WHILE语句的语义函数(递归)的复合作用, 否则返回S (终止)
-
与操作语义的相同与差异
相同点:操作语义用==机器的状态==来描述意义,指称语义用==程序的状态==来描述意义,在抽象层面上,这两者是一致的
关键区别:操作语义用某种编程语言编码的算法来定义状态变化,而指称语义用数学函数来定义最终效果,并不关心执行过程。
2.4.3 公理语义
基础&&思想
- 基础:数理逻辑(一阶谓词逻辑)
- 初衷:验证程序的正确性
- 思想:用==逻辑公式==描述(机器或)程序的状态 ,并为程序语句建立一套==公理和推导规则==
- 这种描述状态的逻辑公式称为断言,如:C语言的assert
形式定义
公理语义是以语言对断言的影响来定义的,一般形式:{P} stmt {Q}
- 前置条件P:描述语句在执行前的程序变量的约束条件
- 后置条件Q:描述语句在执行后这些变量的新约束条件
*例:{x>10} sum=2*x+1 {sum>0}
最弱前置条件
最弱前置条件:保证相关后置条件有效的==限制最小==的前置条件
例子:{x>0} sum=2*x+1 {sum>0}
{x>10} sum=2*x+1 {sum>0}
{x>20} sum=2*x+1 {sum>0}
{x>50} sum=2*x+1 {sum>0}
其中x>0是最弱前置条件:实际上sum>0[sum=2x+1]=>x>-0.5,这个才是最弱前置条件。
一个详细例子(还是熟悉的那个)
示例语言的BNF:
< stmt> -> SKIP
| < var> = val
| < stmt>;< stmt>
| IF < cond> THEN < stmt> ELSE < stmt>
| WHILE < cond> DO < stmt> END
以最弱前置条件的计算为例
SKIP
SKIP语句:{P} SKIP {P}
< var> = val
赋值语句:{Q[var->val]} var = val {Q}
根据后置条件来计算(最弱)前置条件(逆推 )
其中Q[var->val]表示将Q中所有出现的var替换成val
例子:{ ? } x=2*y-3 {x > 25}
? 可以是:(x > 25)[x -> 2*y-3] => 2*y-3 > 25 => y > 14
< stmt>;< stmt>
复合语句:{P1} stmt1 {P2} , {P2} stmt2 {P3} 等价于 {P1} stmt1;stmt2 {P3}
例子:{?} y=3*x+1;x=y+3;{x<10}
1)先计算第二条语句的前置条件:
由{?} x=y+3 {x<10}可得 y<7
2)再计算的一条语句的前置条件:
由{?} y=3*x+1 {y<7}可得 x<2
因此,有{x<2} y=3*x+1;x=y+3;{x<10}
IF < cond> THEN < stmt> ELSE < stmt>
条件语句:
- {cond and P} stmt1 {Q}
- {(not cond) and P} stmt2 {Q}
{P} IF cond THEN stmt1 ELSE stmt2 {Q}
例:{?} IF x>0 THEN y=y-1 ELSE y=y+1 {y>0}
1)假设执行THEN语句,其最弱前置条件为:
由{?} y=y-1 {y>0}可得 y>1
2)假设执行ELSE语句,其最弱前置条件:
由{?} y=y+1 {y>0}可得 y>-1
合并得到y>1,即有{y>1} IF x>0 THEN y=y-1 ELSE y=y+1 {y>0}
WHILE < cond> DO < stmt> END
循环语句:{cond and I} stmt {I}
{I} WHILE cond DO stmt END {I and (not cond)}
其中的 I 是循环不变式,难点在于==如何设计循环不变式==。
所以一般题目会给出循环不定式。。。自己验证一下就好
例子:{?} WHILE y<>x DO y=y+1 END {y=x}
设循环不变式I为y<=x
{y<>x and y<=x} y=y+1 {y<=x} ?
