谷歌宣称首次实现量子优越性,IBM“不服”,中国同行咋看?

谷歌 Sycamore 量子芯片。来源:网络
出品 墨子沙龙作者 黄合良
2019 年 8 月 23 日,谷歌在持续重金投入量子计算 13 年后,成功摘取量子计算领域的一个重要里程碑:实验证明“量子优越性”,在特定任务上,量子计算机可以大大超越经典计算机的计算能力了。虽然,费曼在 38 年前就提出了量子并行计算的概念,但是,这个第一次真正确信无疑地演示这种超级计算能力,花费了全世界科学家们几十年的努力。有国际专家把这个成果比喻为莱特兄弟的首飞,虽然当时的飞行器非常简陋,飞行只持续了 12 秒,完全没有实用价值,但是这预示了一个新技术时代即将到来的曙光。
应该指出的是,谷歌的阶段性实验绝不是终点,而是一个起点。今年 9 月份在合肥举办的新兴量子技术国际大会的白皮书指出,量子计算研究可以沿如下路线开展:“第一个阶段是实现量子优越性,即针对特定问题的计算能力超越经典超级计算机,这一阶段性目标将在近期实现;第二个阶段是实现具有应用价值的专用量子模拟系统;第三个阶段是实现可编程的通用量子计算机,还需要全世界学术界的长期艰苦努力。”
——中国科学技术大学潘建伟 10 月 23 日,权威杂志Nature刊出了谷歌量子 AI 团队的的最新科研工作“Quantum supremacy using a programmable superconducting processor”。至此,谷歌宣称的“量子优越性”终于“坦然公布于众”。事实上,谷歌的论文在 9 月就曾被 NASA 披露,虽不久后被悄悄删除,但该论文已经在业内流传开,并且引起了轩然大波。
论文报道了谷歌团队基于一个包含 53 个可用量子比特的可编程超导量子处理器,运行随机量子线路进行采样,耗时约 200 秒可进行 100 万次采样,并且估计如果使用目前最强超算 Summit来计算得到同样的结果,需耗费约 1 万年。据此,谷歌宣称实现了“量子优越性”。
一、什么是“量子优越性”?
近年来,由于超导量子计算技术的快速发展,量子计算逐渐发展到 50 个左右量子比特规模。尽管如此,考虑到量子纠错需要耗费的资源,真正具备实用化的通用量子计算机至少需要 10 万-100 万量级的量子物理比特。因此,量子计算机的研制是一个极具挑战并且周期可能较长的工作。
为了推动量子计算机的研制,我们必须把其分成一个个的小目标,依据小目标的指引,不断突破。第一个小目标就是“量子优越性”(Quantum Supremacy),指的是量子计算机在某个特定问题上的计算能力远超过性能最好的超算,证明量子计算机的优越性。因此,“量子优越性”被认为是量子计算发展道路上的一个重要里程碑。
刚才提到的“某个特定问题”,即经过精心设计,非常适合于量子计算设备发挥其计算潜力的问题。这类问题包括随机量子线路采样(Random Circuit Sampling)、IQP 线路(Instantaneous Quantum Polynomial)、玻色采样(Boson Sampling),而谷歌量子 AI 团队所针对的问题是随机量子线路采样。
所谓随机量子线路,简单说就是随机从一个量子门的集合中挑选单比特量子门,作用到量子比特上,每作用一层单比特量子门,就会接着做一层两比特量子门,多次重复这样的操作后,测量最终的量子态,即完成一次采样。谷歌为什么挑选这样的问题?主要有两个原因:第一,随机线路采样问题非常适合于在二维结构的超导量子计算芯片上实验实现;第二,已经有很多理论工作证明了随机线路采样问题的困难性。
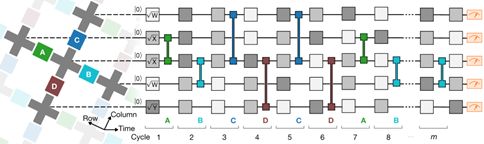
随机量子线路采样示意图
至于为什么随机量子线路经典计算机很难模拟,这里就不再详细叙述(感兴趣的可以参考 Adam Bouland 等人,以及清华学霸陈立杰和 MIT 量子计算专家 Scott Aaronson 对该问题计算复杂度的研究)。但是我们可以举个例子来简单说明一下,比如一个 50 比特的随机量子线路采样,最终输出的量子态的态空间的维度是 250,如果使用经典计算机模拟,首先要存储如此高维度的量子态是极其困难的,其次,在如此高维的计算空间上,模拟每一层的量子计算操作,直至输出最终的计算结果,更是难上加难!
