AlphaGo之后又来了AlphaStar,这个更厉害。。。

刚刚,我们见证了 AI 与人类 PK 的又一次重大进展!DeepMind 北京时间 1 月 25 日凌晨 2:00 起公布了其录制的 AI 在《星际争霸 2》中与2位职业选手的比赛过程:AlphaStar 5:0 战胜职业选手TLO ,5:0战胜 2018 年 WSC 奥斯汀站亚军 MaNa 。与两位人类对手的比赛相隔约两周,AI 自学成才,经历了从与 TLO 对战时的菜鸟级别,进化到完美操作的过程,尤其是与 MaNa 的对战,已经初步显示了可以超越人类极限的能力。
这次的演示也是 DeepMind 的星际争霸 2 AI AlphaStar 的首次公开亮相。除了此前比赛录像的展示外,AlphaStar 还和 MaNa 现场来了一局,不过,这局AlphaStar 输给了人类选手 MaNa 。
图 | MaNa 正在聚精会神比赛(图源:Youtube)
DeepMind 在演示中介绍,双方的比赛固定在 Catalyst LE 地图,采用 4.6.2 游戏版本,而且只能进行神族内战,双方将进行 5 场比赛。首先接受邀请的是 Liquid 战队的虫族选手 TLO,目前世界排名 68。
 图 | TLO(图源:Youtube)
图 | TLO(图源:Youtube)
第一场比赛,TLO 出现在 10 点钟方向,AlphaStar 出现在 4 点钟对角方向。TLO 的开场非常传统,采用了双兵营封路的开局,但 AlphaStar 并没有封路,这一问题被 TLO 的农民侦查到,他果断拍出使徒,采用了常见的杀农民骚扰策略。
虽然 AlphaStar 没有封路,直接放进了 TLO 的使徒,但 AlphaStar 的双兵营也造出了使徒防守,导致 TLO 的第一次骚扰只杀掉了两个农民,剩下的使徒也无功而返。
随后双方都开始补出追猎,TLO 开始用先知骚扰。双方进行了多个小规模交战,几波互换几乎平手,AlphaStar 损失的农民较多,TLO 损失了多个使徒。在交战中,我们看到了 AlphaStar 进行了类似人类的微操,一边撤退,一边反打 TLO 的追猎,同时利用棱镜传输兵力。