y<=x[y=y+1] =>y+1<=x ∴ y
2.5 本章小结
1.语法:BNF和EBNF
2.静态语义:属性文法及其计算
3.动态语义:操作语义、指称语义和公理语义
操作语义
为语言使用者和实现者提供一种有效的语义描述方法
非形式化的使用;一旦形式化,可能变得非常复杂
指称语义
以高度严谨的方式看待程序
可辅助语言设计
描述较复杂,对使用者用处较少
公理语义
定义公理和推导规则是项困难的任务
研究程序正确性的有力工具,程序推理的优秀框架
三、名字、绑定和作用域
3.1 名字
- 名字不只用于变量,还有形式参数、子程序(函数)、标号等
- 名字的主要设计问题
-
- 最大长度
- 是否区分大小写
- 特殊字:保留字、关键字
3.2 变量
变量是语言中机器存储单元的抽象

名字:有极少数变量没有
地址:与变量关联的内存地址
- 在程序执行过程中,变量在不同时间可能有不同的地址
- 在程序中,变量在不同的位置可能有不同的地址
别名:两个变量能够访问相同的内存地址
- 影响可读性,危险特性
- 指针,引用
类型:决定了变量的取值范围和操作集合
数值:相关联的存储单元的内容
- 右值:变量的值
- 左值:变量的地址
3.3 绑定
定义:绑定是属性与实体之间的关联,例如变量与其类型或者值之间的关联
3.3.0 绑定时间:绑定发生的时间称为绑定时间
- 编译时:如,变量被绑定到某种特定数据类型
- 连接时:如,子程序的调用
- 装载时:如,静态对象(static)的内存定位
- 运行时:如,(非静态)局部变量与存储单元的绑定
3.3.1 绑定的类型以及类型绑定(数据类型)
静态绑定:绑定在运行之前第一次出现,且在整个程序的执行过程中保持不变
类型可能通过显式声明或隐式声明来说明 (声明是说明变量的数据类型,不为其分配空间)
- 显示声明:程序中列出变量及其类型的说明语句
- 隐式声明:程序默认将变量的第一次出现当作声明
动态绑定:绑定在运行期间第一次出现,或者能在程序执行期间改变
-
- 通过赋值语句来声明,而不是声明语句
- 在执行过程中,可以改变任意次
优点:灵活性大,如,能写处理任何类型的数据的通用程序
缺点:
- 可靠性差:很难检测到类型错误
- 成本高:当前类型的维护
C语言的static变量是静态绑定的,非static的局部变量时动态绑定的
变量在使用前,必须绑定一个类型。
3.3.2存储绑定和生存期
分配:从可用的存储池中取得一个存储单元
解除分配:将存储单元放回存储池
生存期:变量被绑定到某个存储单元的时间段,变量的分配与回收的全过程。
生命周期(不确定):变量存在的时间,有些语言中变量的生命周期从声明开始,但生存期不是。==变量的属性是生存期而不是生命周期==
根据生存期,变量可分为
- 静态变量
- 栈动态变量
- 显式堆动态变量
- 隐式堆动态变量
数据区(编译时分配)、栈区(由系统自动分配)、堆区(需程序员申请与释放(或垃圾回收机制))
3.3.3 静态变量
静态变量:在程序运行前就绑定到存储单元,且在程序结束运行前一直绑定在相同的存储单元上
例,C中全局变量、用static修饰的局部变量
例,Java中类变量、用static修饰的局部变量
例,Python中的类变量
优点:
- 高效率:直接寻址
- 运行开销低:无分配与解除分配
缺点:
- 灵活性低,如不支持递归子程序
- 空间开销大,静态变量间不能够共享空间
3.3.4 栈动态变量
栈动态变量:在声明语句执行确立后才产生存储绑定
- 从运行时栈中分配的
- 类型是静态绑定的
例,C函数中局部变量
例,Java函数中基本类型的变量、对象的引用变量
优点:
- 允许递归
- 可共享存储空间
缺点:
- 分配和解除分配需开销
- 间接寻找,效率较低
3.3.5 显式堆动态变量
显式堆动态变量:通过显式指令来分配和解除分配
- 由程序员编写的,在执行时才起作用
- 在堆中分配,通过指针变量或引用变量进行访问
例,C中malloc和free函数
例,Java的对象都是显式堆动态变量,Java的new和垃圾回收机制
优点:
- 提供动态存储管理机制,容易构建动态数据结构
缺点:
- 可靠性差:如指针很难被正确使用
- 效率较低:如引用变量有额外开销
3.3.6 隐式堆动态变量
隐式堆动态变量:赋值时才绑定到堆存储空间
- 类型是动态绑定的
