Linux环境Hive安装配置及使用
Linux环境Hive安装配置及使用
- 一、Hive
- Hive环境前提
- 二、Hive架构原理解析
- 三、Hive-1.2.2单机安装流程
- (1) 解压apache-hive-1.2.2-bin.tar.gz安装包到目标目录下:
- (2) 为后续方便,重命名Hive文件夹:
- (3) 修改配置文件:
- (4) 配置环境变量:
- (5) 启动
- (6) 退出
- (7) 配置MySQL元数据库
- 四、Hive数据类型
- 五、Hive-DDL(Data Definition Language)
- (1) 查看数据库
- (2) 创建库
- (3) 创建库(标准写法)
- (4) 创建库指定hdfs路径
- (5) 创建表
- (6) 查看表类型:
- (7) 查询表
- (8) 分区表操作
- (9) 分桶表操作
- (10) 查看数据库结构
- (11) 添加数据库额外描述信息
- (12) 查询数据库额外信息
- (13) 查看指定的数据库(使用通配符)
- (14) 删除空库
- (15) 删除非空库标准写法
- (16) 删除非空库
- (17) 删除非空库标准写法
- 六、Hive-DML(Data Manipulation Language)
- (1) 导入数据
- (2) 向表中插入数据
- (3) 向表中插入sql查询结果数据
- (4) 创建表直接加载数据
- (5) 把操作结果导出到本地linux
- (6) 把hive中表数据导出到hdfs中(拷贝操作)
- (7) 把hdfs数据导入到hive中(拷贝操作)
- (8) 清空表数据
- 七、Hive命令
- (1) 不登录Hive客户端直接输入命令操作:
- (2) 直接把sql写入到文件中:
- (3) 在Hive中可以直接执行hdfs命令操作:
- (4) 查看历史操作
- 八、UDF自定义函数
- (1) 相关概念:
- (2) 查看系统自带函数:
- (3) 查看系统自带函数示范用法:
- (4) UDF自定义函数使用:
- 九、Hive压缩——大量数据节省时间
- (1) Map输出阶段压缩方式:
- (2) Reduce输出阶段压缩方式:
- 十、Hive进阶
- (1) Hive集群搭建
转载自:YBCarry
一、Hive
Hive环境前提
- 1)启动hdfs集群
- 2)启动yarn集群
- 如果想用hive的话,需要提前安装部署好hadoop集群。
二、Hive架构原理解析
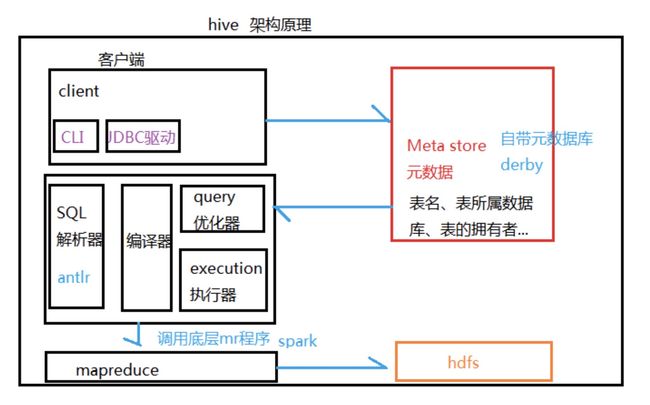
三、Hive-1.2.2单机安装流程
(1) 解压apache-hive-1.2.2-bin.tar.gz安装包到目标目录下:
tar -zxvf .tar.gz -C 目标目录
(2) 为后续方便,重命名Hive文件夹:
mv apache-hive-1.2.2-bin/ hive-1.2.2
(3) 修改配置文件:
进入hive-1.2.2/conf路径,重命名配置文件:
mv hive-env.sh.template hive-env.sh
修改hive-env.sh信息:
vi hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
# 指定Hadoop安装路径
HADOOP_HOME=Hadoop安装路径
# Hive Configuration Directory can be controlled by:
# 指定Hive配置文件夹
export HIVE_CONF_DIR=/XXXXXX/hive-1.2.2/conf
(4) 配置环境变量:
- 修改配置文件:
vi /etc/profile
- 增加以下内容:
export HIVE_HOME=hive安装路径
export PATH=$PATH:$HIVE_HOME/bin
# Hadoop环境加入Hive依赖
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
- 声明环境变量:
source /etc/profile
(5) 启动
hive
(6) 退出
quit;
(7) 配置MySQL元数据库
- <1>. 上传mysql驱动到hive/lib
- <2>. 在hive-1.2.2/conf路径创建配置文件hive-site.xml:
vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://主机名:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
密码
password to use against metastore database
# 查询表时显示表头信息
hive.cli.print.header
true
# 显示当前所在的数据库
hive.cli.print.current.db