图 | AlphaStar 的视野,它可以看到全地图战争迷雾之外发生了什么,然后做出决策,实现全局资源调度(图源:Youtube)
不过 TLO 此时的二矿刚刚建好,AlphaStar 只有单矿,将更多的经济转化成了兵力,因此 AlphaStar 爆出了更多的追猎,直接选择进攻二矿,TLO 的追猎寡不敌众,在主力兵力被歼灭后打出 GG。
第一局以 DeepMind 的胜出为结果,我们看到了 AlphaStar 的一些不同寻常做法,比如不选择互相骚扰农民,而是直接用兵力防守,然后发现 TLO 拍下二矿之后,在正面战场用一定数量的追猎持续压制。
由于时间限制,演示中并没有播放所有比赛,而是在展示了另外一局比赛录像后,给出了 TLO 五局全败的战绩。不过所有的录像都将在 DeepMind 官网上放出,供人下载。
TLO 在演示中表示,他觉得自己还是可以赢的,如果能够有更多的训练时间,对 AlphaStar 有更多的了解,是一定可以找到 AlphaStar 弱点,然后获胜的。
随后登场的是 Liquid 战队 MaNa,作为排名 19 的神族选手,他比 TLO 更加强大。如果 AlphaStar 可以战胜他,那将说明 AlphaStar 真的具备了人类顶尖选手的实力。
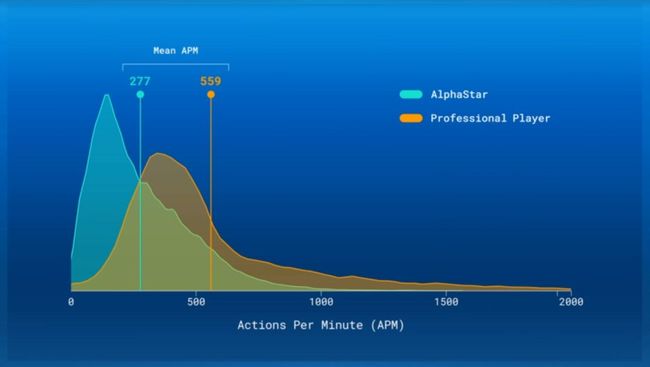
图 | AlphaStar 和人类选手的 APM 并没有太大区别(图源:Youtube)
与 MaNa 的第一局,双方都是“常规”开局,MaNa 封路,AlphaStar 没有封路。不过 AlphaStar 采取了变种战略,选择在 MaNa 基地附近放下水晶,拍下两个兵营,准备利用兵营距离的优势进攻。MaNa 此时还在按照人类的思路,利用使徒骚扰农民。
在 AlphaStar 兵营快完成的时候,被 MaNa 发现,他果断采取了防守措施,在高坡建造了两个充电站,准备利用封路和高坡的优势防守即将到来的追猎大军。按照 MaNa 的想法,“正常的人类选手是不会走上那个高坡的”。
但是 AlphaStar 并不是人类,它犹豫两次之后选择直接攻上高地,由于追猎数量碾压 MaNa,野兵营还在源源不断地输出追猎,因此充电站几乎没有效果,几轮点射之后,MaNa 的追猎所剩无几,最终拉出所有农民也没能挽回败局,宣告失败。
在随后的两局录像复盘中,我们看到了 AlphaStar 的强大微操和战术思路,它会学习和尝试人类的封路战术,生产额外的农民缓解骚扰带来的影响。在一局比赛中,我们看到了 AlphaStar 使用了纯追猎战术,仅靠强大的微操对抗 MaNa 的追猎、不朽和叉子组合的混合军队。

图 | 实时战局(图源:Youtube)
AlphaStar 将 30 多个追猎分成 2-3 组,从 3 个方向包夹 MaNa 的进攻部队,然后靠闪烁躲避 9 个不朽的攻击,这种非人类的操作彻底摧毁了 MaNa 的操作空间——无论他建造多少个不朽,都没有办法抵抗追猎大军。“这种情况在同水平人类对局中完全不会出现,”MaNa 在演讲中无奈地说道。
最终 MaNa 也以 0-5 的成绩败北,人类与 AlphaStar 的 10 局比赛结果全是失败。
不过在演示直播中,DeepMind 似乎有些膨胀,选择与 MaNa 进行了一场即时表演赛,后者也表示,自己要为 Liquid 战队正名,捍卫战队和人类的荣誉。
双方常规开局,在前期并没有进行大规模交战。但 MaNa 显然是有备而来,没有使用使徒和先知骚扰,而是专注于侦查和攀升科技。在发现 AlphaStar 依旧生产了茫茫多追猎后,MaNa 采用了棱镜运输不朽的骚扰战术,同时补出不朽、叉子和执政官等混合部队。这可谓是整场比赛的神来之笔。