例,python和JavaScript的赋值语句:Highs = [74, 84, 86, 90, 71]
优点:高度灵活性
缺点:
- 需维护动态属性的开销
- 可靠性差,编译器较难发现错误
3.3.7 绑定——C语言例子
int a = 0; //全局初始化区
char *p1; //全局未初始化区
void main() {
int b; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,p3在栈上
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10); //堆区显式分配10个字节
p2 = (char *)malloc(20); //堆区显式分配20字节
strcpy(p1, "123456"); //123456\0放在常量区,
//编译器可能会将它与p3所指向的"123456"优化成一个地方
}3.4 作用域
- 作用域:变量在哪些语句范围内是可见的
- 作用域规则决定了一个名字的特定出现与一个变量的关联性
int x = 1;
int z = 4;//两个全局变量,在所有作用域都可以访问的变量
//println(x);//println(y); //println(z);
void main() {
int x = 2;
int y = 3;//两个局部变量,在此特定函数块内可访问的变量
//println(x);//println(y); //println(z);
}3.4.1 静态作用域
静态作用域:编译时(执行之前)就决定了变量的作用域
- 基于程序文本,在变量的使用前需找到它的声明
- 从当前的局部作用域,逐级地往外层作用域搜索

在静态作用域中,一些变量的声明对其他代码段是可以隐藏的。例如上图中外部变量x就对main()函数隐藏。
块:程序中创建静态作用域的方法
- 允许一段代码具有它自己的局部变量,这些局部变量的作用域就是这段代码,常用花括号{}括起来
- 这些变量是典型的栈动态变量
例:函数局部变量
例:for语句:for(…) { int index; …}
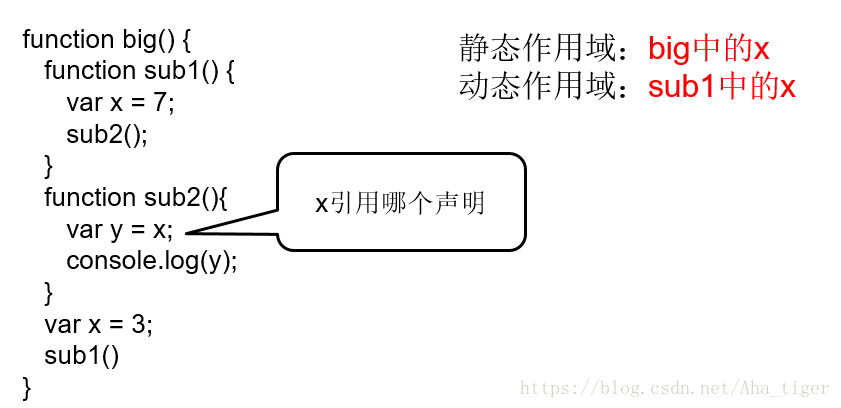
3.4.2 动态作用域
动态作用域:作用域在运行期间确定
- 基于程序单元的调用顺序,而不是程序文本
- 从局部声明开始,逐级地往动态父辈(或调用函数)声明搜索
一个例子区分静态作用域和动态作用域:
作用域小结
- 静态作用域:
- 可读性较好,可靠性较好
- 易设计为全局变量,不利于封装
- 动态作用域:
- 可读性较差,可靠性较差
- 灵活方便,如参数传递
作用域与生存期看似相关联,实际上不是同一件事情:一个是空间、一个是时间
3.5 引用环境——静态
- 语句的引用环境:该语句中所有可见变量的集合
静态作用域语言中,语句的引用环境是在它的局部作用域中声明的变量,和在它的祖先作用域中声明的所有可见变量的集合
一个例子:

3.6 引用环境——动态
活跃的子程序:当前已经开始执行但还没终止
- 动态作用域语言中,语句的引用环境是在它的局部作用域中声明的变量,和当前活跃的其他子程序的所有可见变量的集合
一个例子:

3.7 命名常量
命名常量:和值仅绑定一次的变量
增加可读性和可靠性
例:用PI表示圆周率3.14159256
例:用len表示数据长度,修改长度只需改len
既可以静态绑定也可以是动态绑定
例如:C#的const(静态)和readonly(动态)
四、数据类型
4.1 概述
数据类型定义了一组数据值,以及在这些数据值上的一组操作。
类型系统的主要用途 (考点,选择题):
- 提供错误检查
- 为程序模块化提供帮助
- 提供文档化
描述符是变量的属性的集合:
- 静态:编译期间需要维护,符号表
- 动态:执行期间需要维护
数据类型的基本设计问题:应该为各种类型的变量提供哪些操作,以及如何说明这些操作
C语言例子:

4.2 基本数据类型
大部分编程语言都提供了基本数据类型:
- 整数:int, short, long
- 浮点数:float, double
- 布尔类型:bool
- 字符类型:char
4.3 字符串类型
描述的值:由字符组成的序列
设计问题:
- 基本类型还是字符数组?
- 静态长度还是动态长度?
