运动目标跟踪(十六)--OAB,SemiT,BSBT跟踪
原文:
http://blog.csdn.net/ikerpeng/article/details/18985573
文章:on-line boosting and vision
Grabner, H. ; Graz University of Technology ; Bischof, H. CVPR, 2006 IEEE Computer Society Conference on (Volume:1 )
这是cvpr2006年的文章,非常经典的一篇文章。还有源码和数据集下面记录一下我读这篇文章的一些理解。
Boosting的基本思想: 三个臭皮匠抵一个诸葛亮 利用一些容易得到的弱分类器 组合训练形成强分类器。
本文中基本思想就是这样的 关键用到了 :boosting用于特征选取
接下来一步一步的介绍:
1、off-line boosting and on-line boosting
off-line boosting :
首先, 给定一个训练数据集,这个数据集里面含有:L个examples,每一个example有一个m维的特征向量,每一个example还有一个标签1或是-1;用uniform distribution初始化每一个example的权重,即最开始每个example的权重都是1/L
然后,初始化N个弱分类器(which have been generated by repeating training with different subsets of training data!),再通过以上训练集进行训练。第一次训练时,对第一个弱分类器,通过它的错误率确定它的权重,同时更新训练样本集的权重(增加分类错误的example的权重),然后,用现在的训练样本集训练第二个弱分类器,计算它的权重,并更新训练集的权重。如此迭代,将得到的分类器与它的权重相乘,累加起来便得到一个强分类器。
on-line boosting:
思路基本上一样,但是为了实时性,就必须要有少的训练样本,所以在跟踪当中,一般选择第一帧中得到的正负样本进行样本扩充,然后进行训练,训练的过程基本上同上面一致。
2、off-line boosting for feature selection(and online)
核心思想:对于每一个特征,应该有一个响应最好的弱分类器。因此,通过boosting,可以选出最好的特征组。
首先,根据所拥有的正负样本,我们可以得到一个特征池(比如说Harr特征的feature pool;文章中说这个特征池就会是很大,所以要选一个特征池的子集);
然后,从这个特征池中选择少量的训练样本训练出一组弱分类器;
再就是,通过boosting迭代,每一次选出一个响应最好的特征,同时,也根据分类器的错误率计算出相应的权重;
由此,构造出了一个强分类器,也选出了相同数量的响应最好的特征组。
on-line :
on-line boosting for feature selection 最大的不同就是要先随机初始化一组selectors组合一个强分类器,然后再来更新
首先,随机的产生N个selectors,通过通过EM算法产生M个弱分类器;
然后,对于每一个selector,进行更新:通过带权重的sample,对M个weak分类器进行训练,选出错误率最低的那个weak classifier代替这个selector同时,随机的产生一个weak classifier代替错误率最高的那个分类器;
最后,如此迭代,得到一个不断更新的strong classifier (以上部分都是在一个特征池中完成的)
离线学习方法需要一次可以获得全部的训练样本。而当训练样本无法一次性全部获得时,例如数据是一帧一帧到来的,通常我们采用在线学习方法。首先利用第一帧的数据初始化跟踪器,通常当第二帧到达时,再利用第二帧的数据更新分类器。当然,在线更新的框架有很多,方法各不相同。
on-line是不是一直在通过后面得到的信息更新分类器?
是的,但是还有原来保留的信息
若是这样,是不是就是速度慢的原因?也就是漂移的原因?
是的,但是若是不使用在线的话,分类器的适应能力很差。
是的,在线过程中,我们不断利用后面帧中的样本更新分类器,如果样本标记错误,或者更新方式不佳,则很可能导致漂移问题。
文章中提到的卡尔曼滤波是为了构造一个弱分类器吗?
不是 ,文中提到的“卡尔曼滤波”是为了估计正负样本分布的均值和方差。而求得正负样本的均值和方差后,我们可以进一步估计正负样本的高斯分布。实际是为了均值和方差能够稳定,滤波作用。
高斯分布就是为了调节样本的权重吗?
