Linux防火墙iptables学习笔记
-
iptables 的发展
Linux 的中的防火墙就是那么一组软件对数据包的处理,Linux 中的防火墙主要是进行一些包的过滤,而这套防火墙是这样的一个发展过程:
- Linux内核2.0: ipfwadm
- Linux内核2.2: ipchains
- Linux内核2.4: iptables
iptables 之所以能够替代 ipchains 是因为它具有以下一些优势:
- 可以追踪有状态的 IPV4 的协议与应用
- 可以追踪有状态的 IPV6 的协议
- 能够做到 NAT 的 一对多与多对多
- 内建的 PORTFW 功能
iptables 就是目前工作于较新版(内核版本高过2.4的) Linux 内核中的强大的数据包过滤的软件,它主要是由两部分组成
- iptables:主要工作于用户空间,为用户提供了一个编辑规则的接口。
- netfilter:主要工作于内核空间,是内核的一部分,由一些过滤表组成。
netfilter 工作于系统的内核空间,最底层的工作,所以真正令过滤规则生效的并不是 iptables 而是 netfilter,而 iptables 工作在 netfilter之上,是一个让用户编写规则的工具。
netfilter 是 Linux 内核中的一个框架,因 Linux 拥有高模块化的内核。iptables 这个应用层的程序便是调用它的接口实现规则的修改。
-
iptables 的结构
Netfilter 所设置的规则是存放在内存中的,而 iptables 通过 Netfilter 放出的内核接口 ip_tables 来对Netfilter 配置表进行修改。这个配置表主要由 tables、chains、target 组成。
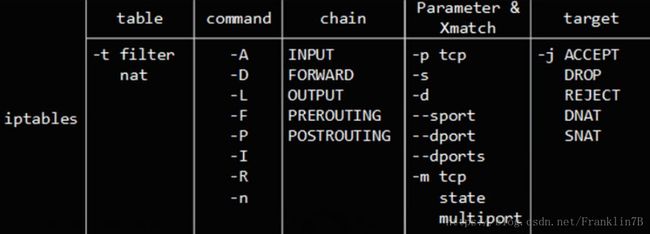
其中表主要有这四张:
- filter表
- NAT表
- mangle表
- raw表
每个表中可以用的 链(chains) 不全相同,当然 iptables 支持新建 链,而 链 是 Netfilter 框架中制定的对数据包的流向更改规则。它是防火墙中的“关卡”,所有进出的报文都要经过这些关卡,满足条件的放行,符合阻拦条件的则拒绝。也可称为hook point。系统有5种hook point:
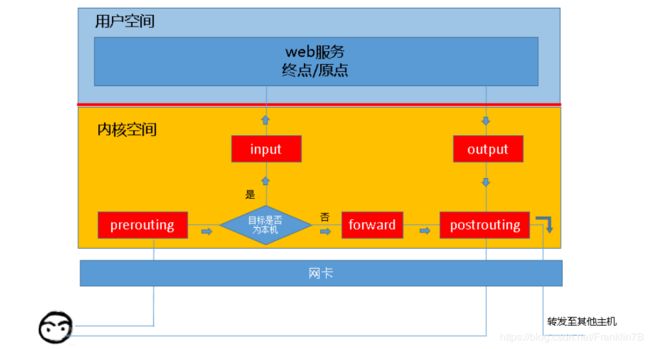
- PREROUTING(路由前)
- INPUT(目的地是本机,从外地进入本地的包)
- OUTPUT(源地址是本机,从本机进程发出的包)
- FORWARD(转发)
- POSTROUTING(路由后)
根据实际情况的不同,报文经过的链可能不同,如果报文只是经过本机,本机只负责转发,则报文不会经过input链,而是经过forward和postrouting链。
target 中大部分是通用的,当然有部分是特定使用的,这里只列举常用的几种规则,更多的规则大家可以使用 man 来查看
- ACCEPT:一旦包满足了指定的匹配条件,就会通过,并且不会再去匹配当前链中的其他规则或同一个表内的其他规则,但它还要通过其他表中的链
- DROP:一旦包满足了指定的匹配条件,将会把该包丢弃,也就是说包的生命到此结束,不会再向前走一步,效果就是包被阻塞了。不会返回任何的消息
- REJECT和DROP基本一样,一旦包满足了指定的匹配条件,将会把该包丢弃,但是它除了阻塞包之外,还向发送者返回错误信息。
- SNAT:一旦包满足了指定的匹配条件,源网络地址转换
- DNAT:一旦包满足了指定的匹配条件,目的网络地址转换
- MASQUERADE和SNAT的作用相同,区别在于它不需要指定–to-source
- REDIRECT:一旦包满足了指定的匹配条件,转发数据包一另一个端口
- RETURN:一旦包满足了指定的匹配条件,使数据包返回上一层
- MIRROR:颠倒IP头部中的源目地址,然后再转发包
-
