Person ReID相关术语及评测指标解读
行人重识别(Person ReID)是目前深度学习计算机视觉领域里非常火热同时比较前沿的研究课题,最近在研究reid相关的算法,在不少论文中遇到相关的专业术语及评测指标,这里简单做一下总结。同时补充下行人重识别常用数据集(论文中研究的)。
Person ReID
行人重识别(Person Re-identification)也称行人再识别,本文简称为ReID,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。
常用的度量损失
常用的度量学习损失方法有对比损失(Contrastive loss)、三元组损失(Triplet loss)、 四元组损失(Quadruplet loss)、难样本采样三元组损失(Triplet hard loss with batch hard mining, TriHard loss)、边界挖掘损失(Margin sample mining loss, MSML)。
首先,假如有两张输入图片 和 ,通过网络的前馈我们可以得到它们归一化后的特征向量 和 。我们定义这两张图片特征向量的欧式距离为:
对比损失(Contrastive loss)
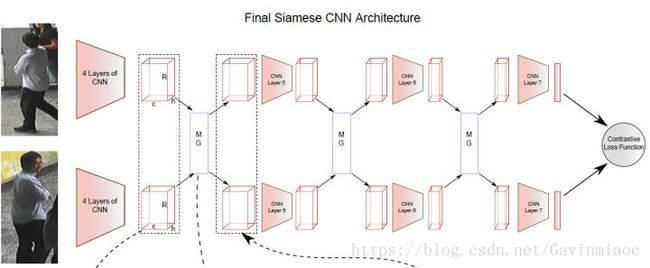
对比损失用于训练孪生网络(Siamese network),其结构图如上图所示。孪生网络的输入为一对(两张)图片 和 ,这两张图片可以为同一行人,也可以为不同行人。每一对训练图片都有一个标签 ,其中 表示两张图片属于同一个行人(正样本对),反之 表示它们属于不同行人(负样本对)。之后,对比损失函数写作:
其中 表示 , 是根据实际需求设计的阈值参数。为了最小化损失函数,当网络输入一对正样本对, 会逐渐变小,即相同ID的行人图片会逐渐在特征空间形成聚类。反之,当网络输入一对负样本对时, 会逐渐变大直到超过设定的 。通过最小化 ,最后可以使得正样本对之间的距离逐渐变小,负样本对之间的距离逐渐变大,从而满足行人重识别任务的需要。
三元组损失(Triplet loss)
三元组损失是一种被广泛应用的度量学习损失,之后的大量度量学习方法也是基于三元组损失演变而来。顾名思义,三元组损失需要三张输入图片。和对比损失不同,一个输入的三元组(Triplet)包括一对正样本对和一对负样本对。三张图片分别命名为固定图片(Anchor) ,正样本图片(Positive) 和负样本图片(Negative) 。图片 和图片 为一对正样本对,图片 和图片 为一对负样本对。则三元组损失表示为:
如下图所示,三元组可以拉近正样本对之间的距离,推开负样本对之间的距离,最后使得相同ID的行人图片在特征空间里形成聚类,达到行人重识别的目的。
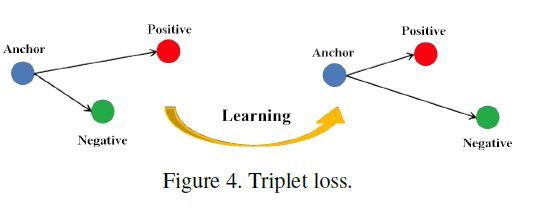
论文[2]认为原版的Triplet loss只考虑正负样本对之间的相对距离,而并没有考虑正样本对之间的绝对距离,为此提出改进三元组损失(Improved triplet loss):
公式添加 项,保证网络不仅能够在特征空间把正负样本推开,也能保证正样本对之间的距离很近。
四元组损失(Quadruplet loss)
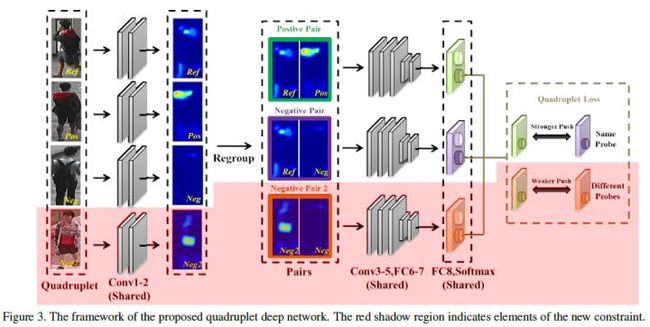
四元组损失是三元组损失的另一个改进版本。顾名思义,四元组(Quadruplet)需要四张输入图片,和三元组不同的是多了一张负样本图片。即四张图片为固定图片(Anchor) ,正样本图片(Positive) ,负样本图片1(Negative1) 和负样本图片2(Negative2) 。其中 和 是两张不同行人ID的图片,其结构如上图所示。则四元组损失表示为:
其中 和 是手动设置的正常数,通常设置 小于 ,前一项称为强推动,后一项称为弱推动。相比于三元组损失只考虑正负样本间的相对距离,四元组添加的第二项不共享ID,所以考虑的是正负样本间的绝对距离。因此,四元组损失通常能让模型学习到更好的表征。
难样本采样三元组损失(Triplet loss with batch hard mining, TriHard loss)
难样采样三元组损失(本文之后用TriHard损失表示)是三元组损失的改进版。传统的三元组随机从训练数据中抽样三张图片,这样的做法虽然比较简单,但是抽样出来的大部分都是简单易区分的样本对。如果大量训练的样本对都是简单的样本对,那么这是不利于网络学习到更好的表征。大量论文发现用更难的样本去训练网络能够提高网络的泛化能力,而采样难样本对的方法很多。论文[10]提出了一种基于训练批量(Batch)的在线难样本采样方法——TriHard Loss。