长度选择:
- 静态长度:Python,Ruby,C#,C++(immutable)
- 有限动态长度:C,C++(C风格)
- 动态长度:JavaScript,Perl,C++(std)
字符串操作:赋值、比较、串联、子串、长度、模式匹配。。。
字符串实现:
- 静态长度:编译时描述符
- 有限动态长度:可能需运行时描述符
- 动态长度:需运行时描述符,如何分配和释放是最大的实现问题
4.4 数组类型
数组类型: (同质)数据的一种聚合形式
- 各个数据元素都是同一类型
- 通过下标来指定数组元素
索引: 下标到数组元素的(有限)映射
- 数组名称(下标值链表)-> 值
数组引用:< array_name> (< index_list>) 或 < array_name> [< index_list>]
设计问题:
- 下标的类型可以是什么
- 下标的范围检查
- 何时绑定下标范围
- 何时分配空间
- 对不规则数组或多维数组的支持
- 初始化
- 对切片对支持
根据下标范围的绑定、存储空间的绑定和空间的分配地方,数组可分为五类:
- 静态数组
- 下标范围和存储空间都是静态绑定的
- 优点:执行效率高(无分配和回收)
- 缺点:不灵活(固定)
- 例:C语言全局数组、static限定的局部数组
- 固定栈动态数组
- 下标范围是静态限定的,存储空间是在栈上动态分配的(执行到声明语句时)
- 优点:空间效率(可共享)
- 缺点:需分配和回收
- 例:C语言的没有static限定的局部数组
- 栈动态数组
- 下标范围和存储空间都是动态绑定的,生存期内不变
- 例:Ada语言的数组
- 固定堆动态数组
- 下标范围和存储空间是在分配存储空间(堆)后就固定、
- 例:C语言的动态数组(malloc),Java的非泛型数组
- 堆动态数组
- 下标范围和存储空间都是动态绑定的,生存期内可变
- 例:Java和C#的泛型数组
4.5 记录类型(结构体)
记录类型:可能异构的数据的一种聚合形式
- 各个数据元素的类型可以不一样
- 通过名称(记录域)来访问数据元素
设计问题:
- 记录的语法形式
- 记录域引用的语法形式
- 引用能否省略
补充内容:
数组类型
-
- 数据值类型相同,处理方式相同
- 下标寻值(动态,较慢)
记录类型
-
- C:数据值类型不同,处理方式不同
- 域名寻值(静态,较快)
- 动态下标也能访问记录,但不允许类型检测且速度慢
4.6 指针和引用类型
指针类型:
- 取值范围包括内存地址的值和一个特殊值nil或null
- 用途:间接寻址和动态存储管理(增加可写性)
设计问题:
- 指针变量的作用域和生存期是什么
- 堆动态变量(指针引用的值)的生存期是什么
- 是否限制指针所指向的值的类型
- 指针的用途是间接寻址、动态存储管理还是两者
- 语言是否应该支持指针类型或引用类型
指针相关问题:
- 悬空指针——指向内存空间已释放的堆动态变量的指针
//C++
int * p1 = new int[100];
//创建一个堆动态变量,令p1指向它
int * p2 = p1;
//p1赋给p
delete [] p1;
//释放p1,并没有改变p2
//p1和p2都是悬空指针堆动态变量的丢失
- 程序无法访问已分配空间的堆动态变量
- 常称为垃圾变量,造成内存泄漏
//C++
int * p1 = new int[100];
//创建一个堆动态变量,令p1指向它
p1 = new int[100];
//创建一个堆动态变量,令p1指向它
//这使得第一次创建的变量无法访问C和C++的指针
用于动态存储管理和寻址
可指向任何地址的任意变量(危险)
显式的解引用(*)和取地址操作(&)
允许某些限制形式的地址计算
void * :指向任意类型,但不能解引用(无类型检测问题)
float score[100];
float * p = score;
*(p+5) –– score[5] –– p[5]引用类型:操作有限的指针类型
- 指针指向内存中的地址
- 引用指向内存中的对象和值
C++的引用类型
- 常量指针(不可变)且被隐式解引用
- 主要用于函数定义的形式参数(按引用传参)
补充内容:c++中的引用与指针的区别
★ 相同点:
1. 都是地址的概念;
指针指向一块内存,它的内容是所指内存的地址;引用是某块内存的别名。
★ 区别:
1. 指针是一个实体,而引用仅是个别名;
2. 引用使用时无需解引用(*),指针需要解引用;
3. 引用只能在定义时被初始化一次,之后不可变;指针可变;
引用“从一而终” ^_^
4. 引用没有 const,指针有 const,const 的指针不可变;
5. 引用不能为空,指针可以为空;
6. “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身(所指向的变量或对象的地址)的大小;
typeid(T) == typeid(T&) 恒为真,sizeof(T) == sizeof(T&) 恒为真,但是当引用作为成员时,其占用空间与指针相同(没找到标准的规定)。
7. 指针和引用的自增(++)运算意义不一样;
★ 联系
1. 引用在语言内部用指针实现(如何实现?)。
2. 对一般应用而言,把引用理解为指针,不会犯严重语义错误。引用是操作受限了的指针(仅容许取内容操作)。
不同语言中的指针和引用:
- JAVA
- 无指针运算
- 只能指向(堆中的)对象
- 没有显式回收(系统提供垃圾回收机制),无悬空引用
- 解引用经常是隐式的
- Python
- 所有变量都是引用
- 总是隐式释放
4.7 抽象数据类型
抽象数据类型:一个封装
- 一种数据类型的数据表示(数学模型)
- 为这种数据类型提供操作的子程序
//一个例子
#ifndef _stack_h
#define _stack_h
typedef struct stackCDT *stackADT;
typedef int stackElement;
stackADT NewStack(void);
void FreeStack(stackADT stack);
void Push(stackADT stack ,stackElement element );
stackElement Pop(stackADT stack);
int StackTop(stackADT stack);
#endif4.8 类型检测
- 第一、二章的例子:int i = 1.6?
