MySQL学习笔记--DQL、DML、DDL、TCL语句,约束(主键、外键)
MySQL
使用工具
- Windows自带的命令行窗口
- MySQL Front

一、MySQL常用数据类型
1. char
- 占用字节数 char(n)
- 定长字符串,存储控件大小固定
- 如:char(2)
2. varchar
- 占用字节数 varchar(n)
- 变长字符串,存储空间等于实际数据空间
- 只包含英文字符的字符串
3. int
- 占用字节数 4个字节
- 整型
- 比如自增ID和表示数量
4. bigint
- 占用字节数 8个字节
- 长整型
- 数量比较大的自增ID
float(数值型)、double(数值型)、date(日期时间,8个字节)、BLOB(二进制大对象)、CLOB(字符大对象)…
二、SQL语句分类
1. DQL语句—数据查询语言(select)
1.1 简单查询
查询单个字段
select 字段名 from 表名;
注:所有符号为英文下符合
查询多个字段
select 字段名,字段名 from 表名;
查询所有字段
select * from 表名;
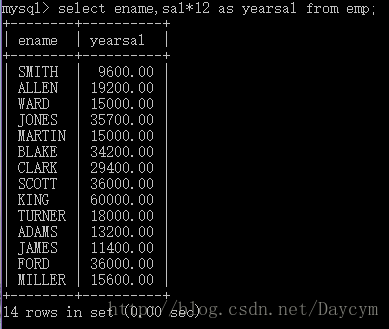
1.2 练习(计算每位员工的年薪)
select ename,sal*12 from emp;
//进一步修改一下查询年薪后的字段名
select ename,sal*12 as yearsal from emp;
1.3 条件查询
注意:条件查询需要用到where语句,where必须放到from语句表的和面;
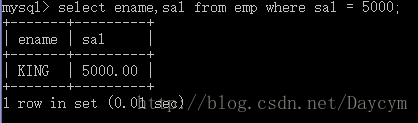
等号(=)操作符
//查询月薪等于的5000的员工
select ename,sal from emp where sal = 5000;
//查询工作为MANAGER的员工
select ename,job from emp where job = ‘MANAGER’;

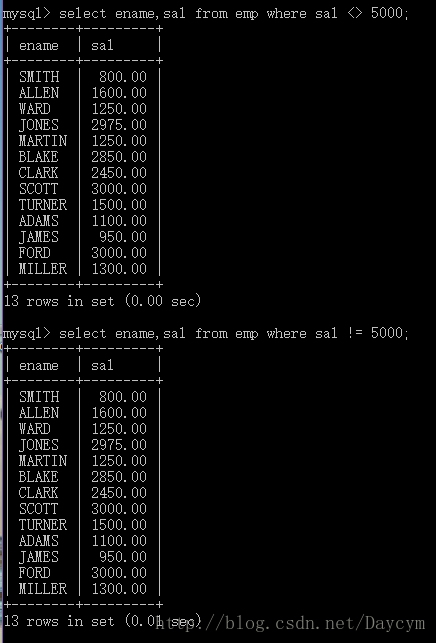
不等号(<>或!=)操作符
//查询月薪不等于5000的员工
select ename,sal from emp where sal <> 5000;
//或者
select ename,sal from emp where sal != 5000;
注:<、<=、>、>=与上面类似
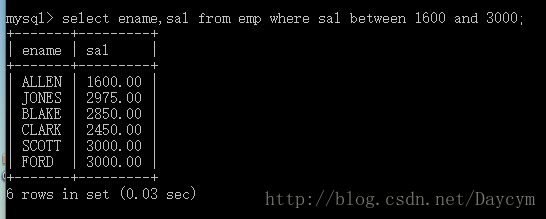
between…and…
select ename,sal from emp where sal between 1600 and 3000;