TriHard损失的核心思想是:对于每一个训练batch,随机挑选 个ID的行人,每个行人随机挑选 张不同的图片,即一个batch含有 张图片。之后对于batch中的每一张图片 ,我们可以挑选一个最难的正样本和一个最难的负样本和 组成一个三元组。
首先我们定义和 为相同ID的图片集为 ,剩下不同ID的图片图片集为 ,则TriHard损失表示为:
其中 是人为设定的阈值参数。TriHard损失会计算 和batch中的每一张图片在特征空间的欧式距离,然后选出与 距离最远(最不像)的正样本 和距离最近(最像)的负样本 来计算三元组损失。通常TriHard损失效果比传统的三元组损失要好。
边界挖掘损失(Margin sample mining loss, MSML)
边界样本挖掘损失(MSML)是一种引入难样本采样思想的度量学习方法。三元组损失只考虑了正负样本对之间的相对距离。为了引入正负样本对之间的绝对距离,四元组损失加入一张负样本组成了四元组。四元组损失也定义为:
假如我们忽视参数 和 的影响,我们可以用一种更加通用的形式表示四元组损失:
其中 和 是一对负样本对, 和 既可以是一对正样本对也可以是一对负样本对。之后把TriHard loss的难样本挖掘思想引入进来,便可以得到:
其中 均是batch中的图片, 是batch中最不像的正样本对, 是batch 中最像的负样本对, 皆可以是正样本对也可以是负样本对。概括而言TriHard损失是针对batch中的每一张图片都挑选了一个三元组,而MSML损失只挑选出最难的一个正样本对和最难的一个负样本对计算损失。所以MSML是比TriHard更难的一种难样本采样,此外 可以看作是正样本对距离的上界, 可以看作是负样本对的下界。MSML是为了把正负样本对的边界给推开,因此命名为边界样本挖掘损失。总的概括,MSML是同时兼顾相对距离和绝对距离并引入了难样本采样思想的度量学习方法。其演变思想如下图:

各种loss的性能对比
在论文[1]之中,对上面提到的主要损失函数在尽可能公平的实验的条件下进行性能对比,实验结果如下表所示。作为一个参考

常用评测指标
reid论文中常用的评测指标有mAP、CMC、ROC等,下面一一分析。
ROC
ROC曲线是检测、分类、识别任务中很常用的一项评价指标。曲线上每个点反映着对同一信号刺激的感受性。具体到识别任务中就是,ROC曲线上的每一点反映的是不同的阈值对应的FP(false positive)和TP(true positive)之间的关系。
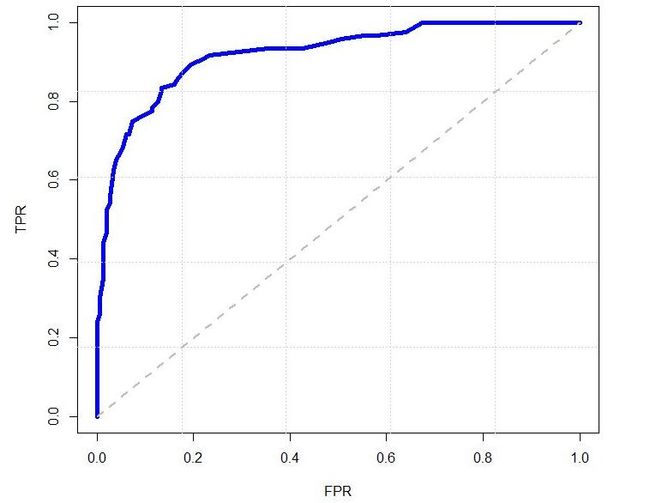
通常情况下,ROC曲线越靠近(0,1)坐标表示性能越好。
CMC
CMC曲线是算一种top-k的击中概率,主要用来评估闭集中rank的正确率。举个很简单的例子,假如在人脸识别中,底库中有100个人,现在来了1个待识别的人脸(假如label为m1),与底库中的人脸比对后将底库中的人脸按照得分从高到低进行排序,我们发现:
- 如果识别结果是m1、m2、m3、m4、m5……,则此时rank-1的正确率为100%;rank-2的正确率也为100%;rank-5的正确率也为100%;
- 如果识别结果是m2、m1、m3、m4、m5……,则此时rank-1的正确率为0%;rank-2的正确率为100%;rank-5的正确率也为100%;
- 如果识别结果是m2、m3、m4、m5、m1……,则此时rank-1的正确率为0%;rank-2的正确率为0%;rank-5的正确率为100%;
同理,当待识别的人脸集合有很多时,则采取取平均值的做法。例如待识别人脸有3个(假如label为m1,m2,m3),同样对每一个人脸都有一个从高到低的得分,
- 比如人脸1结果为m1、m2、m3、m4、m5……,人脸2结果为m2、m1、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(1+1+1)/3=100%;rank-2的正确率也为(1+1+1)/3=100%;rank-5的正确率也为(1+1+1)/3=100%;
- 比如人脸1结果为m4、m2、m3、m5、m6……,人脸2结果为m1、m2、m3、m4、m5……,人脸3结果m3、m1、m2、m4、m5……,则此时rank-1的正确率为(0+0+1)/3=33.33%;rank-2的正确率为(0+1+1)/3=66.66%;rank-5的正确率也为(0+1+1)/3=66.66%;
