Linux IO 学习笔记(一)——文件系统架构
LInux任督二脉IO课程笔记,微信公众号:Linuxer。
VFS的磁盘文件系统的联系
Linux里面一切皆文件,相当于C++中的抽象基类,VFS给进程提供了一个统一的视图,让开发者不用关心每种文件系统的差别。VFS为每个文件分配一个file结构体,里面都要有一个struct file_operations类型的成员f_op,这个成员在open()文件的时候被特定文件系统赋值,最终实际操作文件的都是通过具体设备或具体文件系统的f_op来完成的(写过字符驱动的都知道,写字符驱动就是实现它的f_op)。
对于块设备,可以通过直接访问分区,也可以通过访问文件的方式来访问块设备。前者即直接通过裸设备访问块设备实际就是通过fs/block_dev.c的文件里的操作def_blk_fops,后者则是通过ext3/ext4等文件系统的f_op。(后面的裸块设备的address_space的操作为def_blk_aops,也在fs/block_dev.c中定义。address_space的含义后面会讲到。)
所以file结构中的f_op是将各种类型的文件系统的操作hook到VFS里面的,使VFS中有一个统一的视图。
那么,文件的f_op是怎么去操作特定的设备的,设备上的文件和目录又是怎么组织的呢?
我们先说第二个问题:
磁盘文件系统的组织方式
将磁盘某个分区格式化成某个文件系统(例如使用mkfs.ext4)后,这个分区的layout长这样:
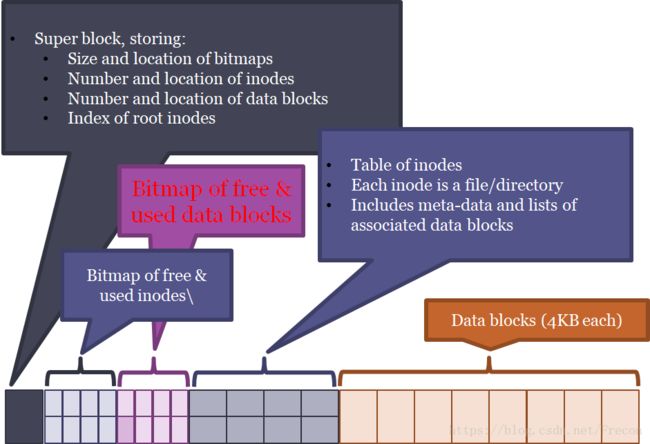
可以看到磁盘上除了文件数据(data),还有一些用于管理和描述文件属性的元数据(metadata)。
superblock:记录了文件系统全局的信息,如每个block大小、block总数、inode大小、inode总数、free的inode和block数等顶层信息。
inode:磁盘上每个文件都有一个inode与之对应,inode是文件的唯一标识。磁盘中superblock后面会维护一个inode bitmap,描述哪些inode被占用了,inode位图之后还有一个block bitmap,描述磁盘中每块区域是否已经被使用了(例如inode的数据,元数据本身也会占block)。也就是说,inode位图和block位图会限制文件系统可创建文件的最大数量。
文件系统的空间被分割成一个一个的block,block位图就记录了磁盘上哪些block已经被使用了,哪些是空闲的。inode的数据部分也是以block为单位来管理的。一个inode的数据可能占用多个data blocks,因此创建/删除/修改文件时,除了相应block的内容和inode元数据的改变,block位图也要相应的更新。
block的位图后面还会有一个inode table,即inode表,前面inode位图只记录了那些inode号被占用了,inode表则记录已被使用的inode的更详细的信息,例如size、日期、属性、占用了哪些block等信息。这些信息在内核中通过不同的结构来记录。
inode diagram:一个inode的元数据里除了记录文件信息(size、创建日期、属性等),还要记录inode的数据位于磁盘中的哪些数据块(block),这就是inode diagram。inode diagram是包含在inode table里的,每个inode信息里都维护了自己的inode diagram。
这个diagram可能有多级,因为由于文件可以很大,可能占了很多数据块,所以一级inode diagram可能不足以描述足够多的磁盘块,可以通过间接指向的方法来支持大文件,因此一个inode占用的块可能包括direct blocks, indirect blocks和double indirect blocks。如果一个inode占的块太多,也不好记录和管理inode diagram,因此ext4增加了”extents”的概念,一个extent就是几个地址连续的blocks的集合。比如一个100MB的文件可能被分配给一个单独的extent,而不用像ext3那样新增25600个数据块的记录(假设一个数据块大小是4KB)。极大减少了inode diagram占用的空间,也可以支持更大的文件大小。
