密集人脸对齐-Dense Face Alignment_ICCVW 2017
Dense Face Alignment论文翻译,原文参考:http://cvlab.cse.msu.edu/project-pifa.html
摘要:
在人脸对齐方法中,以前的算法主要集中在特定数量的人脸特征点检测,比如5、34或者68个特征点,这些方法都属于稀疏的人脸对齐算法。在本文中,我们提出了一种针对大角度人脸图像的一种3D密集人脸对齐算法。在该模型中,我们通过训练CNN模型利用人脸图像来估计3D人脸shape,利用该shape来fitting相应的3D人脸模型,不仅能够检测到人脸特征点,还能匹配人脸轮廓和SIFT特征点。此外还解决了不同数据库中由于包含不同数量的特征点(5、34或68)而不能交叉验证的问题。
1. 算法介绍
密集人脸对齐算法将人脸图像匹配到一个最佳的3D人脸模型上,这些3D人脸模型中包含数以千计的特征点,从而实现了密集的人脸对齐。但是我们仍然面临两个问题:目前基于3D人脸模型匹配的人脸对齐算法仅仅利用稀疏的特征点来构造,如果要实现高质量的密集人脸对齐(DeFA),面临的首要问题就是没有相应的训练数据库,所有的人脸对齐数据库中标记的特征点都不超过68个特征点,所以我们需要寻找有用的信息来作为额外的限制条件,并将这些信息嵌入到学习框架中。面临的第二个问题就是需要各种的训练数据,但是不同的人脸对齐数据库标记的特征点个数不一样。
解决第一个问题:增加额外的约束(additional constraints)
1) 轮廓约束:预测的3D人脸轮廓应该和2D图像中检测到的人脸轮廓相匹配
2) SIFT约束:同一个人脸的不同图像中关键SIFT特征点应该对应于3D模型中同一个特征点
解决第二个问题:3D人脸模型匹配算法本身就可以针对不同的数据库,由于每个3D人脸模型都是标准的,即使不同的数据库中人脸标记的特征点数不同,都能够找到相对应的3D模型
主要贡献:
1) 定义了一个密集人脸对齐问题,能够利用稀疏的人脸特征点进行密集人脸对齐
2) 为了实现上述目的,定义了一个新的3D人脸模型拟合算法,通过加入多个约束和跨数据库训练来构建
3) 该模型性能优异,能够实时运算
2. 密集人脸对齐
2.1 3D人脸表示
利用矩阵S来表示人脸的3D shape,根据3DMM的表示方法,可以表示如下
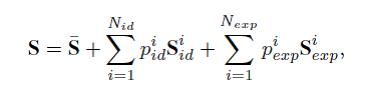
该表达式有三部分组成:shape均值,个体差异的shape基函数(199个),表情差异的shape基函数(29个),每一个基函数都是53,215维数的向量
得到三维S之后可以利用投影矩阵来得到相应的密集人脸shape A:
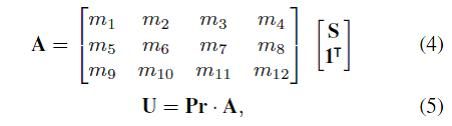
其中A是投影矩阵,包含六个自由度,可以模拟尺度,旋转和线性变换。得到A以后可以通过正交二维投影矩阵Pr投影到2D平面,得到矩阵U。
在2维平面中,Z坐标变换系数m12设为0,根据投影矩阵的性质可以得到
![]()