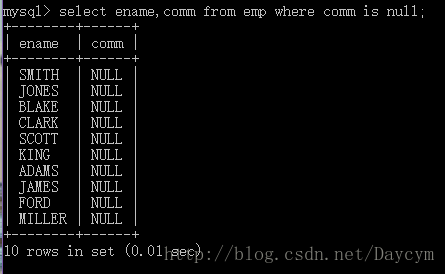
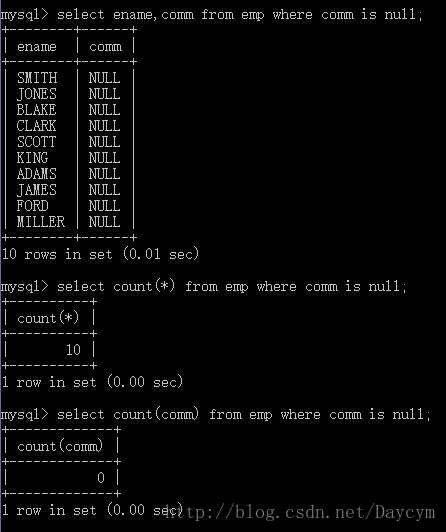
is null(is not null)
select ename,comm from emp where comm is null;
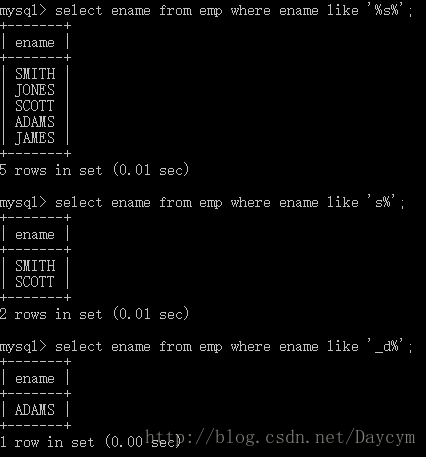
like(模糊查询)
- % 通配符
- _ 占位符
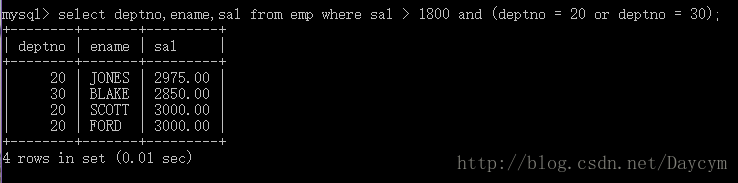
1.4 练习(查询薪水大于1800,并且部门编号为20或30的员工)
select deptno,ename,sal from emp where sal > 1800 and (deptno = 20 or deptno = 30);
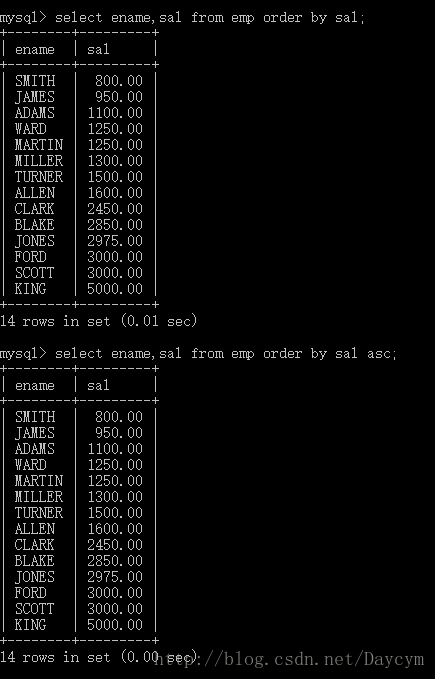
1.5 数据排序
单一字段排序order by字段名称
//按照薪水排序(默认升序)
select ename,sal from emp order by sal;
//或
select ename,sal from emp order by sal asc;
//降序
select ename,sal from emp order by sal desc;
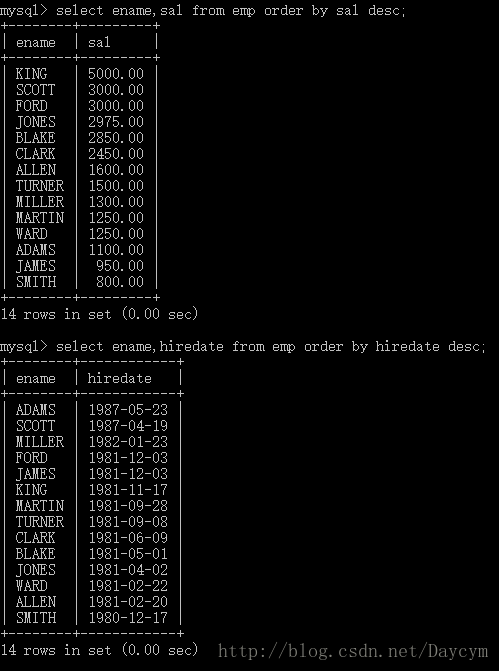
//入职日期排序
select ename,hiredate from emp order by hiredate desc;
多个字段排序
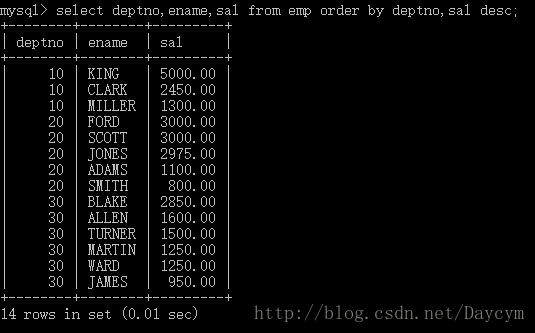
//按照部门编号升序和薪水降序排序
select deptno,ename,sal from emp order by deptno,sal desc;
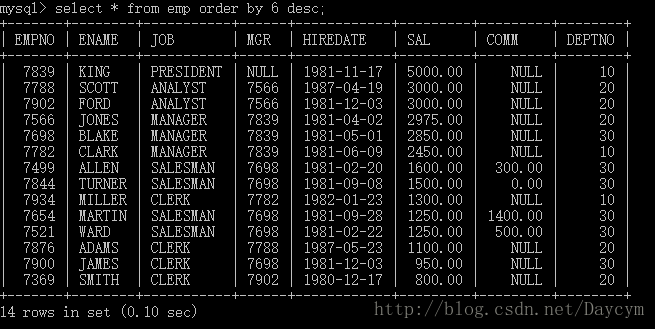
按照下标排序(可读性差)
select * from emp order by 6 desc;
1.6 数据处理函数
1) 单行处理函数
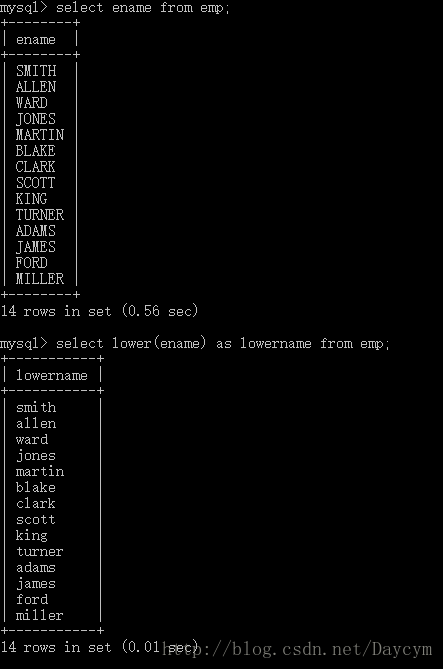
//lower 转为小写
select lower(ename) as lowername from emp;
注:转为大写类似
//substr 取子串(substr(被截取的字符串,起始下标,截取的长度)
select substr(ename,1,1) as ename from emp;
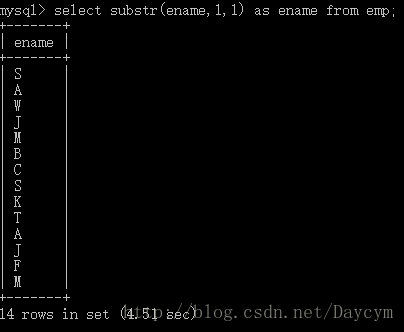
//lengh 取长度