图 | 三个先知围着棱镜看热闹(图源:Youtube)
在空投不朽骚扰农民时,AlphaStar 并没有选择补出凤凰打击棱镜,而是用不能攻击空中单位的先知跟踪棱镜,辅以数十个追猎来回往返前线和家中。看起来,它认为追猎可以对空攻击,因此不需要补出凤凰,而且似乎所有追猎都在一个分组内,没有分批分别执行进攻和防守任务。
于是我们看到了人类玩家对抗 AI 的典型方法:逼迫后者陷入循环执行某种任务的怪圈,使其浪费巨额时间和资源,无法形成有效的局势判断。
就这样,MaNa 消耗到了自己的兵力成型,然后一波压制直接瓦解了 AlphaStar 的纯追猎部队。后者还尝试利用包夹的战术阻挡 MaNa,但这一次 MaNa 的兵力充足,不朽对追猎的克制十分明显,没有留给 AlphaStar 一丝操作的机会,全歼对手,获得了宝贵的胜利。
图 | MaNa 获得表演赛胜利,露出了迷之微笑(图源:Youtube)
虽然 TLO 和 MaNa 的录像以全败告终,宣告了 DeepMind AlphaStar 的实力已经不可同日而语,但这场表演赛充分暴露了 AlphaStar 目前的不足。
我们不难看出,尽管其神经网络已经趋于长期优化,但似乎仍然会在一定程度上陷入局部最优,被人类发现固定模式,落入圈套,而且从 5 个小叮当抱团,到纯追猎部队,都显示出它对游戏兵种的理解尚不到位,如果最后一局它可以像人类一样直接派出凤凰防守棱镜,或许它将继续凭借超强的微操一波推平 MaNa。
比赛回放过程中,主持人问到 DeepMind 科学家,平时如何训练 AlphaStar,DeepMind 科学家 Oriol Vinyals、David Silver 表示,首先是模仿学习,团队从许多选手那里获得了很多比赛回放资料,并试图让 AI 通过观察一个人所处的环境,尽可能地模仿某个特定的动作,从而理解星际争霸的基本知识。这其中所使用到的训练资料不但包括专业选手,也包括业余选手。这是 AlphaStar 成型的第一步。

图 | DeepMind 科学家 Oriol Vinyals(图源:Youtube)

图 | DeepMind 科学家 David Silver(图源:Youtube)
之后,团队会使用一个称为“Alpha League”的方法。在这个方法中,Alpha League 的第一个竞争对手就是从人类数据中训练出来的神经网络,然后进行一次又一次的迭代,产生新的 agent 和分支,用以壮大“Alpha League”。

图 | Alpha League 示意图(图源:Youtube)
然后,这些 agent 通过强化学习过程与“Alpha League”中的其他竞争对手进行比赛,以便尽可能有效地击败所有这些不同的策略,此外,还可以通过调整它们的个人学习目标来鼓励竞争对手朝着特定方式演进,比如说旨在获得特定的奖励。
最后,团队在“Alpha League”中选择了最不容易被利用的 agent,称之为“the nash of League”,这就是 TLO 所对战的5个。
为什么是"星际争霸 2"?
![]()
比赛前期,DeepMind 与暴雪就联合发布了关于此次比赛的重磅预告:将在北京时间周五凌晨 2 点展示 Deepmind 研发的 AI 在即时战略游戏星际争霸 2 上的最新进展。如今,这个进展终于揭开神秘面纱。
而 DeepMind 开发星际争霸 2 AI,最早可以追溯到 2016 年。当时,DeepMind 研究科学家 Oriol Vinyals 在暴雪嘉年华现场透露 Deepmind 与星际争霸 2 紧密合作的最新进展及未来的计划。在 AlphaGo 在 2017 年围棋大获全胜之后,DeepMind 开始对外宣布,团队正在着手让人工智能征服星际争霸 2,这款游戏对人工智能在处理复杂任务上的成功提出了"重大挑战"。
在 2018 年 1 月的 EmTech 大会上,谷歌 DeepMind 科学家 Oriol Vinyals 曾对 DT 君表示,第一版的 AlphaGo 击败了樊麾,后来下一个版本在韩国和李世石进行了对弈并取得了胜利。再后来进一步地训练网络,整个网络比之前强了三倍,赢了柯洁和其他专业棋手。团队是从零开始,一点点积累积数据训练,最后战胜了专业棋手。而除了棋类游戏以外,DeepMind 比较感兴趣的,就是游戏星际争霸 2。
继围棋之后,DeepMind 为什么要选择星际争霸 2 这款游戏为下一个目标呢?
星际争霸 2 是由美国著名游戏公司暴雪娱乐(Blizzard Entertainment)推出的一款以星际战争为题材的即时战略游戏。星际争霸 2 具备策略性、竞争性的特性,在全球都非常火爆,并且每年都会举办大量的比赛,因此也有着海量的玩家基础。