- 类型检测:保证运算符的操作数具有兼容的类型的过程
- 兼容的类型:类型对运算符是合法的或者允许通过语言允许的规则隐式转换为合法的(整数可转换为浮点数)
- 类型错误:运算符被作用于类型不合适的操作数
- 静态类型检测:Java
- 动态类型检测:Python,JavaScript
五、表达式与赋值语句
5.1 概述
- 表达式是编程语言中描述计算的基本工具
- 表达式的语法(BNF)
- 表达式一般分为:算数表达式、逻辑表达式、关系表达式
- 本章重点讨论表达式的语义
5.2 算数表达式
算术表达式的计算是最初设计编程语言的动机之一
算术表达式由运算符、操作数、括号和函数调用组成
算术表达式的基本设计问题
1.运算符的优先级规则
2.运算符的结合性规则
3.操作数的运算顺序
4.对操作数求值的副作用是否存在约束
5.是否允许运算符重载
6.是否允许类型混合
5.2.1算数表达式的分类
按操作数个数,运算符可分为:
- 一元运算符:+,-,++,–
- 二元运算符:+,-,*,/,%
- 三元运算符:条件表达式 ? :
5.2.2 优先级规则
优先级规则:定义了优先级不同的相邻运算符的运算顺序 :
- 例:a + (-b) * c 合法, a + - b * c 通常不合法
- 例:- a / b , - a * b, - a ** b 各有几种可能结果?
结合性规则:定义了优先级相同的相邻运算符的运算顺序(左结合和右结合)
括号(具有更高优先级) :可改变优先级规则和结合性规则,从而调整计算顺序。
操作数的运算顺序:
- 变量:直接取在内存中的值
- 常量:有时直接取值,有时是机器指令一部分(立即数)
- 括号表达式:先计算表达式,再返回值作为操作数
- 函数引用:操作数的运算顺序至关重要(副作用)
小练习:
(a – b) / c & (d * e / a – 3)的运算顺序: (((a−b)1/c)2and(((d∗e)3/a)4)−3)5)6 ( ( ( a − b ) 1 / c ) 2 a n d ( ( ( d ∗ e ) 3 / a ) 4 ) − 3 ) 5 ) 6
(从左到右,自底向上)
5.2.3 副作用
副作用:当函数改变其(双向)参数或者非局部变量时,则称该函数是有副作用的
//例子1
int a = 5;
int fun1() {
a = 17;
return 3;
} /* end of fun1 */
void main() {
a = a + fun1();
//a的值是多少呢?
} /* end of main */ 双向参数:指针参数,引用参数
注意,数学里的函数是没有副作用的,因为数学中没有变量的概念。函数式编程语言也没有这个问题
引用透明: 如果任意两个值相同的表达式能够在该程序的任何地方互换,并且不影响程序的运行,这个程序就是引用透明的。
解决副作用的方法:
- 语言设计时就禁止函数带有副作用
- 函数不允许双向参数
- 函数不允许出现非局部变量
- 优点:方法可行
- 缺点:降低灵活性,程序员想用怎么办,如C语言的swap
- 定义语言时就规定好操作数的运算顺序
- Java规定:从左到右
- 缺点:限制了编译器的优化
5.2.4 操作符重载
操作符重载:运算符的多种用法
常见的操作符重载:整数+、浮点数+
有些重载存在潜在危险:例如C语言的&
- 按位逻辑与,二元
- 取地址运算,一元
- 降低可读性:没有相关的运算采用相同符号
- 可靠性差:错误难发现
用户自定义的操作符重载:C++允许
- 只要合理,可提高可读性,例如矩阵+,矩阵*
- 影响可读性和可靠性,例如用户可能定义一些无意义的符号,如用+表示矩阵乘
5.2.5 类型转换
收缩转换:新类型不能存下原类型的所有值
例如,double转为float,double的取值范围比float大
通常是不安全的
扩展转换:新类型能够存下原类型的所有值
例如, float转为double
通常是安全的,但可能降低精度
两种形式:
隐式类型转换
由编译器执行的强制转换:
混合模式表达式:有不同类型操作数的表达式
支持混合模式表达式的语言必须定义用于操作数类型隐式转换的协议,如整数可转换为浮点数
显式类型转换
由程序员显式执行的强制转换:
绝大多数语言提供一些功能来执行显示转换,包括收缩转换和扩展转换
如果显示的收缩转换使原来的值发生巨大变化,程序会发布警告
5.3 关系表达式和布尔表达式
5.3.1 关系表达式
关系表达式:使用关系运算符和各种类型的操作数的表达式,计算结果是布尔型
- 关系运算符经常用作重载(各种类型)
- 操作数常常是:数值型、字符串和序数
5.3.2 布尔表达式
布尔表达式:由布尔型变量、布尔型常量、关系表达式和布尔运算符
布尔运算符:与(AND)、或(OR) 、 非(NOT ), 可能有异或(XOR)和等价
由于算数表达式可能是关系表达式的操作数,关系表达式可能是布尔表达式的操作数,所以要求三种运算符的优先级不同
