【第0章—第三章】【初识C++ Accelerated C++ 学习笔记】
第0章 入门
1、main函数
|
1
2 3 4 |
int main ()
{ return 0; } |
与C语言不一样,main函数的参数列表为空,并不需要void(加上void后,gcc也可以通过编译),返回值为整数,这个值返回给实现;0表示运行成功,其它整数表示运行有错误。如果省略return语句,系统会假定它返回了0,当然,显式地写出return语句是一个好的编程习惯。
__________________________________________________________________________________________________________________________________________________________________________________
2、使用标准库输出
|
1
|
std::cout <<
"Hello, world!" << std::endl;
|
std是一个生存空间,在使用标准库中定义的任何名字时,都应该使用std来指定。标准库的输出操作符是<<(左结合性),它的左操作数是定义在名字空间std中的标准输出流std::cout,类型是std::ostream,此类型定义在库
__________________________________________________________________________________________________________________________________________________________________________________
3、表达式与副作用
表达式的作用就是请求系统进行计算,并产生一个结果,但是往往除了产生我们想要的结果之外,还会影响程序或者系统的状态,而这些影响并不是结果的直接作用,我们称之为副作用。
__________________________________________________________________________________________________________________________________________________________________________________
4、类型
C++的类型一部分是属于语言核心的,另一部分属于标准库。位于语言核心的类型可以适用于所有C++程序,但是在使用标准库中的类型时,一定要明确包含类型所在的标准库文件。每种类型都表示一种数据结构和它适用的操作。
__________________________________________________________________________________________________________________________________________________________________________________
5、C++程序的自由风格
自由风格指的是:只有在防止相邻的符号混淆在一起的时候,才有必要使用空白符来分隔。C++中有三种实体不具有自由风格:
|
1
2 3 |
a.字符串直接量 用双引号括起来的字符,不可以跨行
b. #include name #include 和 name 必须出现在同一行( /**/注释除外) c. //注释 //只能注释一行 |
__________________________________________________________________________________________________________________________________________________________________________________
===========================================================================================================
第一章 使用字符串
1、使用标准输入
|
1
2 3 |
#include std::string name; // 声明一个std::string类型的变量 std::cin >> name; // 从标准输入读取一个字符串到name中 |
和标准输出类似,标准输入使用标准库中的>>操作符来完成,它的左操作数是istream类型的变量cin(标准输入流),操作符产生的结果也是istream类型的std::cin,因此,可以实现链式输入操作。std是它的生存空间,表示cin是定义在标准库中的。当通过标准库读取一个字符串时,它会忽略输入中所有空白符,而把其它的字符读取到name中,直到它遇到其它空白符或者文件结束标识,也就是说,实际上读取的是一个“单词”。
__________________________________________________________________________________________________________________________________________________________________________________
2、标准输出的补充
|
1
|
std::cout <<
"Hello, " << name <<
"!" << std::endl;
|
标准输出除了可以直接输出字符串直接量外,还可以输出string类型的变量。
__________________________________________________________________________________________________________________________________________________________________________________
3、std::string类型
|
1
2 3 4 5 |
#include std::string name; const std::string greeting = "Hello, " + name + "!"; const std::string spaces (greeting.size(), ' '); |
这个类型是标准库的一部分,它可以存储一个字符串,与C语言不同,C++的标准库直接提供了字符串类型。
从以上的代码片段可以看到两种定义string变量的方法:
|
1
2 3 4 5 6 |
a. 使用+将一个string变量和字符串直接量连接在一起(还可以连接两个string对象,但是不能链接两个字符串直接量),并用=“赋值”。(这里的+并不是数量值相加,而是起连接作用,