图丨谷歌 DeepMind 科学家 Oriol Vinyals(来源:DeepTech)
据 Oriol Vinyals 当时透露,星际争霸 2 是非常有趣和复杂的游戏,这个游戏基本上是建造一些建筑物以及单位,在同一个地图里不同的组织会相互竞争。在这个游戏中,哪怕只是建造建筑物,也需要做出许多决策。除此之外,还要不断收集和利用资源、建造不同的建筑物、不断扩张,因此整个游戏非常具有挑战性。
而且,和围棋任务最大的不同在于,围棋可以看到整个棋盘,但是在星际争霸 2 中我们通常无法看到整个地图,需要派小兵出去侦查。另外,游戏是不间断进行的。整个游戏甚至会有超过 5000 步的操作。对于增强学习这种方法来说,除了上下左右这些普通的移动,用鼠标点击界面控制不同物体的移动以及不同的行为也是非常难的。
星际争霸 2 的这些特质,恰恰是人工智能在创新之路上需要挑战的——面对许多难以预测的突发情况,人工智能必须要既作出正确的对策,还要根据实际情况细微的调整对策。

(来源:DeepMind)
星际争霸 2 作为"即时战略"游戏,其"即时"和"战略"的特性无疑是锻炼 AI 的最佳途径之一。就拿"即时"来说,或许对于人类,星际 2 的那 300 多个基础操作的"操作空间"(Action Space)并不庞大。但是对于机器,星际 2 的分级操作,外加"升科技"所带来指令的变化,再加上地图的体积,其操作空间是无穷大的。比如"农民建房子"这个简单的行动就有 6 个不同的步骤:点击滑动鼠标选择单位,B 选择建造,S 选择供给站,滑动鼠标选择位置,点击建造。仅在一个 84x84 的屏幕上,机器的操作空间有大约 1 亿个可能的操作。
AlphaGo Zero 创造者:"这个比围棋难多了"
![]()
在 DeepMind 与暴雪长期以来的合作中,有几个重要节点:
2017 月 8 月,星际争霸 2 开发团队发布人工智能研究环境 SC2LE(StarCraft II Learning Environment),它包括一个能让研究人员和开发人员与游戏挂钩的机器学习 API,开放了 65000 场比赛的数据缓存,以及 50 万次匿名游戏回放和其他研究成果。其中一些数据对于训练和辅助序列预测和长期记忆研究非常有用,当时团队也希望通过这些工具,帮助研究人员加快星际争霸 2 AI 的开发速度。
图丨 Julian Schrittwieser(来源:麻省理工科技评论)
SC2LE 发布不久以后,AlphaGo Zero 创造者之一、《麻省理工科技评论》TR 35 获得者 Julian Schrittwieser 在在一场网络互动中表示:星际争霸 2 的 AI 尚处早期,研发难度比围棋人工智能更大,在 AlphaGo Zero 诞生之后,团队希望能以此为契机,在 AI 研究上再次实现突破。
团队与星际争霸 2 相关的第一篇公开论文,则出现在 2018 年 6 月。当时,DeepMind 在 arXIv 发布其最新研究成果:用关系性深度强化学习在星际 2 六个模拟小游戏(移动、采矿、建造等)中达到了当前最优水平,其中四个超过人族天梯大师组玩家。
之后,直到 2018 年 11 月,在暴雪的一场展会上,我们才再次得知这个项目的进展——DeepMind 团队曾展示了能够执行基本的集中策略以及防御策略的人工智能进展:在掌握游戏的基本规则后,它就会开始表现出有趣的行为,比如立即冲向对手攻击,研究团队还公布其 AI 在对抗"疯狂"电脑时也有 50% 的胜率。
对比 3 个月后的今天,从 DeepMind AI 在比赛中的表现,不得不说其进步之快。
接下来另一场值得期待的"大战",将发生在 2 月 15 日:在星际争霸 2 AI 直播预告公布后,芬兰电竞战队 ENCE 也发布通告,称 WCS 星际争霸 2 全球总冠军芬兰选手 Serral 将在与星际 2 人工智能上演一场人机大战。届时 AI 与人类顶尖选手的对战,或许还将会再次创造新的历史事件。