再后面就是存放文件数据的data blocks了,一个block通常是4KB(每个block的大小是在文件系统格式化的时候指定的)。当然前面的superblock、inode表等管理信息也占了block。
这些结构都是在存在于磁盘上的,kernel中在挂载了这个分区之后,会去读取磁盘中的superblock、bimap等信息,相应的在内核中也建立相应的数据结构来缓存这些信息。在kernel访问一个文件时,就会从磁盘中找到这个文件的inode信息,并利用inode信息在内核中构建一个struct inode结构体。在读写文件的时候就会去读取inode的data block并在内核中用struct bio结构来缓存这些blocks,并建立与page的联系(因此内核是按page读写的而不是按block)。在发生数据或元数据读写后,某个时间会将内存中的缓存内容和磁盘的内容做同步。
内核的inode结构里面有两个成员函数集i_op和i_fop:
file_operations: 由于inode对应了文件系统中的文件,因此必须记录特定文件系统的文件对应的file_operations。
inode_operations: 包含对inode本身的操作集,例如新建一个新的inode,根据文件名找到inode,以及mkdir/link/unlink/stat等操作。
内核里的super_block结构还包含了文件系统类型以及如何创建和销毁inode的方法(super_operations)等内容。注意你在挂载一个文件系统时,首先得保证你的内核支持这个文件系统才能挂载,要不然就没法赋值file_operations、inode_operations、super_operations这些操作集了。
dentry:对应的是一个路径,它是目录和文件的缓存,用于加快文件系统寻找inode。注意,磁盘中是不存在dentry的。
当open一个文件时,在其路径查询过程中为每一级路径创建一个dentry,例如打开/home/user/a.txt就会产生4个dentry,名字分别是”/”, “home”, “user”, “a.txt”。dentry就是文件路径的缓存,可以节省查找文件的时间。那么删除(unlink、rm)一个文件的时候,它在内核里的dentry也就没用了,因此也会被删除。
Linux里面的目录、子目录、文件都有inode与之对应,目录是一个特殊的文件,普通文件的内容(即inode数据)就是文件数据,而目录文件的内容就是这个目录下的文件或子目录的名字和inode号的列表。
struct file结构:内核中的这个结构体代表了硬盘里一个文件的引用,我们知道一个硬盘真实文件对应一个inode,内核打开一次文件就产生一个file实例,如果多个地方都打开了这个文件,就有多个file实例。
注意一点,文件名不是放在inode表里的,唯一描述一个文件只有inode号(上面说了,一个文件的文件名是放在其父目录的inode数据里面的)。
那么,在打开/usr/bin/emacs这个文件时,就涉及到三个目录文件,”/”, “/usr/”和”/usr/bin/”。我们知道一个inode的inode diagram里记录了它的数据在磁盘中存放的位置,而对于一个目录来说,它的inode的数据就是它下面的文件(或子目录)的列表。因此这里面就要从磁盘读取和查找三次目录文件inode的inode表和数据块:通过”/”的inode diagram找到找到其数据块在哪个block,在数据块的内容中找到其下面的”usr/”的inode号,……,最终找到emacs对应的inode号,就可以找到这个inode号对应的inode信息,然后从磁盘读出来。
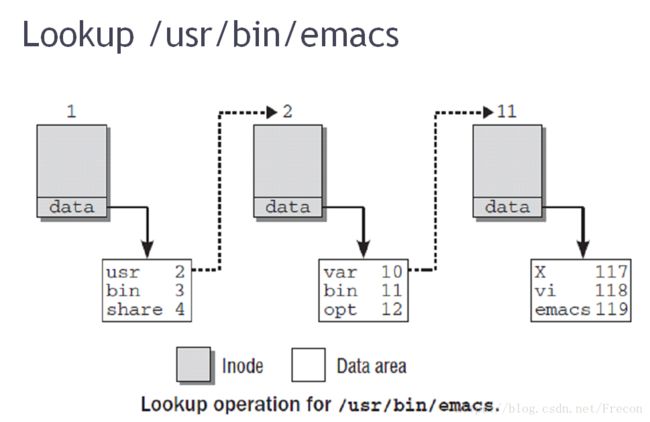
在这过程中查找inode的时候,如果一个文件名已经有dentry缓存了,查找路径过程就会快很多,dentry中存放了文件名及其对应的inode,以及父目录的dentry和子目录的dentry链表等信息。
我们看到的文件的大小,不计算元数据的,元数据是文件系统本身实现的开销,所以新创建的文件大小是0。
符号链接和硬链接
上面说文件名和目录名,它们都是一个特殊inode(父目录的inode)数据里的内容,来指明文件名和目录对应的inode号。