这次谷歌的实验设计的是他们的第三代的线路结构:Sycamore(悬铃木),之前第一代,第二代(狐尾松),已经被中科大团队利用量子隐形传态的思想,在经典超级计算机—神威太湖之光上有效模拟了高达 1000 个量子比特 42 深度的链型线路,和 72 个量子比特 32 深度的狐尾松结构二维线路[6]。受到这一模拟能力的挑战,谷歌被迫设计了“悬铃木”结构的新线路。在谷歌正式发表的 nature 论文中,引用了中科大团队的这一结果。
这里说个题外话,中科大的相关团队一直在演示“量子优越性”的另一途径——光子玻色采样的实验上处于国际领先地位。巧合的是,昨天(10 月 23 日)在 arXiv 上公布了该团队的阶段性新成果[arXiv: 1910.09930][7]:20 光子输入 60*60 模式的玻色采样。论文打破了光子数、模式数、量子态空间三项国际记录,宣称首次达到了百万亿级的输出量子态空间,比之前国际光学同行的工作提高了百亿倍。中国团队有望在光学玻色采样问题上实现量子优越性。论文还在同行评审中。
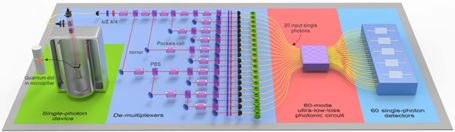
20 光子玻色采样示意图
二、谷歌量子 AI 团队的突破
此次,谷歌量子 AI 团队制备了一块包含 54 个量子比特的超导量子计算芯片,并将其命名为 Sycamore。不幸的是,其中一个量子比特坏掉了,所以可用的量子比特只有 53 个。不过因为坏掉的量子比特在芯片的边缘,基本上不会影响最终实验结果。
这块超导量子芯片基本上汇聚了谷歌量子 AI 团队这几年所发展的所有最先进的实验技术,其中最突出的两项技术是倒装焊封装技术和可调量子耦合器。倒装焊封装技术是一种芯片互连技术,通过倒装焊,可以实现二维排布量子芯片的制备。可调耦合器的作用是调节量子比特间的耦合强度,当我们想让比特间发生耦合实现多比特门时,可以将耦合强度调大,但是当我们不想让比特间发生耦合时,可以关掉耦合器。

Sycamore 芯片的结构和实物图
可调耦合器的突破使得比特间的串扰错误得到有效抑制。从谷歌的基准测试来看,Sycamore 芯片在进行并行量子门操控时,还能保持 99.84% 精度的单比特门、99.38% 精度的两比特门以及 96.2% 精度的读出,综合性能代表了目前超导量子计算的最高水平。
为了说明“量子优越性”,谷歌与目前世界排名第一的超级计算机 Summit 进行了性能比对。在 Sycamore 上进行 53 比特、20 深度的量子随机线路采样,200 秒约可采样 100 万次,并且最终结果的保真度预计有 0.2%;作为对比,谷歌预计超算 Summit 要得到保真度为 0.1% 的结果,需要耗费 1 万年。基于此,谷歌宣称实现了“量子优越性”。
三、“量子优越性”工作的争议
实际上,“量子优越性”代表了两个方面的竞争,一方面量子芯片的比特数和性能不断扩张,在某些问题上展现出极强的计算能力;另一方面,经典算法和模拟的工程化实现也可以不断优化,提升经典算法的效率和计算能力。所以,如果能够提升经典模拟的能力,那么谷歌的量子设备有可能就无法打败最强超算,从而“称霸”失败。实际上这是极有可能的,因为谷歌也无法保证他们在做经典模拟时已经达到了最优,包括他们所使用的薛定谔-费曼算法,以及对超算工程化实现的优化。
有趣的是,IBM 是第一个跳出来表示“不服”的。IBM 在 10 月 21 的 arXiv 上论文“Leveraging Secondary Storage to Simulation Deep 54-qubit Sycamore Circuits”中指出,谷歌对随机量子线路的经典模拟优化得并不好,如果采用内存和硬盘混合存储方案,模拟 53 比特、20 深度的量子随机线路采样,仅需 2.5 天。IBM 还宣称这只是他们保守的估计,“一万年太久,只争朝夕”。
其实,IBM 说可以更快地在经典计算机上模拟也不足为奇。毕竟经典算法的发展,以及超算上的工程化实现,还是有提升空间的。“量子优越性”本身也是经典计算和量子计算 Battle 的过程。说不定再过段时间,经典模拟的速度可以直接超过谷歌的 Sycamore 量子计算系统。
但是可以肯定的是,谷歌的工作确实体现了超导量子计算的快速发展,至少已经到了在某些问题上可以跟目前最强超算比一比的能力了。这种实验技术上的进步,也许比“量子优越性”来的更实在。从这个意义上,谷歌有没有实现“量子优越性”这件事很重要,但也许也并不是那么重要。因为量子态的空间维度是随比特数指数增加的,即便谷歌此次“量子优越性”的宣称失败了,但随着量子比特数继续扩张,“量子优越性”也会迟早到来。
四、量子计算的下步路在何方?