select length(ename) as namelength from emp;
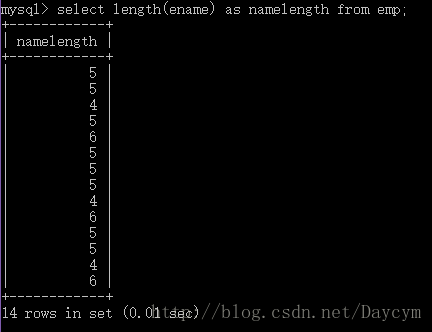
//trim 去掉空格
select * from emp where ename = trim(' king ');
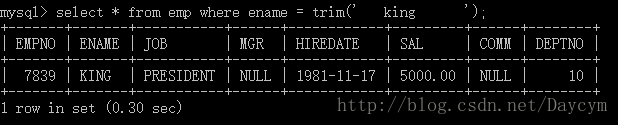
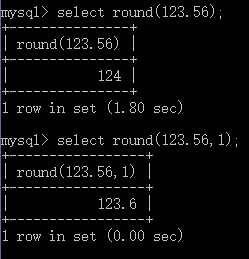
//round 四舍五入
select round(123.56);
select round(123.56,1);
//rand() 生成随机数
select rand();
select round(rand()*122);
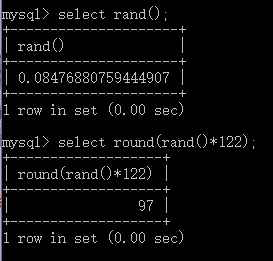
//case...when...then...else...end
//用法:匹配工作岗位,当为MANAGER时,薪水上调10%,当岗位为SALESMAN时,薪水上调20%,其他岗位薪水不变
select job,ename,
(case job
when 'MANAGER' then sal*1.1
when 'SALESMAN' then sal*1.2
else sal
end) as newsal from emp;
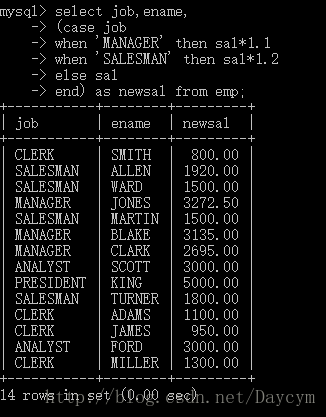
注意:所有select语句都没法修改数据的原始数据
//ifnull 空值处理函数
select ename,(sal+comm)*12 from emp;
select ename,(sal+ifnull(comm,0))*12 from emp;
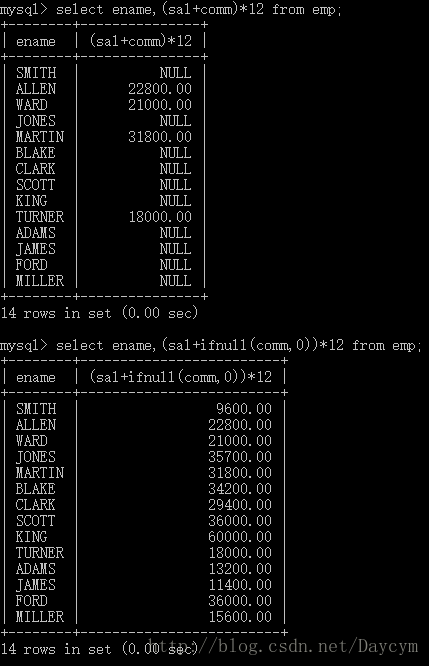
//str_to_date 把字符串转为日期
//用法:str_to_date('日期字符串','日期格式')
一般使用日期字符串来表示日期
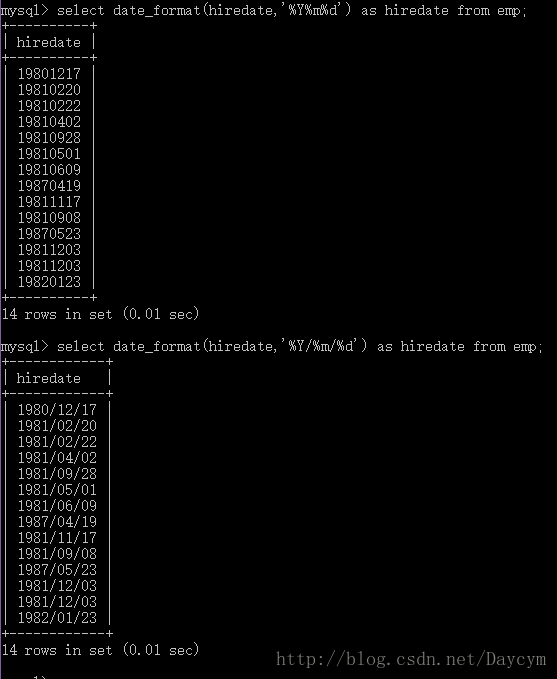
//date_format 将日期转换为特定格式的日期字符串
//用法:date_format(日期类型数据,'日期格式')
2) 多行处理函数(会自动忽略空值)
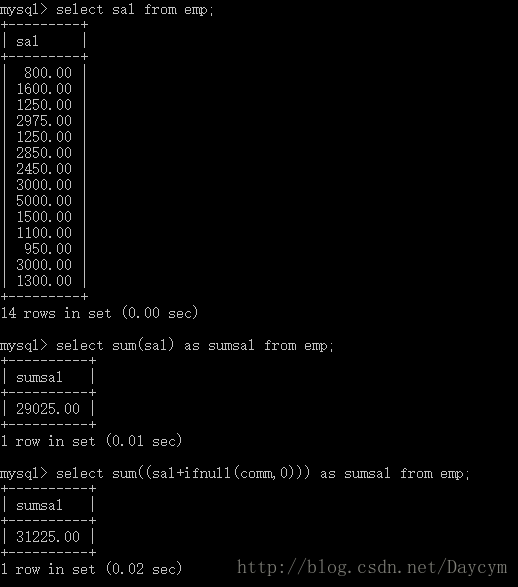
//sum 求和
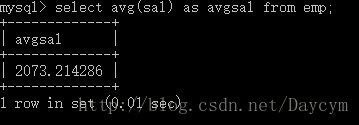
//avg 求平均值
max、min最大最小值也类似
//count 取得记录数
//多行处理函数会自动忽略空值
//distinct 去除重复记录
//用法:distinct 字段名
//或distinct 字段名1,字段名2...