+操作符的操作数不同,其功能也会不同,也就是说,+操作符被重载了。) b. 使用构造变量的方法:通过在定义中使用圆括号,要求系统根据圆括号中的表达式来构造变量。表达式const std::string spaces (greeting.size(), ' ')中 greeting.size()是调用greeting对象的一个成员函数size,这个函数产生一个整数值,表示的是greeting对象含有字符的个数。' '是一个字符直接量,表示一个空格字符。这个表达式 的结果是构造了一个string对象spaces,并且,spaces中包含有greeting.size()个' '。如果我们定义std::string stars (10, '*'),那么我们就可以得到stars对象: ********** 。 |
小结一下std::string类型对象的操作:
|
1
2 3 4 5 6 7 8 |
(n是一个整数,c是一个字符,is是一个输入流,os是一个输出流)
std::string s; std::string t = s; std::string z (n, c); os << s; is >> s; s + t; s.size(); |
__________________________________________________________________________________________________________________________________________________________________________________
4、const
一个const变量,必须在定义的时候初始化,否则就再也没有机会给它赋值了;用来初始化const变量的值,可以不是常数(constant)。
__________________________________________________________________________________________________________________________________________________________________________________
5、缓冲
一般来说,输入输出库会把它的输出保存在叫做缓冲(buffer)的内部数据结构上,通过缓冲可以优化输出操作。不管还有多少字符等待输入,很多系统在向输出设备写入字符时需要花费大量的时间。为了避免无法及时响应每个输出请求,标准库使用缓冲来累积需要输出的字符,然后等待必要的时候,刷新缓冲来把缓冲的内容写到输出设备中。这样就可以通过一次写入完成多次输出操作。
有三种情况会促使系统刷新缓冲:
|
1
2 3 |
a. 缓冲区满了
b. 标准库被要求读取输入流 c. 显式地要求刷新缓冲区(比如使用std::endl) |
当写一个需要花费很长时间才能运行的程序时,适当的时候刷新缓冲区是一个很重要的习惯。否则,程序的输出会拥塞在系统的缓冲中,在你的程序写入后,需要很长的时间,才能看到这些输出。(这句话不理解,附上原文,并求教于各位大牛,希望您能指点一下小弟,谢谢!☺)
|
1
2 3 |
原文:Flushing output buffers at opportune moments is an important habit when you are writing programs that might take a long time to run.
Otherwise, some of the program's output might languish in the system's buffers for a long time between when your program writes it and when you see it. |
__________________________________________________________________________________________________________________________________________________________________________________
6、变量和对象
为了能够读取数据,我们必须有一个地方来存放数据。我们把这个地方叫做变量。一个变量就是一个有名字的对象(object)。对象有自己的类型,它按顺序存储在计算机内存中。对象和变量之间的区别很重要。对象可以没有名字。
下面是关于C++中变量和对象区别(改编自一名网友的博客http://blog.csdn.net/yby4769250/article/details/7377526)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
对象和变量,虽然两者都对应着一块内存,但是两者有不同的意义。
变量:所谓变量就是一种定义,通过定义,编译器将会开辟一段空间,并将这段内存空间和这个变量的名字捆绑在一起。也就是说:变量名就是内存在代码中可视化的一个符号。如int a, a只是内存中某段地址在代码中可视化的一个符号,a本身作为符号并不占用空间,占用空间的是a所对应着的那个变量,通过a这个符号我们可以引用到该变量在内存中的位置。这就好 比是人和名字的关系,人作为一个真真正正的实体,是占用地球的物理空间的,是一个真实的存在,而这个人的名字只是与这个人绑定在一起的一个符号,名字本身并没有占用地球的物理 空间,因此,我们引用这个人的名字的时候,就等于我们找到了这个人。 对象:对象就是内存中一段有类型的区域。从这句话的描述上来看,对象之于变量,似乎更关注的是这段内存的类型,而不是名字。不能说变量就是对象,或者对象就是变量。严格来说, 对象就是用来描述变量的。一点佐证是,C++中的临时变量的概念,如传参时生成的临时变量,该变量在内存中存在,但是是没有名字的,因此在代码中无法可视化,我们就无法通过名 字去引用这个临时变量。 两者的区别与联系 从上面的两个描述中我们可以看到,两者都是用来描述一段内存的,但是是从不同的角度去描述: 变量更强调的是变量名这个符号的含义,更强调名字与内存的联系,而不必关注这段内存是什么类型,有多少字节长度,只关注这个变量名a对应着某段内存。而对象的描述更强调的是内 存的类型而不在乎名字,也就是说,从对象的角度去看内存,就需要清楚这段内存的字节长度等信息,而不关注这个对象在代码中是否有一个变量名来引用到这段内存。 举例: int a; 如果我们说a是个变量,那我们关注的只是a这个名字对应着一块内存,当我们引用a时,我们能明确的知道我们引用的是a这个名字所对应的内存空间,而不是别的,也不去关注这个a 的内存是什么类型。 如果我们说a是个对象,则我们需要知道这个对象具体是什么类型,当我们引用并操作a的时候,就能根据类型信息做一些符合类型语义的操作,而不是暴力访问内存,任意解析内存中的 数据。 REFERENCE: http://blog.csdn.net/yby4769250/article/details/7377526 |