true
- <3>. 重启hadoop集群
- <4>. 启动hive:
hive - <5>. 此时mysql中自动创建metastore元数据库
四、Hive数据类型
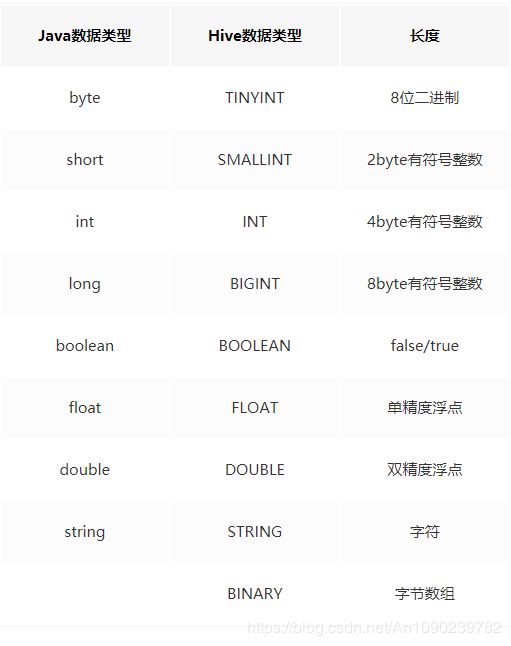
五、Hive-DDL(Data Definition Language)
(1) 查看数据库
show databases;
(2) 创建库
create database 数据库名;
(3) 创建库(标准写法)
create database if not exists 数据库名;
(4) 创建库指定hdfs路径
create database 数据库名 location '路径';
(5) 创建表
create [external] table [if not exists] 表名(参数) [partitioned by(字段信息)] [clustered by(字段信息)] [sorted by(字段信息)]
row format ---根据行格式化
delimited fields ---分割字段
terminated by '切割符'; ---分割依据
- external:可选操作,加上创建的是外部表,去掉创建的是管理表(内部表)
- if not exists:可选操作,加上为标准写法
- partitioned by(字段信息):可选操作,分区
- clustered by(字段信息):可选操作,分桶
- sorted by(字段信息):可选操作,排序
- **注意:**如果指定了hdfs路径,创建的表存放于该路径下
(6) 查看表类型:
desc formatted 表名;
Table Type:
MANAGED_TABLE——内部表
EXTERNAL_TABLE——外部表
**区别:**管理表删除时hdfs中数据删除,外部表删除时hdfs中数据不删除
(7) 查询表
普通表查询:
select * from 表名;
指定列查询:
select 表名.列1, 表名.列2 from 表名;
指定列查询设置别名
select 表名.列 (as) 列别名 from 列原名;
分区表查询:
- 全查询:
select * from 表名;
**注意:**此时查看的是整个分区表中的数据
- 单分区查询:
select * from 表名 where 分区条件;
**注意:**此时查看的是指定分区中的数据
- 联合查询:
select * from 表名1 where 分区条件 union select * from 表名1 where 分区条件;
- 常用基础查询函数:
- 查询总行数:
select count(1) from 表名; - 查询最大值:
select max(列名) from 表名; - 查询最小值:
select min(列名) from 表名; - 查询列总和:
select sum(列名) from 表名; - 查询列平均值:
select avg(列名) from 表名; - 查询结果只显示前n条:
select * from 表名 limit n;
where——过滤:
- 查询A列n~m之间的数据:
select * from 表名 where A>n and A- 查询A列小于n或者大于m之间的数据:
select * from 表名 where Am; - 查询A列不在n~m之间的数据:
select * from 表名 where A not in(n,m); - 查询A列不为空的数据:`select * from 表名 where A is not null;
like——模糊查询(使用通配符):`
- 查询以n开头的A列:
select * from 表名 where A like 'n%'; - 查询第二位是n的A列:
select * from 表名 where A like '_n%'; - 查询包含n的A列:
select * from 表名 where A like '%n%';
group by——分组:
- 查询按B分组的A列数据:
select A,B from 表名 group by B; - 分组查询中用having代替where
Join操作:
- join(内连接):只有连接的两张表中都存在与条件向匹配的数据才会被保留下来
- left join(左外连接):保留左表数据,右表没有join上的字段显示为null
- right join(右外连接):保留右表数据,左表没有join上的字段显示为null
- full join(满外连接):结果会返回所有表中符合条件的所有记录,如果有字段没有符合条件用null值代替
排序:
Order By(全局排序):
- 升序排序(可省略asc):
select * from 表名 order by 列名 asc; - 降序排序:
select * from 表名 order by 列名 desc;