因而一个任意2D人脸图像的密集特征点可以通过计算8维的参数m和228维的系数p来实现,进而将3D的密集人脸对齐模型转化为参数m和p的计算问题。(具体参考3DMM算法)。整个流程可以表示为:
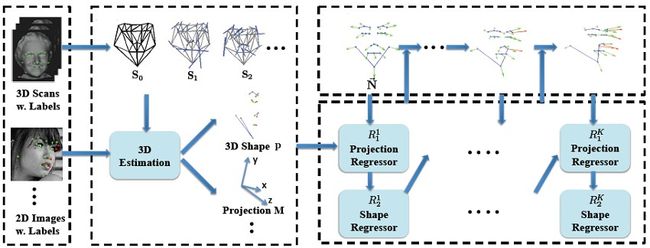
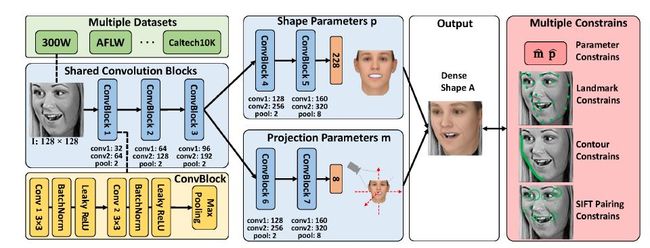
2.2 CNN体系结构
我们采用CNN网络来学习从输入图像I到相应的投影参数m和shape参数p的非线性映射关系。如上图所示我们采用两个分支来分别学习shape参数p和projection参数m。两个分支共用前三个卷积块,然后每个分支分别采用两个不同的卷积块来提取相应的参数,在这之后利用两个全连接层将参数转化为最终的输出。其中,每一个卷积块都由两个卷积层和一个最大池化层组成,每一个卷积层后面跟着一个BN层和Leaky ReLU层。
2.3 损失函数
为了提高CNN模型的性能,我们在损失函数中融合了多种限制,可以表示为:
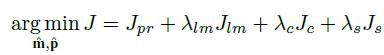
下面分别介绍这四种限制的公式和引入的目的:
1) Jpr是参数限制(Parameter Constraint, PC),目的是最小化估计的参数和真实参数的误差,可以定义为:
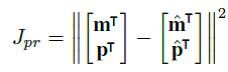
2) Jlm是标定点拟合限制(Landmark Fitting Constraint, LFC),目的是最小化估计的2D landmarks和真实的2D landmarks labeling Ulm的误差。由于3D的人脸模型的特征点是密集的,对于任何一个2D的人脸图像,选取与其特征点对应的坐标ilm,然后利用估计的参数m和p来计算矩阵A,并选取与2D人脸相对应的特征投影到2D平面,然后再计算误差,其中L为landmarks的个数。
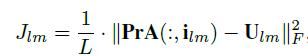
3) Jc是轮廓拟合限制(Contour Fitting Constraint , CFC),目的是最小化估计的轮廓和真实轮廓之间的误差(与上一个相对应,一个是landmarks对应于脸上的特征点,一个是轮廓的特征点,组成一个完整的人脸)。为了计算该误差需要以下三步:
(1)检测2D人脸图像的真实轮廓;
(2)描述估计的3D形状A的轮廓点;
(3)确定真实轮廓和估计轮廓的对应关系,反向传播(BP)拟合误差。
针对上面三个步骤,具体方法如下:
(1)采用现成的边缘检测算法HED来检测人脸图像的轮廓Uc(CNN训练前进行离线检测);
(2)利用Delaunay三角剖分算法来检测3Dshape中的轮廓点;
(3)由于3Dshape中的轮廓点是完整的,我们只需要计算2D轮廓中每个像素点和3Dshape轮廓中最近的点的距离,然后计算累计误差的最小值。(注:需要找好和2D人脸图像对应的3Dshape)

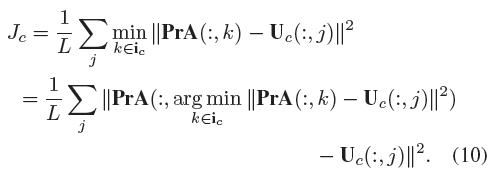