不是,在线学习过程中,高斯分布不是你所说的用于估计样本的权重,而是为了根据文中的公式(12)进一步求得一个图像样本x的弱分类器h(x)的值。)
作者是online boosting的作者。写这篇文章是因为on-line boosting存在一个明显的问题:drifting。每一次对分类器更新所用的样本是上一次得到的结果,即:tracker框出来的部分是正样本,tracker之外的背景是负样本。每一个错误的累加完全可能使得这个tracker得到的结果已经错误。因此,便产生了drifting问题。文章的提出真是要解决这个问题。
文章中提到,视频跟踪中的 这个tracker 要不然就要提前知道每种变化的形态 (这个样的结果就是tracker很复杂),这也就是他所说的 fixed tracker; 要不然就要适应不断变化的背景,这就是所谓的adaptive tracker。 要自适应 ,那么对于在线的跟踪,漂移(drifting)是最大的问题 :每一次我们更新我们的tracker的时候都会有新的错误的引入(introduced)。解决的办法:1、template tracker 2、geometric model 效果都不是很好。
但是本文explore the continuum between fixed tracker and online learning methods 提出: semi-boost 用于跟踪的算法。分别克服了fixed tracker 适应能力差,online tracking drifting的问题。
接下来文章回顾了2006年cvpr的那篇文章中的: boosting算法 和boosting算法用于特征选择(具体的参见上一篇online boosting tracking 阅读)。这个是整篇文章的基础;
然后介绍了:offline semi-supervised boosting还有 semi-supervised on-line boosting for feature selection;
1、off-line semi-supervised boosting
semi-Boost 是结合了graph theory和clustering以及其他方法而形成的算法。基本的思想是:将无标签的样本扩展到loss function(the basic idea is to extend the loss function with unlabeled data)。
为了实现上面说的将unlabeled sample extend into loss function 。于是,引入了一个叫相识度量的量:S(xi,xj),用它来表示两个sample的相识度。
然后,再引入两个叫做:confidence的量:p(x)和q(x)。分别用来表示一个unlabeled sample x 属于正样本和负样本的置信度(很显然:p(x)- q(x)>0 则可以认为这个样本是正样本(这被认为是它的 伪样本 标签)相反就表示负样本),同时也用 p(x)- q(x)的绝对值表示这个样本的权重。而这两个量都和所有的有标签、无标签的样本有关系,同时还和S(xi,xj)有关系。
最后,我们将这些带有伪标签的样本和labeled samples 一起进行boosting迭代,得到一个强分类器。(论文上的公式看起来比较复杂,还是可以定性的理解的)
2、semi-supervised on-line boosting for feature selection
on-line 方法基本思路一样,将无标签的样本扩展到损失函数(the basic idea is to extend the loss function with unlabeled data )。也就是说,我们只要我们给unlabeled sample 确定一个伪标签和一个权重就可以继续往下做了。
但遇到的问题是:上面的公式中的p(x)和q(x)等的计算需要知道所有的labeled and unlabeled samples。但是在online中我们不能得到所有的训练集(since we are in a pure on-line setting we can not access the whole training set!)。于是,我们必须对unlabeled sample进行估计。
按照步骤来说:
首先,对于labeled sample 来说,直接使用 on-line boosting for feature selection approach;
然后,对于unlabeled sample 想办法得到他们的伪标签和权重,再使用上面的方法继续下去。