Sort By(内部排序):
- 对每个reducer端数据进行排序,若只有一个reducer端结果与全局排序相同。
- 设置reduce个数属性(临时):
set mapreduce.job.reduces = n; - 升序排序(可省略asc):
select * from 表名 sort by 列名; - 降序排序:
select * from 表名 sort by 列名 desc;
Distribute By:
- distribute by控制在map端如何拆分数据给reducer端。hive会根据distribute by指定的列,对应reducer的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作,distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
- 先按A列进行排序再按B列进行降序排序:
- select * from 表名 distribute by A sort by B desc;
Cluster By:
- 若distrbute by和sort by是相同字段时,cluster by是distribute by和sort by相结合。
- 被cluster by排序的列只能是降序,不能指定asc和desc。
- 按A列进行排序:
select * from 表名 cluster by A;
select * from 表名 distribute by A sort by A;
上述两语句等价
(8) 分区表操作
- 分区表在hdfs中分目录文件夹。
- 添加单个分区:
alter table 表名 add partition(新分区信息); - 一次添加多个分区用空格分割即可
- 查看分区:
show partitions 表名; - 删除分区:
alter table 表名 drop partition(分区信息); - 修复分区:(通过hdfs上传分区文件)
msck repair table dept_partitions;
(9) 分桶表操作
- 分桶表在hdfs中分文件。
- 适用于非常大的数据集。
- 用户需要统计一个具有代表性的结果或反映趋势(抽样)。
- 创建分桶表语句:
clustered by(字段信息) into n buckets - 开启分桶:
set hive.enforce.bucketing = true; set mapreduce.job.reduces = -1;
- 共m桶,从第n桶开始抽,查看a桶的A列数据(a
select * from 表名(bucket n out of a on A);
(10) 查看数据库结构
desc database 数据库名;
(11) 添加数据库额外描述信息
alter database 数据库名 set dbproperties('key'='value');
(12) 查询数据库额外信息
desc database extended 数据库名;
(13) 查看指定的数据库(使用通配符)
show databases like 'i*';
(14) 删除空库
drop database 数据库名;
(15) 删除非空库标准写法
drop database if exists 数据库名;
(16) 删除非空库
drop database 数据库名 cascade;
(17) 删除非空库标准写法
drop database if exists 数据库名 cascade;
六、Hive-DML(Data Manipulation Language)
(1) 导入数据
- load data [local] inpath ‘/XXXX/文件名’ into table 表名 [partition(分区位置)];
- load data:加载数据
- local:可选操作,加上local导入是本地Linux中的数据,去掉local那么导入的是hdfs数据
- inpath:表示的是加载数据的路径
- into table:表示要加载的对应表
- partition(分区位置):可选操作,向分区表中导入数据时需要指定
(2) 向表中插入数据
insert into table 表名 partition(分区信息) values(数据内容);
(3) 向表中插入sql查询结果数据
insert overwrite table 表名 partition(分区信息) select * from 表名 where 查询条件;
create table if not exists 表名 as select * from 表名 where 查询条件;
(4) 创建表直接加载数据
create table 表名(参数) row fromat delimited fields terminated by '切割符' locatition '';