filter表的认识
其中 filter 表的主要作用就是对数据包的过滤,访问控制(相类似的有思科自己开发的 ACL)。该表下有三个规则链:
- INPUT 链:INPUT 针对那些从外进入本地,也就是目的地是本地的包
- FORWARD 链:FORWARD 针对所有不是本地产生的并且目的地不是本地(即本机只是负责转发)的包
- OUTPUT 链:OUTPUT 是用来针对所有本地生成的包
-
NAT表的认识
NAT 是一种把内部网络的 ip 地址转换为合法的公网 ip 地址,当私有网主机和公共网主机通信的IP包经过NAT网关时,将 IP 包中的源IP或目的 IP 在私有 IP 和 NAT 的公共 IP 之间进行转换。能够有效的解决公网地址不足的问题,在一定程度上起到安全的作用
其中 NAT(Network Address Translation) 表主要用于修改数据包的报头的 IP 地址、端口号等信息。可以实现数据包伪装、平衡负载、端口转发和透明代理。该表包含三个链:
- PREROUTING 链:作用是在包刚刚到达本机时,路由之前改变它的目的地址
- OUTPUT 链:改变本地产生的包的目的地址
- POSTROUTING 链:在包就要离开防火墙之前改变其源地址
NAT 分为三种类型
- 静态 NAT(static NAT):ip 地址在转换时是一种一对一的关系
- 动态 NAT(dynamic NAT 或者叫 pooled NAT): ip 地址在转换时是一种多对多的关系
- NPAT(Network Address Port Translation):网络地址端口转换在 ip 地址的层面上来说是属于一种多对一的关系
NPAT是把内部地址映射到外部网络的一个IP地址的不同端口上,但是这里虽然是将多个内网 ip 地址转换为一个公网地址,但是这里的地址是公网地址+端口号的形式,而不是简单的一个公网地址。
在 iptables 中我们比较常用 NPAT 的形式,而 NPAT 又细分为以下的两种:
- 源 NAT(SNAT,Source NAT)修改数据包的源地址。源NAT改变数据流的第一个数据包的来源地址,数据包伪装就是一具SNAT的例子。
- 目的 NAT(DNAT,Destination NAT)修改数据包的目的地址。它是改变第一个数据包的目的地地址,如平衡负载、端口转发和透明代理就是属于 DNAT。
-
mangle 表的认识
其中 mangle 表主要用于修改数据包的 TOS(Type Of Service,服务类型,根据不同的服务质量。来选择经过路由的路径)、TTL(Time To Live,生存周期,每经过一个路由器将减1,mangle 可以修改此值设定TTL要被增加的值,这个选项可以使我们的防火墙更加隐蔽,而不被 trace-routes 发现等等)以及为数据包设置 Mark 标记(特殊标记,用来做高级路由,以使不同的包能使用不同的队列要求,等等),Qos(Quality Of Service,服务质量)调整以及策略路由等应用,由于 TOS,Qos 类似的方式需要相应的路由设备支持,所以应用并不广泛。这里不做过多的讲解,这个表中包含五个规则链:PREROUTING,POSTROUTING,INPUT,OUTPUT,FORWARD。
-
raw 表的认识
raw 表是自1.2.9以后版本的 iptables 新增的表,主要用于决定数据包是否被状态跟踪机制处理。在匹配数据包时,raw 表的规则要优先于其他表。包含两条规则链:OUTPUT、PREROUTING
-
数据包的状态
iptables中数据包被跟踪连接有4种不同状态:
- NEW:该包想要开始一个连接(重新连接或将连接重定向)
- RELATED:该包是属于某个已经建立的连接所建立的新连接。例如:--icmp-type 0 ( ping 应答) 就是--icmp-type 8 (ping 请求)所RELATED出来的。