那么硬链接,比如在目录a下有b文件,则给b创建其硬链接c,就是在a的inode的内容里添加一个条目c,并c指向和b相同的inode号,即,硬链接的创建和删除实际上操作的是其父目录文件,并没有创建新的inode。
符号链接(软链接)则是创建了一个新的inode,即符号链接在硬盘里是真实存在的,比如给a创建符号链接b,则a和b是两个不同的inode,只是b的inode里的内容指明了它是指向a的。
创建硬链接的命令:
ln a.out b.out //给a.out创建一个硬链接b.out创建符号链接的命令:
ln -s a.out b.out //给a.out创建一个符号链接b.out通过 ls -l -i 可打印出文件的inode号,就可以看出硬链接两个文件的inode号相同,创建日期也相同,而符号链接是不同的inode号,创建日期不同。
[root@ubuntu]test:$ mkdir a; cd a
[root@ubuntu]test:$ touch 1 2 3
[root@ubuntu]test:$ cd ..
[root@ubuntu]test:$ ln -s a b
[root@ubuntu]test:$ ln b c
[root@ubuntu]test:$ ls -li
total 4
2633550 drwxrwxr-x 2 root root 4096 4月 20 23:32 a
2633554 lrwxrwxrwx 2 root root 1 4月 20 23:33 b -> a
2633554 lrwxrwxrwx 2 root root 1 4月 20 23:33 c -> a
[root@ubuntu]test:$对于硬链接需要注意:
1.硬链接不能跨本地文件系统,这很好理解,因为它们相同的inode呀。
2.也不能对目录建立硬链接,因为场景可能就复杂化了,例如对..做硬链接就可能乱了,又例如非空目录创建硬链接,你还要给目录和子目录都改变inode内容,所以理论上不是不能,而是避免复杂。
对于符号链接需要注意:
1.针对目录的软链接,即使原目录非空,用 “rm -rf” 是删除不了原目录里的内容的,你删的只是这个软链接。
2.针对目录的软链接, “cd ..” 进的是软链接所在目录的上级目录。
所以记住,符号链接是一个独立的存在,文件本身和原文件没有关系。
我们用软链接比较多,当然硬链接也有好处,例如它不占用inode号。软链接可以跨文件系统。
cp命令的-l选项就是硬链接。
修改文件时,修改原文件、符号链接文件和硬链接文件,它们的文件内容都会同时修改。对于删除文件,如果删除符号链接,由于是独立的inode,对原文件没有任何影响;如果是硬链接,如果删除原文件或硬链接,则递减其inode的引用计数,最后一个文件被删除后,这个inode也就被删除了。
Linux删除文件实际都只是删除其硬链接,unlink和rm的效果相同。仍要注意,可以对文件执行unlink或rm,但不能对目录执行unlink。
icache和dcache
这里指inode和dentry的cache。在内核中inode和dentry结构是通过slab cache来分配的,因为这两个结构可能会频繁的用到,所以内核中在inode_init()和dcache_init()中分别创建了两个cachep(inode.c和dcache.c): inode_cachep和dentry_cache。并且标记它们是SLAB_RECLAIM_ACCOUNT即这块slab是可回收的。
VFS这一层的inode和dentry记录了文件系统无关的信息。通过dentry的d_inode可以找到路径对应的inode,而inode_cachep是存放inode的,inode的i_private指向特定文件系统的inode信息,例如指向ext4_inode_cachep的对象(fs/ext4/super.c),对象类型为struct ext4_inode_info,这就是磁盘中inode表里的记录每个inode信息的一项了。
磁盘中没有dentry,dentry是VFS层的概念,用来查找路径以及定位inode和sb,只是为了加速查找文件做的缓存(所以内核中与dentry相关的文件都是以dcache即Dirent cache命名的)。而inode结构也只是磁盘inode在内核里的表示,如果用完了也可以释放,只是下次再用时要重新从磁盘里读。