5.4 短路求值(17年选择题)
短路求值:表达式的结果不是在计算了所有的操作数之后得到的
例如 : if false && 1==1 并不会计算1==1,因为已经知道结果为false。
- 可用于避免除零操作
if(n!=0 && sum/n>50)
exam=pass;- 可用于避免空指针
while(p!=NULL && p->val!=key)
p=p->next;5.5 赋值语句
赋值:与数据有关的最基本操作
- 赋值语句是命令式语言的核心概念之一
- 赋值语句的目的是改变变量的值或程序的状态
形式:
- 简单赋值: 赋值运算符 = 、 :=(避免与相等混淆)
- 混合赋值:C、C++和Java:+=、-= 、*=、/=
- 条件赋值:
- Perl: ($flag ? $count1 : $count2) = 0;
- if (flag) { flag) { count1 = 0;} else {$count2 = 0;}
- 一元赋值:++、–(C、JAVA)
- 多重赋值:Perl、Ruby中多目标、多来源的赋值语句。例:( first, f i r s t , second) = (20,40);
赋值表达式:赋值语句产生的返回值作为表达式赋值
例(C语言):while((ch=getchar())!= EOF) {…}
混合模式赋值:类似混合表达式,赋值表达式可能含有不同类型
- C和C++:采用混合类型表达式的隐式类型转换规则,任何数字的值可以分配给任何数值的标量或变量
- Java和C#:只有扩展强制转换才能完成混合类型赋值
- Ada:没有强制转换,不允许混合类型转换
- Python:不允许,只允许显式类型转换
函数语言的赋值:
所有标识符只是数值的名字,值从不改变
...
val cost =...
...
val cost = quantity * price
第二个cost声明创建一个新的cost变量,将第一个cost隐藏了
六、语句级控制结构(填空题考过)
6.1 概述
设计者想让程序更加灵活、强大:
- 多个语句或者语句组进行选择的结构
- 重复执行某条语句或者语句组的结构
程序员关注的是程序的可写性和可读性
- 控制语句的数量和种类越多,可写性越好
- 控制语句形式越多,可读性越难
- 控制语句越少,可能需goto低级语句,降低可读性
控制结构:包括控制语句和被它控制执行的语句集合两部分
6.2 选择语句——双路
选择语句:
- 提供从两个或者多个路径选择一个的方法
- 经证明,所有程序语言的必要部分
- 双路选择语句和多路选择语句
双路选择语句
- 形式: if 控制表达式 then 子句 else 子句
设计问题:
- 控制选择方向的表达式的形式和类型是怎样的?
- then和else子句如何确定?
- 嵌套选择器的含义如何确定?
控制表达式:
- 常用圆括号界定,如C,Java
- 用then或其他语法符号引导分支,如Python,Ruby
- 常用布尔表达式,如Java
- 有的允许算数表达式,如C,Python
子句的形式:单个语句、程序块
嵌套选择器:
if( sum == 0)
if( count == 0)
result =0;
else
result = 1;方法1:通过静态语义规则规定,即就近原则。如 C和Java:跟第二个if匹配
方法2:通过缩进确定。如Python: 跟第一个if匹配
方法3:利用复合语句实现不同的语义

方法4:使用特殊的保留字实现不同的语义。如Ruby
6.3 选择语句——多重
多重选择结构
- 允许在任意数量的语句或语句组中选择。
- 通用选择器
设计问题:
- 控制选择的表达式的形式和类型是怎样的?(同双重)
- 可选择语句段是怎样的?(同双重)
- 通过结构的执行流是否限定为只包含一个可选段?
- case值是怎样指定的?
- 如果选择器表达式的值根本无法表述,应该如何处理?
多重选择结构switch语法形式:
switch (控制表达式){
case 常量表达式1: 语句1;
……
case 常量表达式n: 语句n;
[ default : 语句n+1;]
}switch利用break语句构成显示分支(限制控制流)
switch (index){
case 1:
case 3: odd +=1;
sumodd += index;
break;
case 2:
case 4: even += 1;
sumeven += index;
break;
default : printf(“Error in switch, index = %d\n”,index);
}6.4 迭代语句
迭代语句:能使一条语句或一块语句执行0次、1次或者多次,一般称为循环。
- 迭代是计算机能力的精华
- 最初的迭代语句与数组相关
设计问题
- 怎样控制语句的迭代?
- 控制机制在循环语句中的什么位置体现?