- ESTABLISHED :只要发送并接到应答,一个数据连接从NEW变为 ESTABLISHED ,而且该状态会继续匹配这个连接的后续数据包。
- INVALID:数据包不能被识别属于哪个连接或没有任何状态比如内存溢出,收到不知属于哪个连接的 ICMP 错误信息,一般应该 DROP 这个状态的任何数据。
我们对每一张表以及每一个链都有了一个大体上的认识,我们可以通过这样一张表了解到我们的数据包在我们的内核中是怎样的一个前进的流程,到底要经过多少次审核,多少个关卡
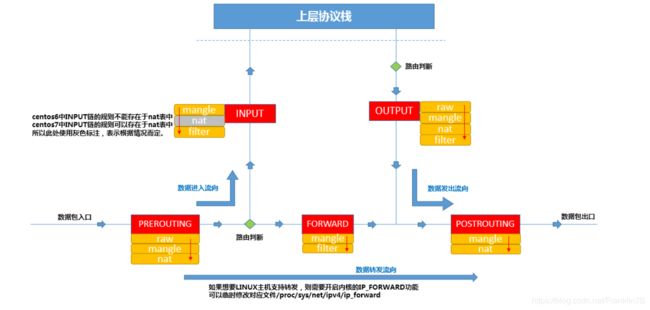
从这张图中我们可以了解到每个数据包的进与出都会经历这样的一个流程
- 当有数据包进入网卡时,数据包首先到 PREROUTING 链中,若是有表对应的表匹配,首先应该是到 raw 中,然后到 mangle 中最后到 NAT 的 PREROUTING 链中,上文我们也提过PREROUTING 链中我们有机会在到内核的路由模块之前修改数据包的目的 IP ,然后内核的"路由模块"根据数据包目的 IP 以及内核中的路由表判断往哪里转发(注意,这个时候数据包的目的地址有可能已经被我们修改过了)
- 若是该数据包的目的地址就是本机的地址,也就是该数据包就是发送给本地的,那么就会进入 INPUT 链,而进入 INPUT 链首先到 mangle 表中看看,然后到 filter 表中看看。通过之后便会发给本地的相应的程序
- 本地相应的程序若是做出响应,产生新的数据包往外发送,数据包将进入到 OUTPUT 链,而在 OUTPUT 链中与 INPUT 链匹配表的顺序相同,依旧是首先查看 raw 表,然后查看 mangle 表,查看 NAT表 ,最后查看 filter 表,若是该数据包还能继续前进将会被发送到 POSTROUTING 链中。
- 若是之前该数据包的目的地址并不是本机,只是把这里当中转站的话,就会将该数据包发给 FORWARD 链,在 FORWARD 链中,依旧先查看 mangle 表,然后查看 filter 表,若是该包还能进去前进则将进入 POSTROUTING 链中
- 在 POSTROUTING 链中首先查看 mangle 表,然后查看 NAT 表,因为他们可以在最后发送出去之前修改数据包中的源地址。
- 通过这些的层层把关,最后数据包便可以从网卡发送出去了
从数据包在内核中的走向我们可以得出以下几点,也是我们需要着重注意的几点:
- iptables 中匹配规则的表示有顺序的,我们可以得出优先级的顺序是 raw 表> mangle 表> NAT 表> filter 表
- iptables 中的表里面的链的规则也是有匹配顺序的,优先级的顺序是 PREROUTING > INPUT FORWARD OUTPUT POSTROUTING
在修改规则的时候我们会用到各种参数,下面列出一些常用的参数:
| 参数 | 解释 |
|---|---|
| -t | 制定我们修改或者添加的规则是放入那个表,若是没有指定默认为 filter 表 |
| -A | 表示我们添加的这个规则追加在表的最后面,append |
| -I | 表示我们指定位置插入当前的这个规则,insert,指定的位置写在链后面 ,若是没有指定则默认值为1,也就是将该规则添加在指定表的指定链的第一位 |
| -D | 删除某条规则,delete,后面可以指明具体的规则,如上面的例子,也可以指定位置,位置同样是放在链的后面 |
| -F | 清除所有的规则,若是后面有跟上链,便只删除该链下的所有规则 |
| -L | 显示规则链中已有的条目 |
| -N | 创建新的用户自定义规则链 |
| -p | 指定要匹配的数据包协议类型,如上文我们使用的tcp |
| -s | 指定要匹配的数据包源ip地址 |
| -i<网络接口> | 指定数据包进入本机的网络接口 |
| -o<网络接口> | 指定数据包要离开本机所使用的网络接口 |
| -j<目标> | 指定要跳转的目标; |