所以p(x)和q(x)求解就是关键。因为p(x)和q(x)和S(xi,xj)有关,而有参考文献中提到:S(xi,xj)又约等于H(xi,xj)(H是强分类器)。于是,通过给定的labeled sample再学习到一个叫做H+(x)的分类器,它可以来估计S(xi,xj)。最终就可以将p(x)和q(x)表示出来了。也就可以得到 伪标签和权重了 (当然 这个过程中使用到了一个假设:unlabeled sample的个数趋于无穷)。
总结:在semi-supervised on-line boosting 中的具体步骤是这样的:首先,假设在第一帧中得到的跟踪结果是正确的,将这个结果作为正样本,连同随机从背景中得到的负样本,初始化一个分类器;利用这个分类器一个像素一个像素(?)的检测,找到一个响应值最高的地方作为这个被跟踪的物体最可能出现的位置(considered to be the new object position);将tracker中得到的样本分解为小的patch块,作为unlabeled sample(以前的方法是直接将它作为正样本);使用前面的方法计算出这些patch块的伪标签和权重;使用on-line boosting的方法更新分类器,如此不停的迭代。
相似度S(xi,xj)解释:
文章的作者就是半监督boosting的作者,这一篇文章详细的说明了之前那一篇文章中提到的相似度的概念。
半监督学习的过程中,找到一个度量带标签样本和无标签样本的相似度的方法是十分重要的。本篇文章提出了一个相似度方程学习的方式和半监督的方式相互结合的方法。
结合前面的文章我们知道boosting的方法是要最小化一个指数形式的损失方程。这个方程是这样的:  ,而对于半监督学习来说,这个损失函数就变成:
,而对于半监督学习来说,这个损失函数就变成:![]() 。最小化损失函数的过程变成是找到一个响应最好的弱分类器以及得到相应的权重的过程。具体的推导过程在作者的半监督boosting的文章中已经说明了。这里重点是说明了相似度度量的定义和求解的方式。
。最小化损失函数的过程变成是找到一个响应最好的弱分类器以及得到相应的权重的过程。具体的推导过程在作者的半监督boosting的文章中已经说明了。这里重点是说明了相似度度量的定义和求解的方式。
相似度度量S(xi,xj)是这样定义的: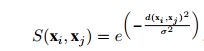 ,其中方差表示的是一个比例参数。d(xi,xj)xi样本和xj样本的距离。这个距离由:
,其中方差表示的是一个比例参数。d(xi,xj)xi样本和xj样本的距离。这个距离由:
![]() 决定,其中Hd是一个训练过的、归一化的分类器。取值为[-1,1]。于是,我们知道得到这个分类器便可以求得损失函数取得最小值时的那个弱分类器和它的权重了。而在训练的过程中,假设现在已经有一个先验的分类器了。对于两个样本,显然,他们通过这个分类器得到的结果越是相同表明他们越是相似。于是通过这种想法得到距离新的计算方法:
决定,其中Hd是一个训练过的、归一化的分类器。取值为[-1,1]。于是,我们知道得到这个分类器便可以求得损失函数取得最小值时的那个弱分类器和它的权重了。而在训练的过程中,假设现在已经有一个先验的分类器了。对于两个样本,显然,他们通过这个分类器得到的结果越是相同表明他们越是相似。于是通过这种想法得到距离新的计算方法:![]() 于是,接下来的步骤和半监督boosting的方法相似。
于是,接下来的步骤和半监督boosting的方法相似。
****************************************************************************************************************************************************************************************************************************************************************************
这篇文章是中科院自动化所2009年发在ICCV上面的文章。用一句话来总结这篇文章是:The most important contribution is that we find a boostingerror upper bound in a co-training framework to guide the novel tracker construction。这篇文章正是发现一般的boosting和co-training的方法,他们的得到的结果的错误率有一个上界。于是找到这个错误率,并通过对它的最小化来引导tracker的生成。由此便得到了一个准确率很好的tracker。作者同时还对这个上界进行了证明。这就是这篇文章主要做的工作。(足见作者的数学功底)