图 | ENCE通告(图源:Twitter)
今年的"人机大战"看什么?打造通用性 AI 依然"道阻且长"
![]()
近几年,除了 DeepMind 以外,已经有越来越多的人工智能公司或者研究机构投身到开发游戏类AI的浪潮中,例如 OpenAI 和腾讯的 AI lab 等等。
归根结底,这些团队对游戏AI的热情,恐怕都源于打造通用型人工智能的这一终极目标:游戏AI的研发将会进一步拓宽人类对于AI能力的认知,这样的研究最终将探索的问题 AI 能否能够通过游戏规则进行自主学习,达到更高层次的智能乃至通用型人工智能。例如,在游戏AI的设计中,增强学习算法的改进将至关重要。增强学习是一种能够提高 AI 能力的核心算法,它让 AI 能够解决具有不确定性动态的决策问题(比如游戏 AI,智能投资,自动驾驶,个性化医疗),这些问题往往也更加复杂。
而 DeepMind 团队的成果已经为此带来了一丝曙光—— AlphaGo Zero在短时间内精通围棋、象棋、国际象棋三种棋类游戏,已有棋类通用AI雏形。棋类游戏之后,最值得期待的进展,就是各家开发的AI在即时战略类 RTS 游戏或多人在线竞技类 MOBA 游戏上的表现了。此前,腾讯 AI Lab 负责人之一姚星就介绍过,在游戏AI的研究上,腾讯 AI Lab 已从围棋 AI “绝艺”等单个 AI 的完全信息博弈类游戏,转移到规则不明确、任务多样化、情况复杂的游戏类型,如星际争霸和 Dota2 等复杂的即时战略类 RTS 游戏或多人在线竞技类 MOBA 游戏。

图丨 OpenAI 宣布他们所打造的一个 AI 机器人已经在电子竞技游戏 Dota 2 中击败了一个名为 Dendi 的人类职业玩家(来源:OpenAI)
在刚刚过去的2018年,OpenAI 开发出的 AI OpenAI Five 就是针对 Dota2 开发的AI,但是它与人类 PK 的过程可谓充满戏剧性。2018 年 8 月初,OpenAI Five 战胜一支人类玩家高水平业余队伍(天梯 4000 分左右),然而,到了 8 月底 OpenAI Five 被两支专业队伍打败, AI 提前结束了其在本届 DOTA 2 国际顶尖赛事 TI 8 的旅程。回顾那次失败的过程,其实OpenAI 的系统仍然无法全面理解 DOTA 复杂的游戏系统和规则。
现在,DeepMind 的星际争霸2 AI 已经以其超强实力打响游戏 AI 2019 年第一战,接下来还有哪些游戏AI将横空出世呢?各大游戏AI又将如何迈向通用人工智能,让我们拭目以待。
![]()
1.2019年第1期《单片机与嵌入式系统应用》电子刊新鲜出炉!
2.如何评判STM32各个MCU的性能?
3.连好莱坞都在讨论互联网。。。
4.我是MCU开发者,内存屏障和我有关吗?
5.从业15年的电源工程师转身后的哀叹。。。
6.想去Dialog拿2019年终奖不?

免责声明:本文系网络转载,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。