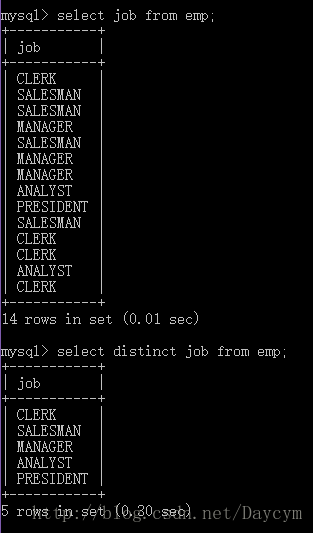
//去除部门编号和工作岗位重复的记录
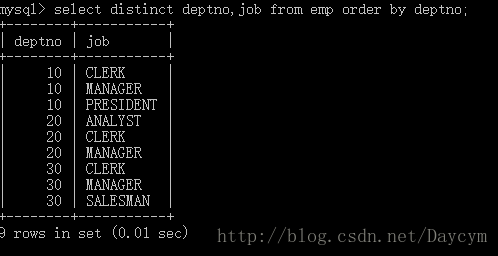
1.7 分组查询(group by)
//按工作组查询
select
job,max(sal) as maxsal
from
emp
group by
job;
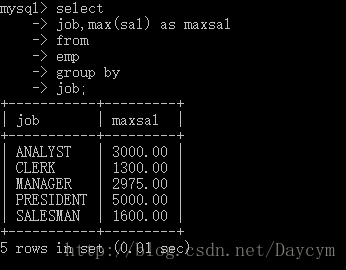
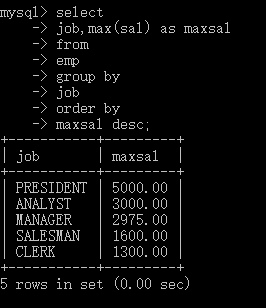
select
job,max(sal) as maxsal
from
emp
group by
job
order by
maxsal desc;
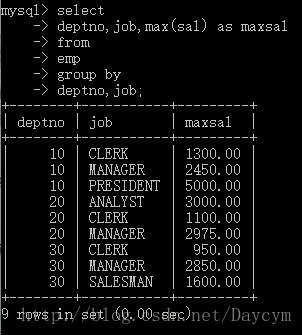
//计算不同部门不同岗位的最高薪水
select
deptno,job,max(sal) as maxsal
from
emp
group by
deptno,job;
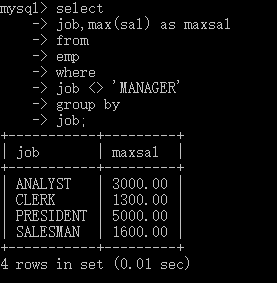
//找出每个岗位的最高薪水,除MANAGER之外
select
job,max(sal) as maxsal
from
emp
where
job <> 'MANAGER'
group by
job;
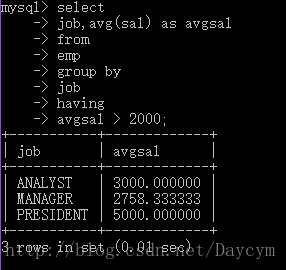
//找出每个岗位的平均薪水,要求显示平均薪水大于2000的
//having 用在group by 之后
//where用在group by 之前
select
job,avg(sal) as avgsal
from
emp
group by
job
having
avgsal > 2000;
1.8 select语句总结
一个完整的SQL语句如下:
select
xxx
from
xxx
where
xxx
group by
xxx
having
xxx
order by
xxx
- 以上关键字的顺序不能变,严格遵守
- 以上语句的执行顺序;
- 1) from 将硬盘上的表文件加载到内存
- 2) where 将符合条件的数据摘取出来。生成一张新的临时表
- 3) group by 根据列中的数据种类,将当前临时表划分为若干个新的临时表
- 4) having 可以滤掉group by 生成的不符合条件的临时表
- 5) select 对当前临时表进行整列读取
- 6) order by 对select 生成的临时表,进行重新排序,生成新的临时表
- 7) limit对最终生成的临时的数据行,进行读取
1.9 链接查询(跨表查询)
年代分类:
SQL92
select ename,dname from emp as e,dept as d where e.deptno = d.deptno;
SQL99
select
ename,dname
from
emp e
join
dept d
on
e.deptno = d.deptno
where
数据过滤条件;
连接方式分类:
内链接:省略了一个关键字:inner
等值连接
如:查询出员工所对应的部门名称
非等值连接
如:查询出员工薪水所对应的薪水等级:显示员工名称、薪水、薪水等级
自链接
如:查询出员工所对应的领导名称,显示员工名称和领导名称
1.员工所对应的领导编号
2.查询领导名称以及编号
3.表的连接条件:a.mgr = b.empno
外连接
左外连接/左连接
右外连接/右连接
全连接
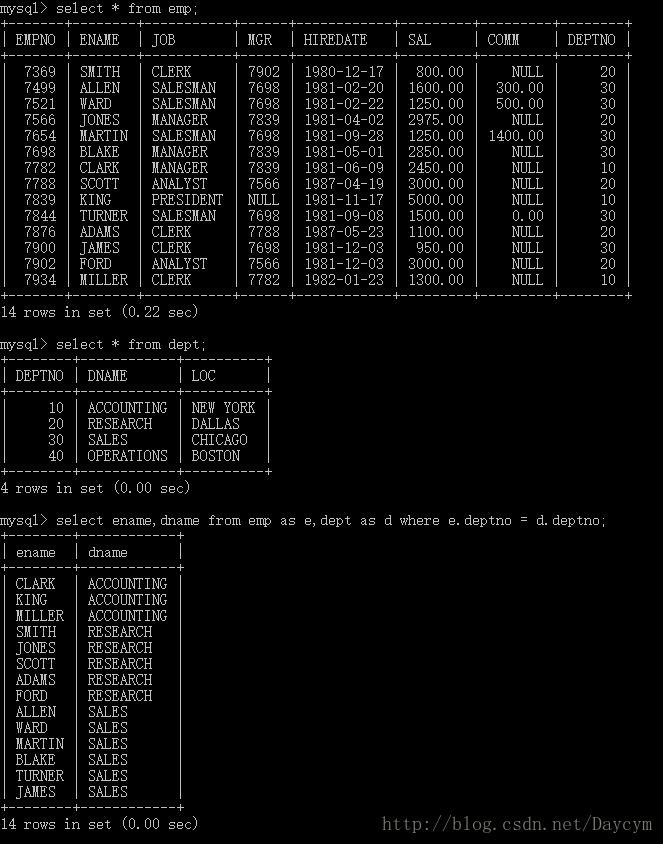
1.9.1 SQL92
select ename,dname from emp as e,dept as d where e.deptno = d.deptno;
1.9.2 SQL99(只掌握这个)
select
ename,dname
from
emp e
join
dept d
on
e.deptno = d.deptno;
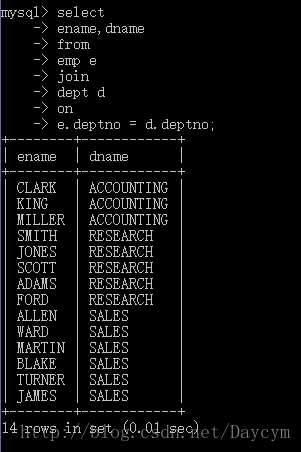
1.9.3 非等值连接
select
e.ename,e.sal,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal;
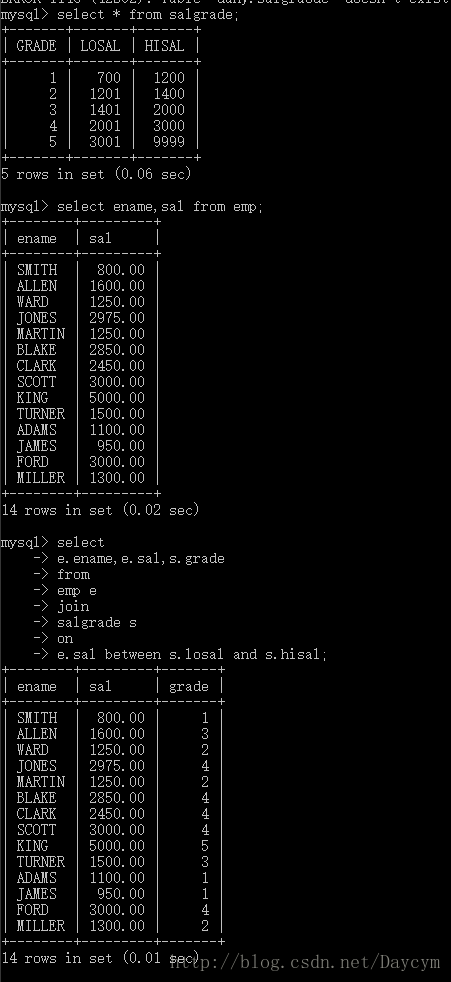
1.9.4 自链接
select
e.ename,b.ename
from
emp e
join
emp b
on
e.mgr = b.empno;
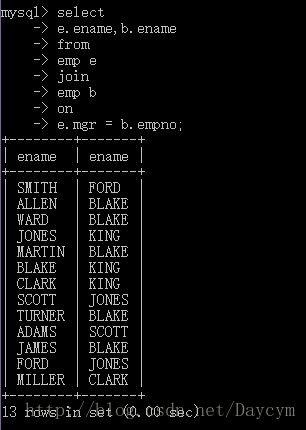
1.9.5 外连接(省略了一个关键字:outer)
定义:A表和B表能够完全匹配的记录查询出来之外,将其中一张表的记录无条件的完全查询出来,对方表没有匹配的记录时,会自动模拟出null值与子匹配
- 左外连接:包含左边表的全部行,以及右边表中全部匹配的行