__________________________________________________________________________________________________________________________________________________________________________________
===========================================================================================================
第二章 循环和计数
1、size_type
|
1
|
const std::string::size_type cols;
|
std::string表示string名字定义在名字空间std中,后面的一个::表示size_type来自string类。类也定义了自己的生存空间。std::string类定义了size_type,用来表示一个string中含有字符的数目,string::type_size是一个无符号整数类型,可以包含任意string类型对象的长度(也就是说,无论string对象所包含的字符数量有多大,都可以使用这个类型来表示)。
当需要定义一个用来保存特定数据结构的大小的变量时,我们应该使用标准库定义的相应类型,不要使用语言核心定义的类型,即便我们知道核心类型足以容纳需要存储数据的大小。
__________________________________________________________________________________________________________________________________________________________________________________
2、using声明
|
1
|
using std::cout;
using std::cin;
|
using声明用来说明一些特殊的名字都来自于一个特定的名字空间。
使用格式:using namespace-name::name;定义name为namespace-name::name的同义词。
__________________________________________________________________________________________________________________________________________________________________________________
3、循环不变式
|
1
2 3 4 5 6 7 |
We use loop invariants to help us understand why an algorithm is correct. We must show three things about a loop invariant:
• Initialization: It is true prior to the first iteration of the loop. • Maintenance: If it is true before an iteration of the loop, it remains true before the next iteration. • Termination: When the loop terminates, the invariant gives us a useful property that helps show that the algorithm is correct. |
loop invariants 叫做循环不变式有误导,最好叫做循环不变性。
循环不变式(loop invariants)不只是一种计算机科学的思想,准确地说是一种数学思想。在数学上阐述了通过循环(迭代、递归)去计算一个累计的目标值的正确性。
如何找循环不变式?由于算法是一步步执行的,那么如果每一步(包括初试和结束)都满足一个共同的条件,那么这个条件就是要找的循环不变式。
循环不变式的思想,说明正确算法的循环过程中总是存在一个维持不变的特性,这个特性一直保持到循环结束乃至算法结束,这样就可以保证算法的正确了。比方说插入排序,算法每次循环后,前n个数一定是排好序的(n为已经循环的次数)。由于这个特性一直成立,到算法结束时,所有N个数一定是排好序的。循环不变的特性,一般都是循环结束时数据具有的特性。如何寻找循环不变量,没有一般方法,不过这是证明算法正确性的最正规的方法。
下面是一个具体的例子和分析:
在编写循环时,找到让每次循环都成立的逻辑表达式很重要。这种逻辑表达式称为循环不变式。循环不变式相当于用数学归纳法证明的“断言”。
循环不变式用于证明程序的正确性。在编写循环时,思考一下“这个循环的循环不变式是什么”就能减少错误。
代码清单1是用C语言写的sum函数,功能是求出数组元素之和。参数array[]是要求和的对象数组,size是这个数组的元素数。调用sum函数,会获得array[0]至array[size-1]的size个元素之和。
代码清单1 sum函数,求出数组的元素之和
|
1
2 3 4 5 6 7 8 9 10 |
int sum (
int array[],
int size )
{ int k = 0; int s = 0; while ( k < size ) { s = s + array[k]; k = k + 1; } return s; } |
在sum函数中使用了简单的while循环语句。我们从数学归纳法的角度来看这个循环,得出下述断言M(n)。这个断言就是循环不变式。
• 断言M(n):数组array的前n个元素之和,等于变量s的值。
我们在程序中成立的断言上标注注释,形成清单2所示代码。
代码清单2 在1的代码中成立的断言上标注注释
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int sum (
int array[],
int size )
{ int k = 0; int s = 0; /* M(0) */ while ( k < size ) { /* M(k) */ s = s + array[k]; /* M(k+1) */ k = k + 1; /* M(k) */ } /* M(size) */ return s; } |
在代码清单2的第4行,s初始化为0。由此,第5行的M(0)成立。M(0)即为“数组array的前0个元素之和等于变量s的值”。这相当于数学归纳法的步骤1。
图1 数学归纳法的步骤1(M(0)成立)

第7行中,M(k)成立。然后进行第8行的处理, 将数组array[k]的值加入s, 因此M(k+1)成立。这相当于数学归纳法的步骤2。