我们知道可以通过/proc/sys/vm/drop_caches主动释放page cache(fs/drop_caches.c, drop_pagecache_sb()),我们可以通过三个值做不同级别的回收:
to free pagecache:
echo 1 > /proc/sys/vm/drop_caches
to free reclaimable slab objects (includes dentries and inodes):
echo 2 > /proc/sys/vm/drop_caches
to free slab objects and pagecache:
echo 3 > /proc/sys/vm/drop_caches可以看到,上面把inode和dentry的slab cache置为SLAB_RECLAIM_ACCOUNT了,那么往/proc/sys/vm/drop_caches写2或3时就会回收这些slab cache。在icache和dcache初始化的时候同时注册了相应的shrinker操作:dcache_shrinker和icache_shrinker,它们会根据LRU回收inode和dentry的slab。也就是说,我不释放icache和dcache中的对象,这些对象也可能被收缩器(shrinker)回收掉,因为它们只是缓存用的。
在文件系统umount的时候也是调shrinker函数来释放某个sb中的dcache。
注意一点,你创建一个slab cache的时候,如果要指定SLAB_RECLAIM_ACCOUNT,你就需要自己实现这个cache的收缩器。当然,内核已经帮你实现好了icache和dcache的收缩器。
系统掉电后文件系统的一致性
从上面的文件系统layout可以看出,删除一个文件的时候,要涉及到清除inode bitmap和dentry bitmap以及inode表信息和文件父目录数据的列表等。那么,如果在删除一个文件过程中,这些操作没有完成就断电了,那么文件系统的layout就被破坏了。因此我们要尽量保证这些操作的原子性。
以apend文件为例,注意,apend比write要简单是因为它只需要增加data block,而不需要修改已有的data block。但仍然需要涉及inode bitmap和dentry bitmap以及inode信息的更新,在apend过程中这其中某一项工作没完成就断电,就可能出现这个文件信息或状态不对,甚至指向其他文件的数据,导致不一致问题。
- 任何的软件技术都无法保证掉电不丢数据!只能保证一致性(元数据+数据的一致性,或者仅元数据的一致性)!因为软件的步骤没办法保证原子性,只能借助硬件例如UPS或大电容来保证,这时就得考虑前向兼容或成本了。
- 对dirty_expire_centisecs的调整或者DIRECT_IO、SYNC_IO,它们不影响丢或不丢数据,只影响丢多少数据。并且更频繁的IO会导致系统性能下降。
- fsck、日志、CoW文件系统等技术,帮忙改善一致性问题。
fsck(file system consistency check):可以检查并尝试修复文件系统的不一致问题。在unclean shutdown后自动运行(Linux检查到是异常断电后在下次启动会自动运行fsck),也可以手动运行,例如fsck.ext4。它可以检查superblock、inode和free block bitmap、所有inode的reachability(比如删除corrupted的inode)、验证目录的一致性。但fsck做全面检查会很慢,所以有时你发现Linux启动的很慢。
有的时候一些问题fsck检查不出来(认为文件系统是clean的),可以用 fsck -f 强制做检查没准儿能够查出更多的不一致问题并进行修复。
但是fsck很慢,所以很多文件系统使用了日志(例如ext3相对于ext2就增加了日志,即journaling,xfs也是日志文件系统):修改文件时,先把需要的各个步骤写进日志区,写进日志后进行commit,表示日志写完了;然后开始实际修改磁盘内容,改完后进行日志checkpoint,表示实际工作完成了;然后将这部分日志free掉。