控制方法:
- 用逻辑条件、计数或者二者结合
- 基于数据结构
控制机制:
- 在循环体之前(前判断)
- 在循环体之后(后判断)
- 允许用户选择放置位置
6.4.1 计数控制循环
计数控制语句
- 循环变量:记录目前的计数;
- 循环参数:循环变量的起始、终止方式,以及步长。
代表:for循环
6.4.2 逻辑控制循环
- 基于布尔表达式,而不是计数器。代表:while循环
- 逻辑控制循环比计数控制循环更具有普适性。
-
- 任何一个计数循环都可以用逻辑控制循环来构
-
- 反之不一定成立
6.4.3 基于用户自定义的循环控制机制
break、continue。
用户自定义的循环退出机制:满足从严格受限制的分支语句跳转到其他语句的需要
与goto语句的差别:
- 跳转目标语句只能在循环结束之后,且紧跟在循环体复合语句的结尾,不影响可读性
- goto语句的跳转目标可以是程序中的任意位置,可能破坏可读性
6.4.4 基于数据结构的循环
例如:
- java中的 for(String name:names)
- python中的 for item in list:
七、子程序
7.1 概述
编程语言的两个抽象过程
过程抽象:抽象的对象是实现某种==功能可能复杂的操作==
数据抽象:抽象的对象是被操作的==数据概念和相关功能==
子程序是最主要的计算过程的抽象机制
7.2 子程序的基本原理
一般特性(选择题有考):
- 每个子程序都只有一个入口
- 当执行被调用子程序时,调用程序被暂停
- 被调用子程序终止时,控制权交还给调用子程序
名字(类似变量的名字):大多数子程序都有名字,少数匿名函数
7.2.1基本定义
- 子程序定义:子程序的操作抽象的描述
- 子程序调用:执行子程序的显式要求
- 活动子程序:子程序已开始执行但未终止
- 子程序头部:子程序定义的第一行,包括名字,子程序的类别,和形式参数
- 子程序体:定义了子程序的操作
-
- C、Java用花括号界定
- Python用缩进界定
- Ruby用end结束子程序体
- 子程序参数描述:形式参数的个数、顺序和类型
- 子程序协议:参数类型和返回值类型
- 子程序声明:仅提供协议,不提供子程序体
- ==形式参数(形参)==:子程序头部定义的(虚)变量
- ==实际参数(实参)==:调用时使用的值或地址
- ==闭包==:子程序和及其引用环境
7.2.2 参数
实参与形参的对应
- 位置参数:一一对应,既安全又可靠
- 关键字参数:通过形参名指定,任意顺序,但必须记住名字,且==关键字参数后面也必须是关键字参数==
默认参数:最好是不可变参数
例子:


可变参数:
例子:

7.2.3 子程序的类别
- 过程:没有返回值,可定义新的语句
- 函数:有返回值,可定义新的操作符
//过程,新操作语句
void sort(int n, int[] array)
//函数,新操作符
float power(float base, float exp)7.3 子程序的设计问题(8个)
- 局部变量是动态分配还是静态分配
- 子程序定义可否出现在另一个子程序的定义中
- 选择哪个或哪些参数传递方式
- 实参是否应当根据对应的形参类型进行类型检测
- 子程序作为参数,且允许嵌套,怎么调用传递过来的子程序
- 子程序能否重载
- 子程序能否泛型化(作用于不同类型的数据)
- 如果允许嵌套子程序,那么支持闭包吗
7.3.1 局部变量
局部变量:子程序内部定义的变量,其作用域是子程序体内
- 栈动态变量
- 优点:支持递归,可共享
- 不足:分配/解除分配需开销,非间接寻址、历史不敏感
- 静态变量:与栈动态变量相反
大多数当代语言默认是栈动态变量
- C语言如无static,则是栈动态的
- Java只有栈动态局部变量
- Python所有局部变量都是栈动态的
7.3.2 嵌套子程序
嵌套子程序:某个子程序只在另外一个子程序用到,则将其定义放在使用的子程序中(高度结构化)
例子:
- C语言、Java不支持
- Python、JavaScript、Ruby等新兴语言支持
- 大多数函数语言支持
7.3.3 传参
参数传递:参数传入传出被调用的子程序的方法
形参的三种语义模型
- 输入型:接收来自实参的数据
- 输出型:传递数据给实参
- 输入输出型:两者皆可
数据传输的概念模型:
- 复制实际的值
- 通过访问途径传输(指针或引用)
实现模型-==按值传递==(输入模型)
- 实参的值用来初始化形参,且被用作局部变量
- 一般通过复制实现,也可通过访问路径传递
- 复制传递的不足:
- 需要更多空间
- 迁移数据需开销
- 访问路径的不足:
- 被调用程序需要写保护
- 间接寻址开销大
//C按值传递实例
void swap1(int a, int b) {
int temp = a;
a = b;
b = temp;
}
swap1(c, d);
//结果不变,过程如下
//a = c
//b = d
//temp = a
//a= b
//b = temp
实现模型-==按结果传递==(输出模型)
- 局部数值传回给调用者,实参必须是变量
- 通常采用值拷贝, 需要额外时间和空间
- 可能存在实参冲突
- 获取实参的地址的时间不同,结果也不同
实现模型-==按值-结果传递==(输入输出模型)
- 按值传递和按结果传递的组合
- 子程序调用之初,实参复制给形参,调用结束后,形参又复制回实参,又称按复制传递
- 需要额外复制时间和存储空间
- 具有同按值传递和按结果传递的不足
- 问题:获取实参地址的时间是?