- 右外连接:包含右边表的全部行,以及左边表中全部匹配的行
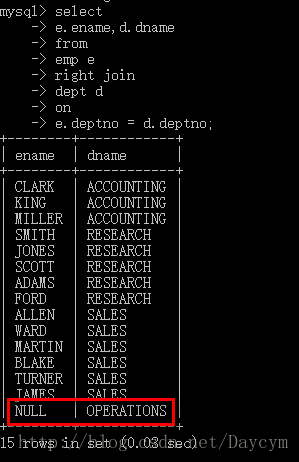
右外连接
select
e.ename,d.dname
from
emp e
right join
dept d
on
e.deptno = d.deptno;
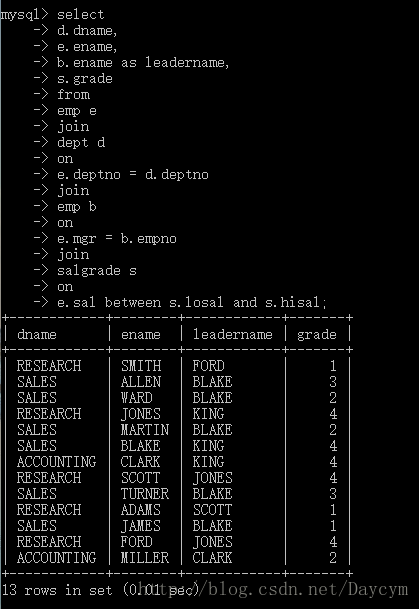
练习
查询出员工的部门名称、员工的领导名称和薪水等级
emp、dept、salgrade
select
d.dname,
e.ename,
b.ename as leadername,
s.grade
from
emp e
join
dept d
on
e.deptno = d.deptno
join
emp b
on
e.mgr = b.empno
join
salgrade s
on
e.sal between s.losal and s.hisal;
1.10 子查询
1.10.1 where之后
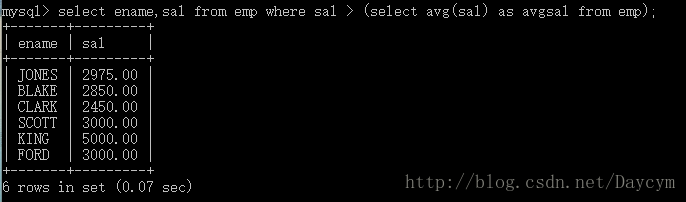
//找出薪水比公司平均薪水高的员工,要求显示员工名和薪水
select ename,sal from emp where sal > (select avg(sal) as avgsal from emp);
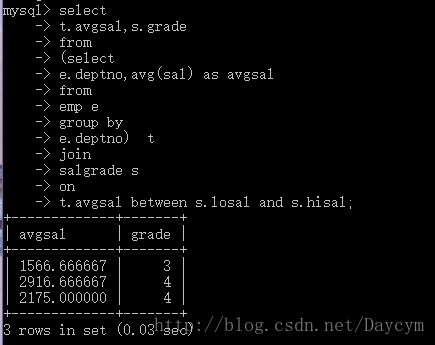
//找出每个部门的平均薪水,并且要求显示平均薪水和薪水等级
//第一步:先求出每个部门的平均薪水
select
e.deptno,avg(sal) as avrsal
from
emp e
group by
e.deptno;
//第二步:薪水等级
//连接
select
t.avgsal,s.grade
from
(select
e.deptno,avg(sal) as avgsal
from
emp e
group by
e.deptno) t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;
1.11 UNION 合并相加结果集
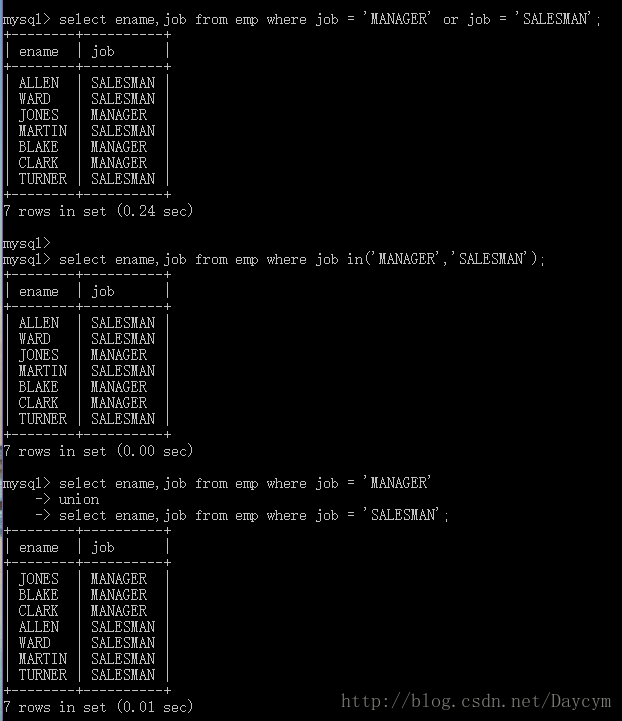
//查询出工作岗位为manager和salesman的员工
select ename,job from emp where job = 'MANAGER' or job = 'SALESMAN';
select ename,job from emp where job in('MANAGER','SALESMAN');
select ename,job from emp where job = 'MANAGER'
union
select ename,job from emp where job = 'SALESMAN';
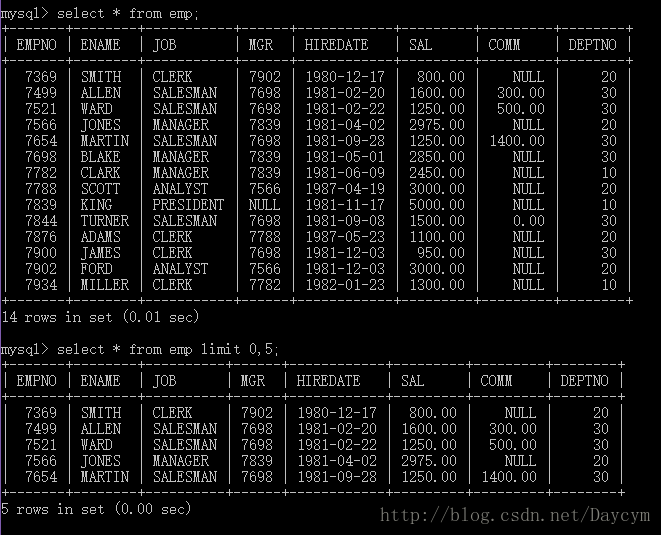
1.12 limit(只在MySQL中使用)获取一表中前几条或者中间几行数据
//取前五条数据
select * from emp limit 0,5;
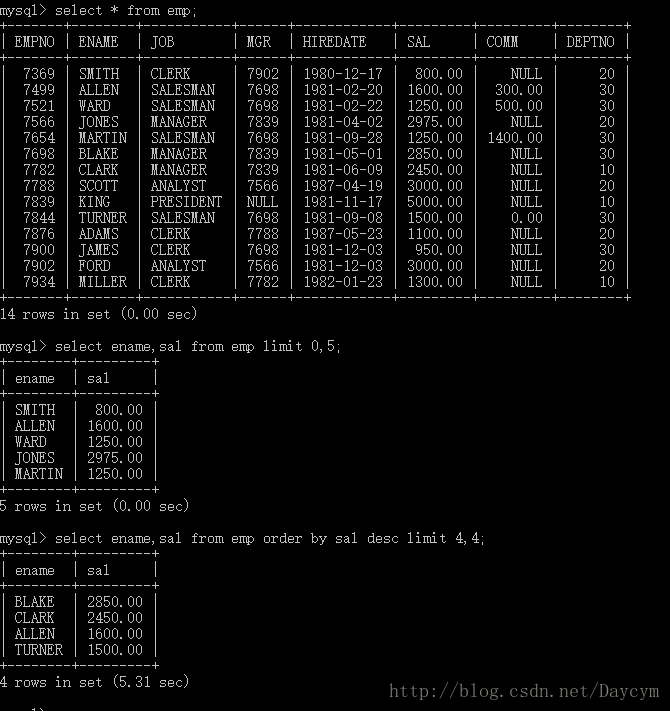
//取薪水的前五名
select ename,sal from emp order by sal desc limit 5;
//第五到第八之间
select ename,sal from emp order by sal desc limit 4,4;
2. DML语句—数据操作语言(insert、delect、update)
2.1 insert(插入)
语法: insert into 表名(字段名,字段名,字段名) values (字段值,字段值,字段值);
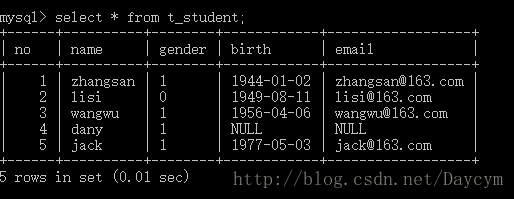
insert into t_student(no,name,gender,birth,email)
values
(1,'zhangsan','1',str_to_date('1944-01-02','%Y-%m-%d'),'[email protected]');
insert into t_student(no,name,gender,birth,email)
values
(2,'lisi','0','1949-08-11','[email protected]');
// mysql默认日期格式年月日
insert into t_student(no,name,gender,birth,email)
values
(3,'wangwu','1',str_to_date('04-06-1956','%m-%d-%Y'),'[email protected]');
insert into t_student(no,name,gender)
values
(4,'dany','1');
insert into t_student
values