数据库中有“transaction”即“事务”的概念,一个事务具有原子性,例如两地买车票,不可能让同一张票被两个人都买走,要么都买不走,要么只有某一个人买走;事务还具备一致性,事务应确保数据库的状态从一个一致状态转变为另一个一致状态;事务还应具有持久性,一个事务一旦提交,它对数据库的修改应该永久保存在数据库中。
文件系统的journal机制,就类似于数据库里的transaction技术,把必须原子完成的一系列行为作为一个事务。日志有4个阶段:
1. Journal write: 把一个begin block和事务的内容(这里指inode的数据和元数据)写到日志,等待所有内容写完。
2. Journal commit: 将一个commit block写进日志表示这个事务被commit了。
3. Checkpoint: 将事务的内容写到磁盘中真正的目标位置。
4. Free: 在某一时刻,将这个事务的日志标记为free(通过修改journal superblock)。
如果commit之前掉电,即第1、2步没完成,那么日志就当这些操作从没发生过,直接不管。
如果checkpoint之前掉电,即第3步没完成,下次重新把已commit但没有完成checkpoint的事务重做步骤1、2。
日志区也是存在于磁盘里的,所以日志会造成磁盘浪费,但日志一般都是元数据,元数据比数据小得多。并且某个日志操作完成后,该日志就释放了,因此并不会占太多磁盘空间。但是对性能的影响是我们应该考虑的,本来IO就慢,你还要每次把所有元数据和数据写进日志,然后再重复一遍所有操作到数据实际位置,尤其是数据比较大,数据日志更耗性能。实际上很多工程实践下都只做元数据日志,而不做数据日志,这样能一定程度上保证一致性以及保证至少文件系统本身不被破坏。
那么,只做元数据(metadata)日志的步骤如下(这里的事务只包含元数据的操作):
1. Data write: 将数据写到磁盘的目标位置,等待数据写完(也可以不等待写完,取决于挂载时的data=writeback(不等,可同步写)还是data=ordered(先写完数据再写元数据))。
2. Journal metadata write: 把一个begin block和事务的内容(这里指元数据)写到日志,等待所有内容写完。
3. Journal metadata commit: 将一个commit block写进日志,等待写完,表示这个事务被commit了。
4. Checkpoint metadata: 将事务的内容写到磁盘中真正的目标位置。
5. Free: 在某一时刻,将这个事务的日志标记为free(通过修改journal superblock)。
在挂载ext4文件系统时指定data=journal,则表示对数据也进行日志。
CoW文件系统也可以用来保证文件系统一致性,即“写时拷贝”的文件系统,每次写磁盘时,先将新数据写入一个新的block,如果有与之关联的数据也需要一并创建新block(如fs tree结构的各级父节点)。当数据和对应元数据全部写完后,将superblock指针指向新的根节点即可,原来的数据块就被free掉(递减引用计数)。给系统做快照(snapshot)就利用的这种思想,只有被修改的块才需要做拷贝,未改动的就仍使用原树结构。snapshot的作用是给某些内容做快照,原数据和snapshot数据互不干扰,这样原数据出问题了,就可以用snapshot来恢复。
btrfs就属于cow文件系统。那么,如果cow文件系统的事务没有完成就掉电,superblock仍指向原来的fs tree的根节点。如果事务已完成则superblock指向新的根节点。而避免文联系统被破坏或不一致。它用这种方式代替日志来实现文件系统的一致性。
文件系统一致性实验
实验一:尝试破坏文件系统layout并修复
dd创建一个4MB的文件:
[root@ubuntu]image:$ dd if=/dev/zero of=image bs=4096 count=1024
1024+0 records in
1024+0 records out
4194304 bytes (4.2 MB) copied, 1.54395 s, 2.7 MB/s把这个文件格式化成ext4:
[root@ubuntu]image:$ mkfs.ext4 -b 4096 image
mke2fs 1.42 (29-Nov-2011)
image is not a block special device.