例子:

实现模型-==按引用传递==(输入输出模型)
通过访问路径获取数据的地址,并传递给被调用的子程序
实际上,实参是由调用子程序和被调用子程序共享
优点:传递快,空间效率高
不足:访问慢,别名问题
别名问题原因:调用子程序提供了对非局部数据更大的访问
按值-结果传递则没有别名问题(但存在其他问题)
按指针传递:若把地址当作值,按指针传递就是按值传递,只不过传的值是地址而已
按引用传递:需先提取参数的地址,再传给被调用子程序
别名问题的例子1:

别名问题的例子2:

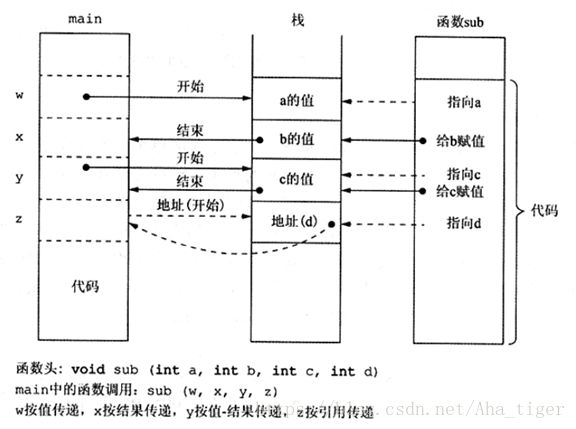
上图展示了四种不同的参数传递方式对应运行时的栈变化。
实现模型-按名字传递(多种模型)
- 传递的是名字,不是值或者地址
- 通过文本替换
- 在调用时形参绑定到一个访问方法,而值或地址的绑定则推迟到引用形参的时候
- 优点:按需计算
- 不足:引用很低效,程序可能复杂,可读性和可靠性差
- 如果是标量变量,等价于按引用传递
- 如果是常量表达式,等价于按值传递
例子
procedure P(X,Y,Z) {
Y:=Y+X;
Z:=Z+X;
}
所以
P(A+B,A,B)等价于
A:=A+A+B;
B:=B+A+B;参数传递方法的选择
- 效率
- 单向还是双向传输
这两个原则是冲突的
良好的编程艺术:限制变量的访问,意味着尽可能单向传输
高效:按引用传递是最快的方法,意味着双向
7.3.4 参数的类型检测
- 对软件可靠性非常重要
- C语言:用户可选择是否对参数进行类型检测
- Java:检测
- Python:无
7.3.5 子程序作为参数
- 程序的处理能力更强,如事件处理、回调函数
- 两实现难题
- 类型检查:
-
- 怎么检测子程序类型
- C和C++传递函数指针,其中包括函数的类型
- Java不允许子程序作为参数
- Python无类型检测
- 引用环境:执行被传递的子程序时选择哪个引用环境?
-
- ==执行被传递子程序的语句的环境(浅层绑定):动态作用域==
- ==定义被传递子程序的语句的环境(深层绑定):静态作用域==
- 传递被传递子程序的语句的环境(特殊绑定):很少用
7.3.6 子程序的重载
- 重载的子程序是在同样的引用环境中与另一个子程序同名的子程序
- 重载的子程序每个版本必须有一个==独特的协定==:
-
- 参数的个数、顺序、类型、返回类型等
- 注意避免歧义
语言例子:
- C语言:语法上不支持重载,但可用函数指针实现
- C++和Java:包含了预定的重载子程序,用户也可定义自己的重载子程序
- Python:支持类方法的重载
7.3.7 泛型(多态)子程序
泛型(或多态)子程序:能作用于不同类型的数据且执行不同的操作的子程序
提高软件重用率
- 特殊的多态:子程序重载
- 子类型多态:面向对象中,不同的子类型可能具有不同的行为
- 参数化多态:通过带泛型参数的类型表达式来描述子程序的参数类型
7.3.8 闭包
- 闭包:子程序及其引用环境
- 不允许嵌套子程序的语言,闭包没什么用
- (嵌套)子程序的引用环境:局部变量、全局变量、外层变量