(5,'jack','1','1977-05-3-23','[email protected]');//不推荐使用,如果有字段没赋值就会报错
补充:快速插入多条数据时,字段个数要一致
insert into emp_bak select * from emp where job = 'MANAGER';
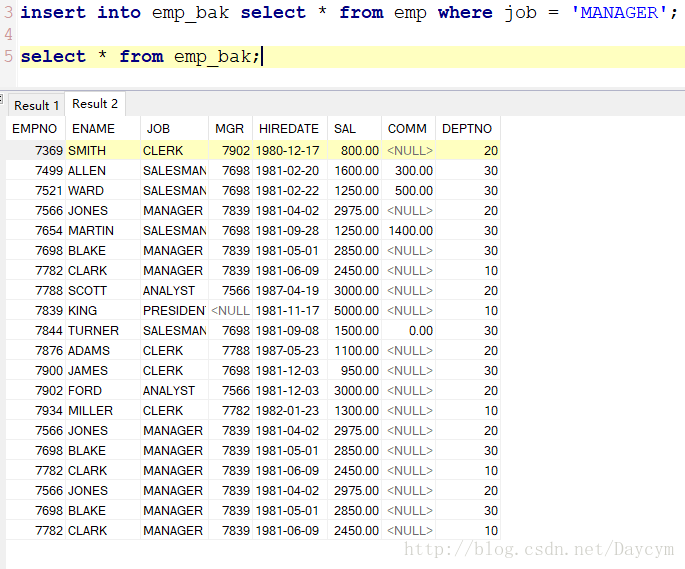
2.2 update(修改)
语法: update 表名 set 字段名称 = 字段值,字段名称 = 字段值 where 限制条件;
//单个字段
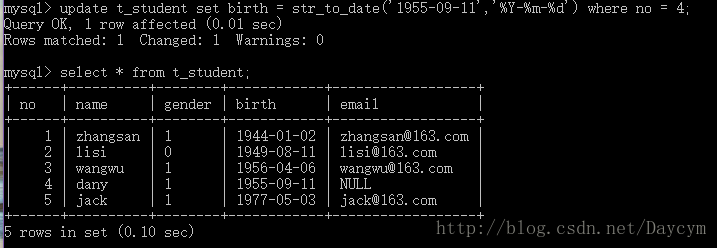
update t_student set birth = str_to_date('1955-09-11','%Y-%m-%d') where no = 4;
//多个字段
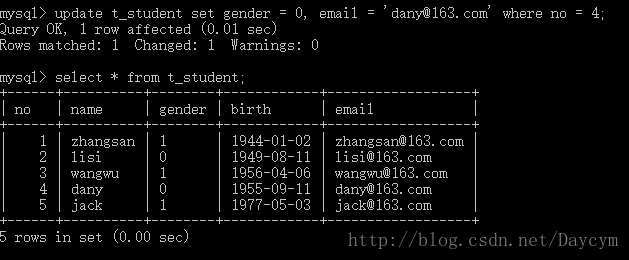
update t_student set gender = 0, email = '[email protected]' where no = 4;
2.3 delete(删除)
语法:delete xxx from 表名;
//delete from t_student; 删除所有记录
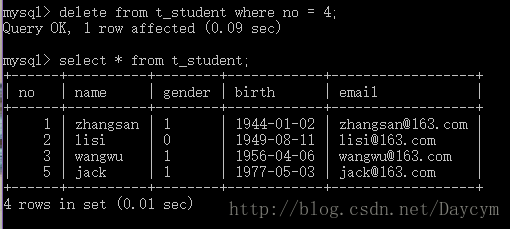
delete from t_student where no = 4;
3. DDL语句—数据库定义语言(create、drop、alter)
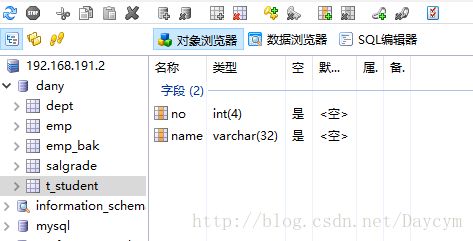
3.1 创建表格(create)
学号: no INT(4)
姓名: name varchar(32)
性别: sex char(1)
出生日期: birth date
邮箱: email varchar(128)
create table t_student(
no int(4),
name varchar(32),
gender char(1),
birth date,
email varchar(128)
);
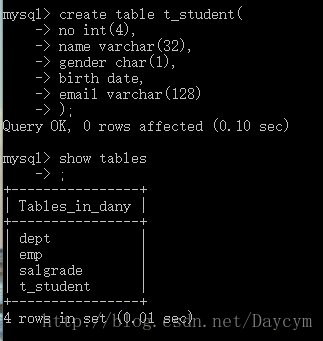
3.2 删除表格(drop)
drop table t_student;//删除不存在的表,会报错
drop table if exists t_student;//删除不存在的表,不会报错
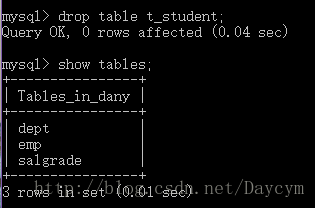
3.3 快速复制一张表(复制出来的表是新的表,和原来的表没关系)
create table emp_bak as select * from emp;
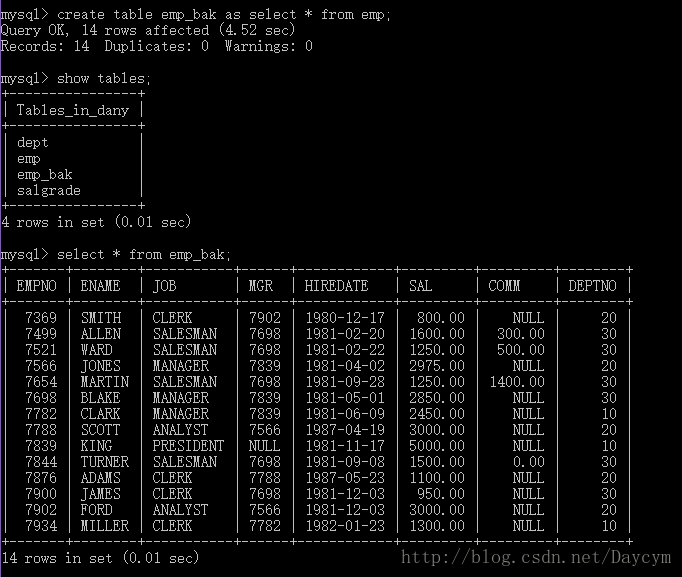
补充:default 给字段设置默认值
drop table if exists t_student;
create table t_student(
no int(4),
name varchar(32),
gender char(1) default '1',
birth date,
email varchar(128)
);
insert into t_student(no,name)
values
(4,'dany');
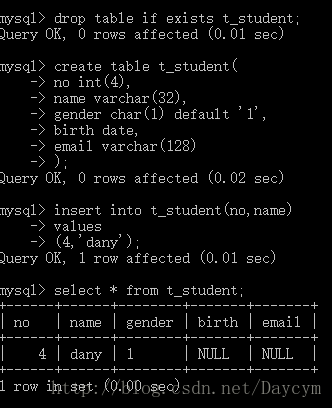
3.4 alter(修改表结构)
drop table if exists t_student;
create table t_student(
no int(4),
name varchar(32)
);
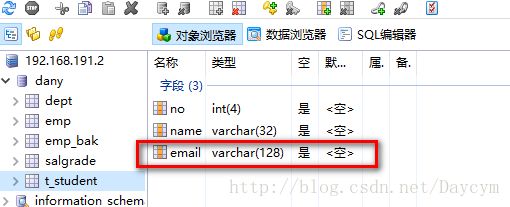
//增加字段
alter table t_student add email varchar(128);
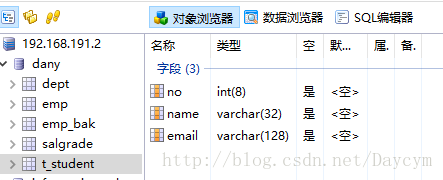
//修改字段
alter table t_student modify no int(8);
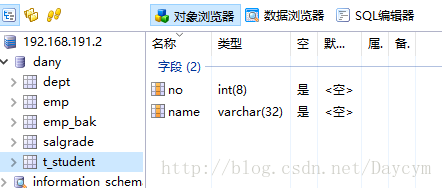
//删除字段
alter table t_student drop email;
//改变字段名
alter table t_student change name username varchar(32);
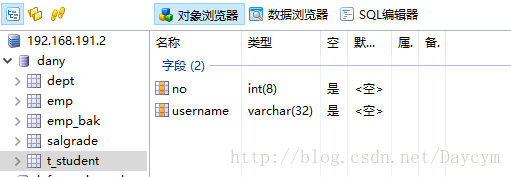
4. TCL语句—事务控制语言(commit、rollback)
4.1 事务transaction
- commit:提交,成功的结束,将所有的DML语句操作记录和底盘硬件文件中数据进行一次同步
- rollback:回滚,失败的结束,将所有DML语句操作记录全部清空。
- MySQL默认自动提交
//关闭自动提交
//方式一:手动启动事务
start transaction;
