hive基础知识(hive 0.1.4)



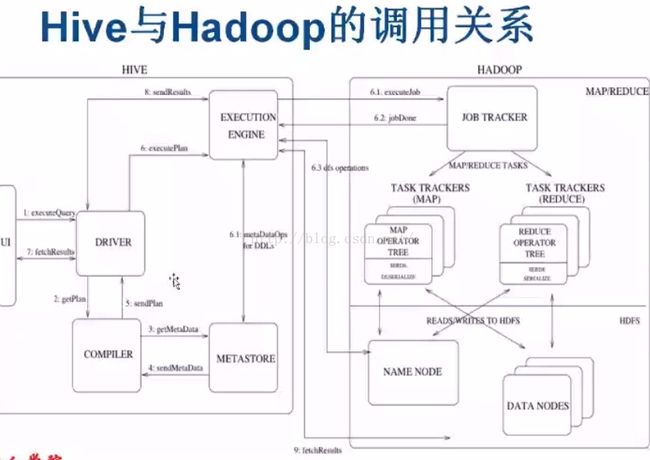
1、提交sql 交给驱动
2、驱动编译 解析相关的字段表信息
3、去metastore查询相关的信息 返回字段表信息
4、编译返回信息 发给驱动
5、驱动发送一个执行计划 交给执行引擎
6.1、DDLs 对数据库表的操作的 直接和metastore交互
create table t1(name string);
6.1、把job交给job tracker 让task tracker执行 返回执行信息
6.2、完成job返回数据信息、找namenode查数据
6.3、namenode交互
select count(1) from t1;
6.1、dfs ops 直接取数据
select * from t1;
7、返回结果信息集
6.1metaDataOps for DDLs
例如 create table xxx 数据库定义语言,不需要执行mapreduce
6.3 dfs operation
直接查询 hdf的情况 例如 hadoop fs -ls /
调用hive的方式
https://my.oschina.net/repine/blog/192700
在控制台上,没有进入hive命令模式下可以执行如下命令
hive -e “show tables”执行段语句
-S安静的执行,不打印详细信息
hive -S "show tables"
从文件中执行sql脚本-f
hive -f sql
sql是个文件名,里面写hive脚本,如 show tables
-i初始化,执行完脚本后进入hive命令模式
hive -i sql 执行
进入hive命令模式下(hive>),可以用source命令执行脚本文件
source hive
通过!可以将执行linux命令
!ls 这就可以显示当前目录下的所有文件
由于hive是基于hadoop下运行的,所以可以在hive命令模式下直接执行hadoop命令
dfs -ls /
查看hadoop目录下的文件
启动jdbc模式,使得java代码可以调用hive的jdbc建立连接(org.apache.hive.jdbc.HiveDriver),服务端口号10000
hive --service hiveserver2
设置参数
在控制台:
hive命令窗口模式:
set cli.print.current.db=true
如果想参数设置永远生效,则将命令写在~/.hiverc文件中
注意:设置语句末尾一定要写分号
hive.cli.print.current.db=true;
查询数据时显示表头
set hive.cli.print.header=true;
设置变量
set hivevar:name=age
create t2(name string,${hivevar:name} string);
hive复合数据类型
array,map,struct,union
默认分隔符
|
分隔符
|
描述
|
语句
|
|
\n
|
分隔行
|
LINES TERMINATED BY '\n'
|
|
^A
|
分隔字段(列),显示编码使用\001
|
FIELDS TERMINATED BY '\001'
|
|
^B
|
分隔复合类型中的元素,显示编码使用\002
|
COLLECTION ITEMS TERMINATED BY '\002'
|
|
^C
|
分隔map元素的key和value,显示编码使用\003
|
MAP KEYS TERMINATED BY '\003'
|
002,"dukun":13
class_test:
"wuke",1:2:3:4
"duke",5:6:7:8
select name,list[0] from class_test;
select name,list[30] from class_test;
list[30]会显示null,不会有角标越界问题
Map:
create table employee(id string,perf map
load data local inpath "/home/hadoop/hivetestdata/emplyeedata" into tableemployee;
emplyeedata:
1001 job:80,team:60,person:70
1002 job:100,team:90,person:30
1003 job:60,team:40,person:90
1004 job:50,team:70,person:80
select id,perf['job'] as job from employee;
创建数据库
create database if not exists mydb;
删除数据库
drop database if exists mydb ;
删除带表的数据库
drop database if exists mydb cascade;
查看mydb数据库中 的表
show tables in mydb
查看mydb数据库中 的以class开头的表
show tables in mydb ‘class*’
查看表详细信息
desc formatted employee
创建一个和employee一样的表ee
create table ee like employee
跨数据库创建一个和employee一样的表ee
create table ee like defalut.employee
将hive脚本写在文件中,通过hive -f 执行脚本
hive -f hive.sql