Proceed anyway? (y,n) y
Discarding device blocks: done
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
1024 inodes, 1024 blocks
51 blocks (4.98%) reserved for the super user
First data block=0
1 block group
32768 blocks per group, 32768 fragments per group
1024 inodes per group
Allocating group tables: done
Writing inode tables: done
Filesystem too small for a journal
Writing superblocks and filesystem accounting information: donedump一下这个文件的细节:
[root@ubuntu]image:$ dumpe2fs image
dumpe2fs 1.42 (29-Nov-2011)
Filesystem volume name:
Last mounted on: <not available>
Filesystem UUID: 24f92bb1-cc02-402d-a157-bbd72e5177b2
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 1024
Block count: 1024
Reserved block count: 51
Free blocks: 982
Free inodes: 1013
First block: 0
Block size: 4096
Fragment size: 4096
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 1024
Inode blocks per group: 32
Flex block group size: 16
Filesystem created: Thu Apr 26 00:51:18 2018
Last mount time: n/a
Last write time: Thu Apr 26 00:51:19 2018
Mount count: 0
Maximum mount count: -1
Last checked: Thu Apr 26 00:51:18 2018
Check interval: 0 ()
Lifetime writes: 73 kB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Default directory hash: half_md4
Directory Hash Seed: 80bd74c9-c07d-49fb-a510-92dce8ceea15
Group 0: (Blocks 0-1023) [ITABLE_ZEROED]
Checksum 0x3b7d, unused inodes 1013
Primary superblock at 0, Group descriptors at 1-1
Block bitmap at 2 (+2), Inode bitmap at 18 (+18)
Inode table at 34-65 (+34)
982 free blocks, 1013 free inodes, 2 directories, 1013 unused inodes
Free blocks: 8-17, 19-33, 67-1023
Free inodes: 12-1024
可以看到其中的Block bitmap在第2块,Inode bitmap在第18块。
现在我去看一下第18块的内容:
[root@ubuntu]image:$ dd if=image bs=4096 skip=18 | hexdump -C -n 32
00000000 ff 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020
[root@ubuntu]image:$我们看到上面Free inodes是12-1024,也就是新的inode号会从12开始分配。
下面我把image当做一块本地硬盘设备(类似于/dev/sda)来挂载到diskroot目录下,然后新建一个文件nihao.txt:
[root@ubuntu]image:$ mkdir diskroot
[root@ubuntu]image:$ mount -o loop image diskroot
[root@ubuntu]image:$ cd diskroot/
[root@ubuntu]diskroot:$ ls
lost+found
[root@ubuntu]diskroot:$
[root@ubuntu]diskroot:$
[root@ubuntu]diskroot:$ echo hello > nihao.txt
[root@ubuntu]diskroot:$ ls -i nihao.txt
12 nihao.txt
[root@ubuntu]diskroot:$我们看到新的inode是12,我们再看dumpe2fs的结果,Free inodes就是13-1024了。
并且我再看一下inode位图,就发现填充了一位:
[root@ubuntu]image:$ umount diskroot
[root@ubuntu]image:$ dd if=image bs=4096 skip=18 | hexdump -C -n 32
00000000 ff 0f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020