4) Js是成对SIFT特征限制(SIFT Pairing Constraint, SPC),目的是保证密集3Dshape在关键点的检测是一致的,例如边缘,皱纹和痣等。我们利用SIFT特征来检测和表征成对人脸的显著特征点。成对人脸可以选取同一个人的不同表情或姿势,也可以是同一张人脸进行旋转、裁剪或3D增强以后的人脸图像。对于一对人脸图像i和j,我们分别检测他们的SIFT特征并进行匹配,然后利用这些特征点分别找到3Dshape中对应的vertices,然后计算他们的交叉误差,并进行最小化。公式可以表示为:
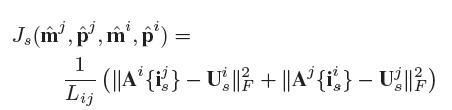
其中
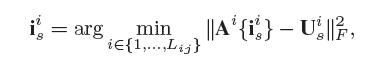

3. 实验
3.1 实验设置
训练过程分为三个步骤:
1) 利用300W-LP数据库来训练带有Jpr约束的DeFA神经网络(参数计算);
2) 进一步利用Caltech10K和COFW数据库来训练带有Jpr和Jlm约束的DeFA网络;
3) 利用SPC和CFC约束对网络进行微调,对于大姿势的人脸对齐采用AFLW-LFPA数据库进行微调,对于接近正脸的人脸对齐采用300W数据库进行微调(具体的训练过程参照原文表2)
模型框架:采用MatConvNet来实现,相应的参数参考原文
评价指标:采用规范化的MSE,对于大角度人脸利用boundingbox size来规范化,对于近正脸人脸利用两眼间的距离。
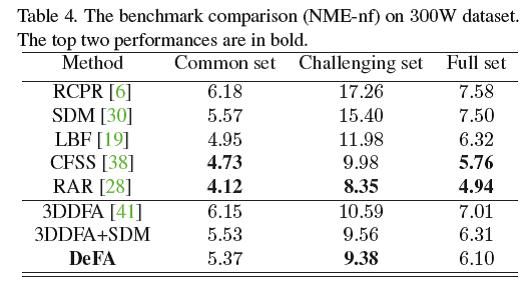
3.2 实验结果
1. 大角度人脸对齐:其中3DDFA和PAWF算法也是利用类似的策略来估算参数m和p,都是利用3DMM模型。

2. 近正脸人脸对齐:效果好于3DDFA,比最好的差一点
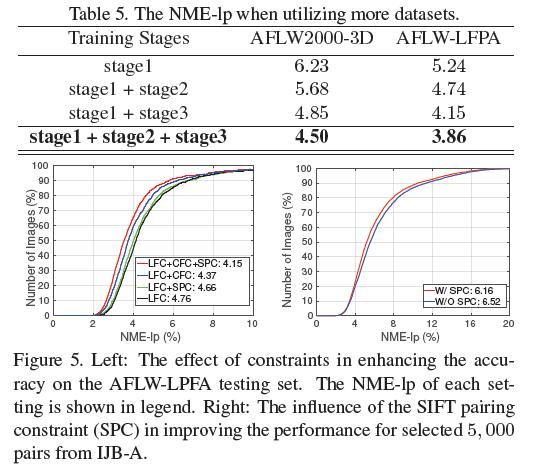
3. 各个训练阶段对性能的影响(由于不同阶段训练时采用了不同的库,因而结论需要进一步验证):对比表格的第二行和第三行,可以发现CFC和SPC对性能的影响超过LFC(说明轮廓和SIFT特征比Landmark的约束更有用);对比右图可以发现CFC对性能的影响超过SPC(说明轮廓比SIFT能够提供更有效的信息);在NME-lp位于5%~15%时,SPC约束能够起到作用。
4. 分析
总体来说该方法的优劣可以总结为:
1) 由于添加了三个额外的约束LFC(特征点),CFC(轮廓)和SPC(SIFT特征)使得训练过程复杂,不易重复
2) 每个阶段采用不同的数据库进行训练,没有选择的标准,不利于推广
3) 实验结果证明CFC+SPC>LFC,CFC>SPC, SPC在NME-lp位于5%~15%时才能起到更好的作用,所以可以根据个人需要进行取舍
个人观点,刚刚看face alignment第一天,不对之处请拍砖,后续会更新和改正
参考文献位置:
http://cvlab.cse.msu.edu/project-pifa.html