纵观量子计算的发展,我们可以明显感受到量子计算技术的进步是显著的。尤其是近几年,这个方向进入了一个技术爆发区。各个量子计算物理体系都得到了长足的发展,以超导为代表的量子计算体系已经突破到 50 比特左右的规模,离子、原子体系也突破了 20 个比特的规模[8],光子体系在 2018 年已实现了 18 比特纠缠[9]。
需要注意的是,谷歌此次宣称的“量子优越性”,目的仅仅是为了在实验上证明量子计算机确实有超越目前最强超算的能力,这并不意味着我们已经实现了实用化的量子计算机。“量子优越性”对于量子计算的发展,仅仅是一个开始。
首先,谷歌的工作来看,虽然他们在比特操控和读取上都达到了极高精度,但是运行 20 层量子线路后,保真度仅达到了 0.2%,这样的精度完全无法支撑大规模量子算法的实验实现;此外,谷歌用来演示量子优越性的问题是没有实用价值的,它的目的仅在于证明量子计算的计算能力。因此,实现通用量子计算还需要很长的时间,我们需要在量子纠错得到突破,以支撑保持高品质地扩展量子比特数,并探索如何有效地发挥量子计算机的优势来解决真正有用的问题。
那么下一步,量子计算的路在何方?2019 年 9 月 15 日在合肥成功举办的新兴量子技术国际会议形成了《量子信息和量子技术白皮书(合肥宣言)》,国际专家在宣言中对量子计算发展的三个阶段达成了共识,“要构建一台真正具有通用计算能力的量子计算机,仍需要长期的努力。”
为了领域的健康长期发展,除了要在基础研究领域做好操纵精度、可容错之外,规模化、实用性的量子计算研究可以沿如下路线开展。第一个阶段是实现“量子优越性”或称“量子称霸”,即量子模拟机针对特定问题的计算能力超越经典超级计算机,这一阶段性目标可在近期实现。第二个阶段是实现具有应用价值的专用量子模拟系统,可在组合优化、量子化学、机器学习等方面发挥效用。第三个阶段是实现可编程的通用量子计算机,能在经典密码破解、大数据搜索、人工智能等方面发挥巨大作用。实现通用可编程量子计算机还需要全世界学术界的长期艰苦努力。”
五、国内相关领域进展和布局
我国在超导量子计算领域起步较晚,相比于谷歌这个领头羊,我们国内的相关科研团队仍处于追赶地位。可喜的是,近年来,以中科大、浙大、中科院物理所等为代表的多个科研团队,已经突破了 20 个量子比特的超导量子计算技术。目前,他们正在攻关 50 比特量子计算技术,并有望在明年底实现“量子优越性”。因此,我国在超导领域虽与美国存在差距,但是不存在代差,如果能够得到持续的投入和支持,未来可期。
作者简介
黄合良,中国科学技术大学朱晓波超导量子计算课题组博士后,主要从事量子计算理论与实验研究。博士期间师从陆朝阳、鲍皖苏教授,致力于光量子计算实验研究,先后在国际上首次实验实现了基于经典指令的安全量子云计算、量子拓扑数据分析,并参与实现了 10 光子纠缠、18 比特纠缠,两度刷新光量子计算纠缠记录。