[root@ubuntu]image:$这里不umount也可以,只是我们平时在用dd的时候最好先umount,防止裸盘操作与基于文件系统的操作冲突。
上面位图的位号就用来做inode号,这里应该是 00 07 ff ff 的小端模式,这得看具体实现怎么管理的数据结构了,看样子是多个unsigned long数组。
那么我现在试图破坏文件系统:将inode bitmap改一下,把 ff 0f 重新改回 ff 07 。
[root@ubuntu]image:$ vi -b image用 :%!xxd -g 1 切换为十六进制编辑模式(用 :%!xxd -r 可切回来)。上面看到inode bitmap在第18块,而Block size是4096,所以我跳到 18*4096即0x12000 的位置,将0f改为07。
改回文本编辑模式,保存退出,再用dd看一下image里的inode bitmap就发现已经变成 ff 07 了。但我们发现,nihao.txt仍然存在,且inode号是12。
[root@ubuntu]image:$ mount -o loop image diskroot
[root@ubuntu]image:$ cd diskroot/
[root@ubuntu]diskroot:$ ls -il
total 20
11 drwx------ 2 root root 16384 4月 26 00:51 lost+found
12 -rw-r--r-- 1 root root 6 4月 26 01:05 nihao.txt
[root@ubuntu]diskroot:$这就发生了不一致的问题:inode号12被使用了,但inode bitmap里标记12是空闲的。那么我新建一个文件:
[root@ubuntu]diskroot:$ echo hello > hello.txt
bash: hello.txt: Input/output error
[root@ubuntu]diskroot:$出错了。我们用dmesg看看发生了什么:
[root@ubuntu]diskroot:$ dmesg
... ...
[934534.401246] EXT4-fs (loop0): mounted filesystem without journal. Opts: (null)
[934722.155239] EXT4-fs error (device loop0): __ext4_new_inode:983: comm bash: failed to insert inode 12: doubly allocated?我们看到分配inode号12失败,文件系统认为你doubly allocated了。所以你就看到文件系统不一致可能会导致的问题。
文件系统出现问题,可以用fsck来修复,此时文件系统已经知道自己出错了,我们来尝试修一下:
[root@ubuntu]diskroot:$ cd ..
[root@ubuntu]image:$ fsck.ext4 image
e2fsck 1.42 (29-Nov-2011)
Group descriptor 0 has invalid unused inodes count 1012. Fix? yes
image contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Free inodes count wrong for group #0 (1011, counted=1012).
Fix? yes
Free inodes count wrong (1011, counted=1012).
Fix? yes
image: ***** FILE SYSTEM WAS MODIFIED *****
image: 12/1024 files (0.0% non-contiguous), 43/1024 blocks
[root@ubuntu]image:$ 他说修复了inode的数量,我们再用dd看inode bitmap就已经变回 ff 0f 了。
我们一开始篡改了inode位图后,fsck并没有检查出错误,因为文件系统还没有意识到自己出错了。实际上这时可以用 -f 选项强制检查:
[root@ubuntu]image:$ fsck.ext4 -f image
e2fsck 1.42 (29-Nov-2011)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Inode bitmap differences: +12
Fix? yes
image: ***** FILE SYSTEM WAS MODIFIED *****
image: 12/1024 files (0.0% non-contiguous), 43/1024 blocks
[root@ubuntu]image:$
实验二:通过裸盘操作获取文件内容
我们还可以用debugfs工具来分析文件,debugfs既是文件系统类型,又是一个工具,例如:
获得文件main.c(位于/dev/sdb1中)在磁盘中的信息
debugfs -R 'stat /home/zhenfg/main.c' /dev/sdb1
通过 block号找inode:
debugfs -R 'icheck 1035173' /dev/sdb1
通过inode号找文件名:
debugfs -R 'ncheck 367289' /dev/sdb1接下来,我在diskroot目录下创建一个off.e文件,用debugfs分析一下该文件:
[root@ubuntu]image:$ debugfs -R 'stat ./off.e' image
debugfs 1.42 (29-Nov-2011)
Inode: 14 Type: regular Mode: 0644 Flags: 0x80000
Generation: 3726982382 Version: 0x00000001