图2数学归纳法的步骤2(M(k) M(k+1)成立)
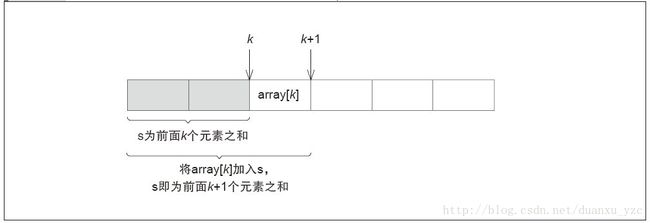
请一定要理解第8行,
s=s+array[k];
意为“在M(k)成立的前提下,M(k+1)成立”。
第10行中k递增1,所以第11行的M(k)成立。这里是为了下一步处理而设定变量k的值。
最后,第13行的M(size)成立。因为while语句中的k递增了1,而这时一直满足M(k), 走到第13行时k和size的值相等。M(size)成立说明sum函数是没有问题的。因此,第14行return返回结果。
图3 M (size)成立

综上所述,这个循环在k从0增加到size的过程中一直保持循环不变式M(k)成立。编写循环时,有两个注意点:一个是“达到目的”,还有一个是“适时结束循环”。循环不变式M(k)就是为了确保“达到目的”。而k 从0 到size 递增确保了“适时结束循环”。
代码清单3中,写明了M(k)成立的同时k递增的情形。(^表示“并且”)
代码清单3 M (k成立的同时k递增)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int sum (
int array[],
int size )
{ int k = 0; int s = 0; /* M(k) ^ k == 0 */ while ( k < size ) { /* M(k) ^ k < size */ s = s + array[k]; /* M(k+1) ^ k < size */ k = k + 1; /* M(k) ^ k <= size */ } /* M(size) ^ k == size */ return s; } |
以上循环不变式M(k)在每次循环时都成立
REFERENCE:
http://herculeser.blog.51cto.com/3272654/1159486
http://www.cnblogs.com/bamboo-talking/archive/2011/02/05/1950197.html
http://zhidao.baidu.com/question/558630518.html
http://blog.csdn.net/davelv/article/details/5952981
http://www.ituring.com.cn/article/20305
__________________________________________________________________________________________________________________________________________________________________________________
4、从0开始计数
|
1
2 3 4 5 6 7 8 9 |
// 1 for ( int r = 0; r != rows; ++r ){ // do smoething same } // 2 for ( int r = 1; r <= rows; ++r ){ // do something same } |
程序设计中,尤其在循环计数和数组中,我们一般采用从0开始的计数方案,而不是从1开始,原因有如下三点:
a. 可以使用不对称区间来表示间隔
在上面的两个程序片段中,区间[0,rows)和[1,rows]表示的循环次数是相同的,但是前者更容易知道次数为rows-0或者直接为rows,而后者的表达为rows-1+1,很显然采用不对称区间更易于观察循环进行的次数(或者数组的元素个数)。
b. 更容易表达循环不变式
第一个循环中,循环不变式很容易写出:到目前为止,我们已经执行了r次。第二个循环中循环不变式则要表达为:到目前为止,已经执行了r-1次。显然直接使用变量r更为直接。
c. 更容易判断循环结束时程序的状态。
第一个循环中,当结束时我们很清楚地知道,此时r==rows,而在第二个循环中,结束时只能知道r>rows。显然第一种方法使循环结束时程序的状态更精确。
__________________________________________________________________________________________________________________________________________________________________________________
5、操作符的优先级和结合性
(REFERENCE: http://msdn.microsoft.com/en-us/library/aa245313(v=vs.60).aspx)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
//C++ Operators // Operators specify an evaluation to be performed on one of the following: // One operand (unary operator) // Two operands (binary operator) // Three operands (ternary operator) // The C++ language includes all C operators and adds several new operators. // Table 1.1 lists the operators available in Microsoft C++. // Operators follow a strict precedence which defines the evaluation order of //expressions containing these operators. Operators associate with either the //expression on their left or the expression on their right; this is called //“associativity.” Operators in the same group have equal precedence and are //evaluated left to right in an expression unless explicitly forced by a pair of //parentheses, ( ). // Table 1.1 shows the precedence and associativity of C++ operators // (from highest to lowest precedence). // //Table 1.1 C++ Operator