Precision & Recall & mAP
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
召回率 = 提取出的正确信息条数 / 样本中的信息条数
准确率和召回率都是针对同一类别来说的,并且只有当检索到当前类别时才进行计算,比如在person re-id中,一个人的label为m1,在测试集中包含3张此人的图像,检索出来的图像按照得分从高到低顺序为m1、m2、m1、m3、m4、m1….,此时
- 第一次检索到m1,提取出的正确信息条数=1,提取出的信息条数=1,样本中的信息条数=3,正确率=1/1=100%,召回率=1/3=33.33%;
- 第二次检索到m1,提取出的正确信息条数=2,提取出的信息条数=3,样本中的信息条数=3,正确率=2/3=66.66%,召回率=2/3=66.66%;
第三次检索到m1,提取出的正确信息条数=3,提取出的信息条数=6,样本中的信息条数=3,正确率=3/6=50%,召回率=3/3=100%;
平均正确率AP=(100%+66.66%+50%)/3=72.22%
而当需要检索的不止一个人时,此时正确率则取所有人的平均mAP。
F-Score
从上面准确率和召回率之间的关系可以看出,一般情况下,Precision高,Recall就低,Recall高,Precision就低。所以在实际中常常需要根据具体情况做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。
很多时候我们需要综合权衡这2个指标,这就引出了一个新的指标F-score。这是综合考虑Precision和Recall的调和值。
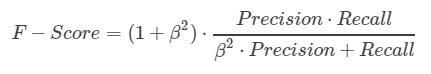
当β=1时,称为F1-score,这时,精确率和召回率都很重要,权重相同。当有些情况下,我们认为精确率更重要些,那就调整β的值小于1,如果我们认为召回率更重要些,那就调整β的值大于1。
比如在上面的例子中,在第三次检索到m1时的争取率为50%,召回率为100%,则F1-score=(2*0.5*1)/(0.5+1)=66.66%,而F0.5-score=(1.25*0.5*1)/(0.25*0.5+1)=55.56%
三个权威数据集简介:
Market-1501
该数据集在清华大学校园中采集,图像来自6个不同的摄像头,其中有一个摄像头为低像素。同时该数据集提供训练集和测试集。训练集包含12,936张图像,测试集包含19,732 张图像。图像由检测器自动检测并切割,包含一些检测误差(接近实际使用情况)。训练数据中一共有751人,测试集中有750人。所以在训练集中,平均每类(每个人)有17.2张训练数据。
DukeMTMC-reID
该数据集在杜克大学内采集,图像来自8个不同摄像头。该数据集提供训练集和测试集。 训练集包含16,522张图像,测试集包含 17,661 张图像。训练数据中一共有702人,平均每类(每个人)有23.5 张训练数据。是目前最大的行人重识别数据集,并且提供了行人属性(性别/长短袖/是否背包等)的标注。
CUHK03
该数据集在香港中文大学内采集,图像来自2个不同摄像头。该数据集提供 机器检测和手工检测两个数据集。 其中检测数据集包含一些检测误差,更接近实际情况。平均每个人有9.6张训练数据。
参考文献:
1.https://zhuanlan.zhihu.com/p/31921944
2.https://blog.csdn.net/q295684174/article/details/78723068
[1] Xiao Q, Luo H, Zhang C. Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification[J]. 2017.
[2] De Cheng, Yihong Gong, Sanping Zhou, Jinjun Wang, Nanning Zheng. Person re-identification by multichannel parts-based cnn with improved triplet loss function[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016:1335-1344.