User: 0 Group: 0 Size: 49554
File ACL: 0 Directory ACL: 0
Links: 1 Blockcount: 104
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x5ae1348f -- Thu Apr 26 10:08:15 2018
atime: 0x5ae1348f -- Thu Apr 26 10:08:15 2018
mtime: 0x5ae1348f -- Thu Apr 26 10:08:15 2018
EXTENTS:
(0-12):69-81可以看到,文件的inode号是14,Size是49554字节,数据占用了13个block(69-81)。
可以用icheck来通过块号查找其所属的inode:
[root@ubuntu]image:$ debugfs -R 'icheck 69' image
debugfs 1.42 (29-Nov-2011)
Block Inode number
69 14
[root@ubuntu]image:$ debugfs -R 'icheck 75' image
debugfs 1.42 (29-Nov-2011)
Block Inode number
75 14
[root@ubuntu]image:$由于第69和第75块都属于off.e文件,因此得到的inode都是14。
可以用ncheck来通过inode号查找其文件名:
[root@ubuntu]image:$ debugfs -R 'ncheck 14' image
debugfs 1.42 (29-Nov-2011)
Inode Pathname
14 //off.e
下面我们看一下blkcat工具的作用:
在image设备挂载的根目录diskroot中有一个文件seekfile.c,我们通过blkcat来查看它的内容:
通过debugfs stat可以看到seekfile.c的inode是13,在第68块。
[root@ubuntu]image:$ blkcat image 68
#define _FILE_OFFSET_BITS 64
#ifndef __USE_FILE_OFFSET64
#define __USE_FILE_OFFSET64
#endif
#ifndef __USE_LARGEFILE64
#define __USE_LARGEFILE64
#endif
#ifndef _LARGEFILE64_SOURCE
#define _LARGEFILE64_SOURCE
#endif
#include
#define FILENAME "/dev/sda1"
void main(int argc, char *argv[])
{
int fd;
off64_t len;
off64_t len2;
fd = open64(FILENAME , O_RDWR, 0644);
printf("fd = %d\n", fd);
if (fd == -1)
perror("open error");
len = (off64_t)16106127360LL;
//len = (off64_t)16;
len2 = lseek64(fd, len, 0);
if (len2 == -1)
perror("lseek error");
printf("len = %lld, len2 = %lld\n",len, len2);
close(fd);
return;
}
[root@ubuntu]image:$可以看到blkcat可以输入块设备文件某一块的内容。
其实我还可以用dd命令来看,这时我把bs改为一个扇区的大小512,则skip掉68*8个bs(每个block为4096,则一个block有8个sector)就找到了seekfile.c的第一块,
[root@ubuntu]image:$ dd if=image of=outfile bs=512 skip=$((68*8)) count=1
1+0 records in
1+0 records out
512 bytes (512 B) copied, 7.4932e-05 s, 6.8 MB/s
[root@ubuntu]image:$ vi outfile就看到也输出了seekfile.c开始部分的内容。
通过fdisk可以看到一个硬盘中每个分区的偏移,例如:
[root@ubuntu]image:$ fdisk /dev/sda
Command (m for help): p
Disk /dev/sda: 53.7 GB, 53687091200 bytes
255 heads, 63 sectors/track, 6527 cylinders, total 104857600 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x000e2b20
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 102762495 51380224 83 Linux
/dev/sda2 102764542 104855551 1045505 5 Extended
/dev/sda5 102764544 104855551 1045504 82 Linux swap / Solaris
Command (m for help): quit上面表明了/dev/sda有三个分区,硬盘的一个扇区(sector)大小是512字节,每一行的Start和End指明这个分区的起始和结束扇区号,即/dev/sda1是从硬盘的第2048个分区处开始的。
通过文件名open文件的过程应该是从根目录”/”开始找的,因为每个目录下面存放了里面的文件和子目录的inode号和名字列表,然后就方便向下找了。而根目录的inode可以预先读出来缓存。所以一点都不慢。