...DML语句
commit;
//方式二:设置自动提供为off
set autocommit = off;
...DML语句
commit;
4.2 事务隔离级别
查看隔离级别 select @@tx_isolation;
- isolation可选值:
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
三、创建表加入约束
1. 非空约束(not null)
作用:not null约束的字段不能为NULL值,必须赋具体数据
create table t_user(
id int(4),
name varchar(32) not null,
email varchar(128)
);
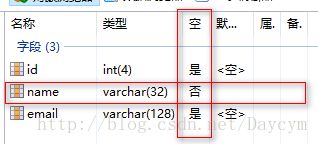
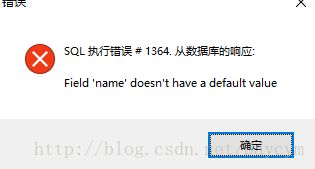
insert into t_user(id,email) values(1,'[email protected]')
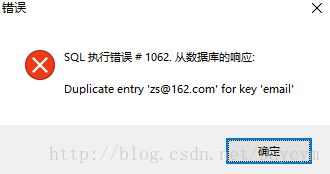
2. 唯一性约束(unique)
作用:unique约束的字段具有唯一性,不可重复
- 如:qq号,手机号等
drop table if exists t_user;
create table t_user(
id int(4),
name varchar(32) not null,
email varchar(128) unique
);
insert into t_user(id,name,email) values(1,'zs','[email protected]');
insert into t_user(id,name,email) values(1,'ls','[email protected]');
//或写为
drop table if exists t_user;
create table t_user(
id int(4),
name varchar(32) not null,
email varchar(128),
unique(email)
);
//联合唯一性
drop table if exists t_user;
create table t_user(
id int(4),
name varchar(32) not null,
email varchar(128),
unique(name,email)
);
insert into t_user(id,name,email) values(1,'ls','[email protected]');
insert into t_user(id,name,email) values(2,'ls','[email protected]');
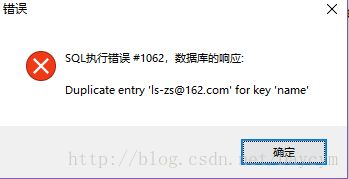
3. 主键约束PK(primary key)
主键约束、主键字段、主键值
- 添加主键的字段既不能重复也不能为空
- 添加主键约束之后,主键不仅会有”not null unique”作用,而且主键字段还会自动添加“索引——index”
drop table if exists t_user;
create table t_user(
id int(4) primary key,
name varchar(32) not null
);
insert into t_user(id,name) values(1,'lisi');
insert into t_user(id,name) values(2,'lisi');
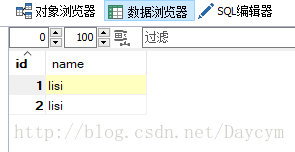
insert into t_user(id,name) values(1,'lisi');

MySQL中自动生成主键值(MySQL特有)
drop table if exists t_user;
create table t_user(
id int(4) primary key auto_increment,
name varchar(32) not null
);
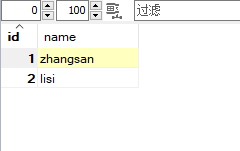
insert into t_user(name) values('zhangsan');
insert into t_user(name) values('lisi');
4. 外键约束FK (foreign key)
外键约束、外键字段、外键值
- 作用:解决数据的冗余
- 外键根据个数分为:单一外键、复合外键
- 【单一外键】:给一个字段添加外键约束
- 【复合外键】:给多个字段添加一个外键
4.1 示例1
需求:设计数据库表用来存储学生信息和班级信息
- t_student包含: sno,sname,classno,cname
drop table if exists t_student;