看完了论文的introduction后知道09年前的主要的tracking的算法和他们的特点:1、LDA 简单但是tracker效果不能很好的提高;2、基于SVM的support vector tracker效果好,但是降低了对于复杂背景的适应能力;3、使用多特征的Ensemble tracker 有明显的优势,但是他是对pixel操作的,丢失了很多的结构信息;4、on-line boosting有很好的适应能力,但是会漂移(用文章的原话说是:self-training process which use the classification results toupdate the classifier itself)。很明显作者也关注到06年的这篇on-line boosting的文章中存在的问题:拿检测到的结果来更新分类器。于是他也想到了半监督的方法(这篇论文的作者08年的另一篇论文就是通过semi-supervised方法改进了这篇论文)。不同的是他通过co-training和boosting的方法。
如他的文章所说,他不是简单的将boosting和co-training合起来,而是导出boosting error的上界,并由此构造分类器。如下面的Eq(1)所示,是一个有adaboost构造的强分类器。

而这个强分类器的错误如Eq(2)所示,其中的Zt如Eq(3)所示。而Eq(3)中的Dt(i)表示第i个sample第t次训练时的归一化权重。结合Eq(1)就可以推导出Eq(2)。比较好理解。
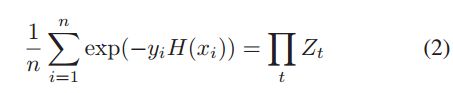

而下面的这个式子是在2007年的一篇叫做:Bayesian co-training的文章中推导出来的。其中的j是Multi-view algorithm(多视角算法)中的系数,代表视角的个数。 本文中的view有两个,即:j=2 。可见,若是使用贝叶斯决策构造分类器就满足该式子。我们也由此知道这类错误有一个上界如Eq(4)所示。Eq(5)则是通过co-training构造的最终的强分类器。
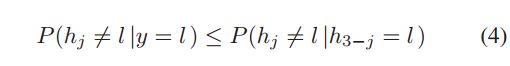

接下来,作者花了大量的章节来证明这个错误函数是有上界的。
首先,证明了下面的这个式子。证明的过程大概是这样的:在不失一般性的情况下,做三个假设:1、training sample 量很大;2、在不同视角(view)中的特征所给的标签条件独立;3、依照不同的视角的决策大体是一致的。然后,根据前面的Eq(2)(5),最重要的是在做Eq(1)的转化便可以证明出来。
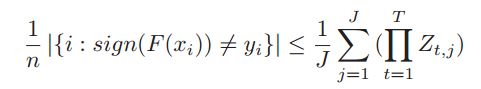
但是这里有个问题,上面的证明是认为所有的样本都是有标签的,于是推导到半监督的学习当中。将所有的样本分为两部分来求解,有标签的和上面一样;没标签的通过错误率来推导,关键步骤用到了Eq(4)。具体的证明还是要认认真真的看论文原文。
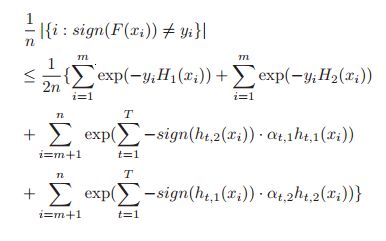
证明了上面的结论后,就可以使用它来构造分类器了。下面具体列出本文使用的特征和方法。
本文对100帧图像进行跟踪,对比其他算法。将其中的前十帧作为是有标签的,用来训练。后面的90帧样本作为无标签的,用来测试。对前十个样本,建立两种特征池,一种是颜色特征(49种组合的color feature),另一种是LBP特征(25种)。通过这两种特征构造直方图,分别用来训练分类器(也就是说,这里采用的muti-view算法中的视角数是2,即j=2)。这里的弱分类器是通过bayesian decision criterion 构造的(也就说他的错误的大小存在一个上界,如Eq(4))。
到此刻,前期的准备工作都已经完成。接下来的重点就是如何来更新分类器的问题了。作者的基本思路还是使用boosting方法:分别更新两个视角中每个弱分类器以及它们的权重。然后综合两个视角的结果(co-training)构造强的分类器。关键的不同时更新规则的不同。首先找到这种分类器的错误的表达式;然后,得到它的上界;最后,将这个上界最小化,于是相应的选出错误最小的那个弱分类器以及得到它的权重,组合构造出强分类器。算法的伪代码如下:

文章的优点:使用co-training半监督的方法,很好的结合了labeled和unlabeled样本,克服了on-line算法的漂移的问题。
缺点:推导较为复杂不易传播推广;以前十帧作为训练样本,不知道这是不是他的算法比别人的好的原因。