Precedence and Associativity // The highest precedence level is at the top of the table. //+------------------+-----------------------------------------+---------------+ //| Operator | Name or Meaning | Associativity | //+------------------+-----------------------------------------+---------------+ //| :: | Scope resolution | None | //| :: | Global | None | //| [ ] | Array subscript | Left to right | //| ( ) | Function call | Left to right | //| ( ) | Conversion | None | //| . | Member selection (object) | Left to right | //| -> | Member selection (pointer) | Left to right | //| ++ | Postfix increment | None | //| -- | Postfix decrement | None | //| new | Allocate object | None | //| delete | Deallocate object | None | //| delete[ ] | Deallocate object | None | //| ++ | Prefix increment | None | //| -- | Prefix decrement | None | //| * | Dereference | None | //| & | Address-of | None | //| + | Unary plus | None | //| - | Arithmetic negation (unary) | None | //| ! | Logical NOT | None | //| ~ | Bitwise complement | None | //| sizeof | Size of object | None | //| sizeof ( ) | Size of type | None | //| typeid( ) | type name | None | //| (type) | Type cast (conversion) | Right to left | //| const_cast | Type cast (conversion) | None | //| dynamic_cast | Type cast (conversion) | None | //| reinterpret_cast | Type cast (conversion) | None | //| static_cast | Type cast (conversion) | None | //| .* | Apply pointer to class member (objects) | Left to right | //| ->* | Dereference pointer to class member | Left to right | //| * | Multiplication | Left to right | //| / | Division | Left to right | //| % | Remainder (modulus) | Left to right | //| + | Addition | Left to right | //| - | Subtraction | Left to right | //| << | Left shift | Left to right | //| >> | Right shift | Left to right | //| < | Less than | Left to right | //| > | Greater than | Left to right | //| <= | Less than or equal to | Left to right | //| >= | Greater than or equal to | Left to right | //| == | Equality | Left to right | //| != | Inequality | Left to right | //| & | Bitwise AND | Left to right | //| ^ | Bitwise exclusive OR | Left to right | //| | | Bitwise OR | Left to right | //| && | Logical AND | Left to right | //| || | Logical OR | Left to right | //| e1?e2:e3 | Conditional | Right to left | //| = | Assignment | Right to left | //| *= | Multiplication assignment | Right to left | //| /= | Division assignment | Right to left | //| %= | Modulus assignment | Right to left | //| += | Addition assignment | Right to left | //| -= | Subtraction assignment | Right to left | //| <<= | Left-shift assignment | Right to left | //| >>= | Right-shift assignment | Right to left | //| &= | Bitwise AND assignment | Right to left | //| |= | Bitwise inclusive OR assignment | Right to left | //| ^= | Bitwise exclusive OR assignment | Right to left | //| , | Comma | Left to right | //+------------------+-----------------------------------------+---------------+ |