**注意:**locatition路径是hdfs文件的上一层文件夹,且文件夹内只有这一个文件。
(5) 把操作结果导出到本地linux
insert overwrite local directory '本地路径' select * from 表名;
(6) 把hive中表数据导出到hdfs中(拷贝操作)
export table 表名 to 'hdfs路径';
(7) 把hdfs数据导入到hive中(拷贝操作)
import table 表名 from 'hive路径';
(8) 清空表数据
truncate table 表名;
七、Hive命令
(1) 不登录Hive客户端直接输入命令操作:
hive -e "Hive-DDL语句(注意分号)"
(2) 直接把sql写入到文件中:
hive -f sql路径
(3) 在Hive中可以直接执行hdfs命令操作:
查看hdfs文件:
dfs -ls 路径;
查看hdfs文件内容:
dfs -cat 文件路径;
创建hdfs目录:
dfs -mkdir -p 目录路径;
上传hdfs文件:
dfs -put 文件路径 目录路径;
(4) 查看历史操作
cat ~/.hivehistory
八、UDF自定义函数
(1) 相关概念:
UDF:一进一出
UDAF:聚合函数,多进一出 e.g. count /max/avg
UDTF:一进多出
(2) 查看系统自带函数:
show functions;
(3) 查看系统自带函数示范用法:
desc function extended 函数名;
(4) UDF自定义函数使用:
- <1>. 使用java编写函数(类继承org.apache.hadoop.hive.ql.exec.UDF),导出jar包。
- <2>. 上传至Linux中。
- <3>. 添加jar包:
临时添加:
- 在Hive客户端下输入命令:
add jar jar包路径; - 创建关联:
create temporary function 别名 as "java函数类";
注册永久:
- 修改hive-site.xml配置文件:
hive.aux.jars.path
file://文件夹路径
九、Hive压缩——大量数据节省时间
(1) Map输出阶段压缩方式:
- 开启hive中间传输数据压缩功能:
set hive.exec.compress.intermediate = true; - 开启map输出压缩:
set mapreduce.map.output.compress = true; - 指定压缩编码——设置Snappy压缩方式(高版本Hive自带Snappy):
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
(2) Reduce输出阶段压缩方式:
- 开启hive输出数据压缩功能:
set hive.exec.compress.output= true; - 开启mr输出数据压缩:
set mapreduce.output.fileoutputformat.compress = true; - 指定压缩编码——设置Snappy压缩方式:
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
- 指定压缩类型块压缩:
set mapreduce.output.fileoutputformat.compress.type = BLOCK;
十、Hive进阶
(1) Hive集群搭建
server端配置文件:
hive.metastore.warehouse.dir
/opt/module/hive-1.2.2/warehouse
javax.jdo.option.ConnectionURL
# MySQL数据库位置 jdbc:mysql://bigdata01:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
MySQL用户名
username to use against metastore database
javax.jdo.option.ConnectionPassword
MySQL密码
password to use against metastore database
client端配置文件:
hive.metastore.warehouse.dir
/opt/module/hive-1.2.2/warehouse
hive.metastore.local
false
hive.metastore.uris
# server端地址信息
thrift://bigdata01:9083
# 查询表时显示表头信息
hive.cli.print.header
true
# 显示当前所在的数据库
hive.cli.print.current.db
true
启动:
启动服务器端:hive --service metastore
启动客户端:hive