create table t_student(
id int(4) primary key auto_increment,
sno int(4),
sname varchar(32),
classno int(4),
cname varchar(32)
);
//将上表分为两张表
//父表
drop table if exists t_class;
create table t_class(
cno int(4) primary key,
cname varchar(32)
);
//子表
drop table if exists t_student;
create table t_student(
sno int(4) primary key auto_increment,
sname varchar(32),
classno int(4),
constraint t_student_classno_fk foreign key(classno) references t_class(cno)
);
//给班级编号加外键约束
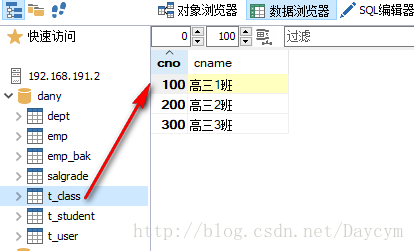
insert into t_class(cno,cname) values(100,'高三1班');
insert into t_class(cno,cname) values(200,'高三2班');
insert into t_class(cno,cname) values(300,'高三3班');
insert into t_student(sname,classno) values('张三',100);
insert into t_student(sname,classno) values('李四',100);
insert into t_student(sname,classno) values('王五',400);
//加外键约束后,会报错

注意:
- 外键字段可以为NULL,外键为空的数据也叫孤儿数据
- 被引用字段必须具有unique约束
- 有了外键引用之后,表分为父表和子表,以上附表为t_class;子表为t_student
- 创建表时先创建父表,再创建子表;插入数据时,先插入父表数据,再插入子表数据。
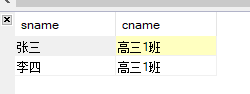
select
s.sname,c.cname
from
t_student s
join
t_class c
on
s.classno = c.cno;
5. 级联更新与级联删除(使用极少)
用法:在添加级联更新与级联删除的时候,需要在外键约束后面添加关键字;
- 注意:级联更新与级联删除谨慎使用,因为级联操作换将数据改变或删除
5.1 级联删除:on delete cascade
定义:在删除父表数据的时候,级联删除子表中数据
//修改约束条件
alter table t_student drop foreign key t_student_classno_fk;
alter table t_student add constraint t_student_classno_fk foreign key(classno)
references t_class(cno) on delete cascade;
修改后,若删除父表t_class表中的高三1班,子表t_student中高三1班的学生都会被删除。
5.2 级联更新:on update cascade
更新父表数据,子表有关联的数据也会被更新。
四、 数据库设计三范式
1. 第一范式:主键、字段不能再分
定义:要求有主键,数据库中不能出现重复记录,每一个字段是原子性不能再分。
- 结论:
- 每一行必须唯一,也就是每个表必须有主键,这是我们数据库设计的最基本要求
- 主键通常采用数值型或定长字符串表示
- 关于列不可再分,应根据具体情况具体分析
2. 第二范式:非主键字段完全依赖主键
定义:第二范式是建立在第一范式基础上,要求数据库中所有非主键字段完全依赖主键,不能产生部分依赖。
3. 第三范式
定义:建立在第二范式基础之上,要求非主键字段不能产生传递依赖于主键字段
- 如:学生编号(PK)–学生姓名–班级编号–班级名称
- 非主键字段班级名称依赖于班级编号,班级编号依赖于学生姓名,学生姓名依赖于主键学生编号,形成了传递依赖与主键字段。
4. 三范式总结(几个比较经典的设计)
示例一对一:t_ husband 和 t _wife两张表
//妻子表
create table t_wife(
wno int(4) primary key,
wname varchar(32)
);
//丈夫表
create table t_husband(
hno int(4) primary key,
hname varchar(32),
wifeno int(4) unique,
foreign key(wifeno) references t_wife(wno)
);
一对多、多对多上面有涉及