__________________________________________________________________________________________________________________________________________________________________________________
===========================================================================================================
第三章 使用批量数据
1、vector 容器
|
1
2 3 4 5 6 7 8 9 10 |
#include using std::vector; vector< double> d; double x = 10. 1; d.push_back(x); typedef vector< double>::size_type vec_sz; vec_sz size = d.size(); |
a. vector类似于数组,用于存放相同类型数据集合,但是vector可以根据需要自动增长,并且可以高效地取得某个单独元素。
b. vector类型的定义使用了C++的一个语言特性——模板类(template classes)比如:vector
c. push_back()是vector对象的一个成员函数,这个函数把它的参数添加到vector对象的尾部,同时,使vector的大小增加1。
d. 和string对象类似,vector对象也定义了一个size_type类型,是一个无符号类型,无论vector中的元素有多少个,其个数均可存放到size_type类型的变量中。使用标准库定义的size_type来表示容器大小是一个良好的编程习惯。vector的成员函数size()返回一个size_type类型的值,表示vector中元素的个数。
__________________________________________________________________________________________________________________________________________________________________________________
2、库函数
|
1
2 3 4 5 6 7 |
#include #include using std::sort; using std::vector; vector< double> d; sort ( d.begin(), d.end() ); |
sort函数定义在头文件
__________________________________________________________________________________________________________________________________________________________________________________
3、标准库的性能
我们完全不用怀疑C++标准库的性能,其实,标准库在设计上,对性能的要求达到了残酷的程度。每个C++系统标准规范必须:
a. 实现vector,使得给一个vector追加大量元素的性能,不会比事先为这些元素分配好空间的性能差(往vector后添加大量元素时,其性能不会随着元素个数的增加而成比例地恶化);
b. 实现排序算法,使得时间复杂度低于nlog(n),其中n是要排序的元素个数。
__________________________________________________________________________________________________________________________________________________________________________________
4、初始化
对于未初始化的内置类型的局部变量,其初始值是随机的废弃值(也就是没有隐式的默认初始化);而对于类对象,类自己会说明如果没有指定初始化值时该如何初始化。
__________________________________________________________________________________________________________________________________________________________________________________
5、精度控制
|
1
2 3 4 5 6 7 8 9 |
#include #include #include using std::streansize; using std::setprecision; streamsize prec = cout.precision(); cout << "The answer is " << setprecision( 3) << 1. 235 << setprecison(prec) << endl; |
streamsize是定义于头文件
在上面的程序片段中,streamsize prec =cout.precision();用prec记录cout的原本输出精度,setprecision(3)表示将之后的输出精度设置为3位有效数字,它直接作为<<操作符的右操作数,在输出1.235之后,使用setprecison(prec) 恢复输出精度。
precision()为流的一个成员函数,如果此函数不带参数,表示的是流的精度,如果带一个整数参数,则返回流的当前精度,并设置之后的精度为参数的值。使用这个特性,上面的程序片段还可以编写为:
|
1
2 3 |
streamsize prec = cout.precision(
3);
cout << "The answer is " << 1. 235 << endl; cout.precision(prec); |
当然使用setprecision控制符更好,可以简化程序中设定特殊精度的部分(??啥意思??)。
为了避免程序的后续扩展出现错误,我们在上面的两个程序片段的末尾都将输出精度恢复到初始值。
__________________________________________________________________________________________________________________________________________________________________________________
===========================================================================================================