corosync+pacemaker+crmsh高可用集群
一、基本概念
高可用架构由两个核心部分组成,一个是心跳检测,判断服务器是否正常运行;一个是资源转移,用来将公共资源在正常服务器和故障服务器之间搬动。
整个运行模式就是心跳检测不断的在网络中检测各个指定的设备是否能够正常响应,如果一旦发生设备故障,就由资源转移功能进行应用的切换,以继续提供服务。
corosync,心跳信息传输层,提供集群的信息层(messaging layer)的功能,传递心跳信息和集群事务信息,多台机器之间通过组播的方式监测心跳,它是运行在每一个主机上的一个进程 。
Pacemaker是一个集群管理器。它利用推荐集群基础设施(OpenAIS 或heartbeat)提供的消息和成员能力,由辅助节点和系统进行故障检测和回收,实现性群集服务的高可用性,以crmsh这个资源配置的命令接口来配置资源,用于资源转移。
二、高可用集群的配置
详细配置文档:http://blog.51cto.com/freeloda/1274533
环境配置:
server1:172.25.51.1(集群节点1,corosync、pacemaker、crmsh )
server2:172.25.51.2(集群节点2,corosync、pacemaker、crmsh)
集群配置:
1、两台主机安装pacemaker服务,以及corosync管理服务(这两个服务可以在系统自带镜像安装)
[root@server1 ~]# yum install -y corosync pacemaker
2、配置文件
[root@server1 ~]# cd /etc/corosync/
[root@server1 corosync]# ls
amf.conf.example corosync.conf.example.udpu uidgid.d
corosync.conf.example service.d
[root@server1 corosync]# cp corosync.conf.example corosync.conf
[root@server1 corosync]# vim corosync.conf
compatibility: whitetank
#totem定义集群内各节点间是如何通信的,totem本是一种协议,专用于corosync专用于各节点间的协议,totem协议是有版本的;
totem {
version: 2 #totme的版本,不可更改
secauth: off #安全认证,开启时很耗cpu
threads: 0 #安全认证开启后并行线程数
interface {
ringnumber: 0 #回环号码,若主机有多块网卡,避免心跳汇流
bindnetaddr: 172.25.51.0 #心跳网段,corosync会自动判断本地网卡上配置的哪个IP地址是属于这个网络的,并把这个接口作为多播心跳信息传递的接口
mcastaddr: 226.94.1.1 #心跳信息组播地址(所有节点必须一致)
mcastport: 5405 #组播端口
ttl: 1 #只向外多播ttl为1的报文,防止发生环路
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log ##日志
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
#让pacemaker在corosync中以插件方式启动:
service{
name:pacemaker ##模块名,启动corosync同时启动pacemaker
ver:0 ##版本号
}
3、开启服务corosync
[root@server1 corosync]# /etc/init.d/corosync start
4、安装集群配置软件
[root@server1 ~]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm
5、 crm配置集群
<1>依据校验情况,关闭 stonith
[root@server1 ~]# crm ##进入crm sh模式
crm(live)# configure ##configure模式
crm(live)configure# property stonith-enabled=false ##禁用stonith
crm(live)configure# commit ##提交
crm(live)configure# verify ##现在已经不报错
[root@server1 ~]# crm_verify -LV ##关闭stonith后,不再报错
注意:检查配置文件,报错提示,因为STONITH resources没有定义,因我们这里没有STONITH设备,所以我们先关闭这个属性
[root@server1 ~]# crm_verify -LV

<2>设置vip和监控时间(vip 地址配置成功后,crm定义的资源就会传到各个节点,并在各个节点上生效)
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.51.100 cidr_netmask=24 op monitor interval=1min
crm(live)configure# commit
crm(live)configure# bye
示图:查看网卡vip
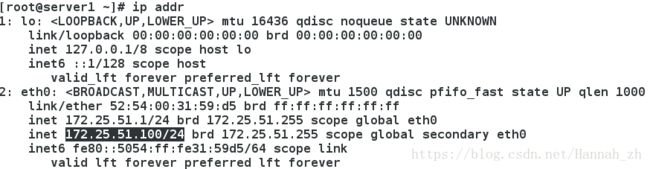
特别说明:查看集群状态的两种方法:
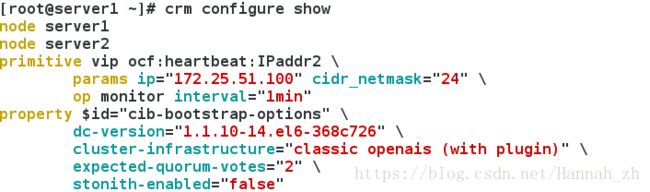

<3>节点1停止心跳检测,并查看集群状态
[root@server1 ~]# /etc/init.d/corosync stop
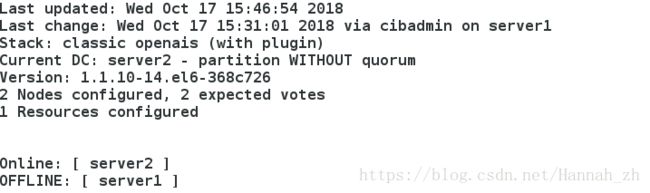
重点说明:节点1已经离线,但资源vip却没能在node2.test.com上启动。这是因为此时的集群状态为"WITHOUT quorum",此时集群服务本身已经不满足正常运行的条件,这对于只有两节点的集群来讲是不合理的。因此,我们可以通过如下的命令来修改忽略quorum不能满足的集群状态检查:property no-quorum-policy=ignore
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit
crm(live)configure# bye
片刻之后,集群就会在目前仍在运行中的节点node2上启动此资源了,如下所示:
[root@server2 ~]# crm_mon ##查看集群状态

<4>节点1设定为备用
[root@server1 ~]# crm node standby
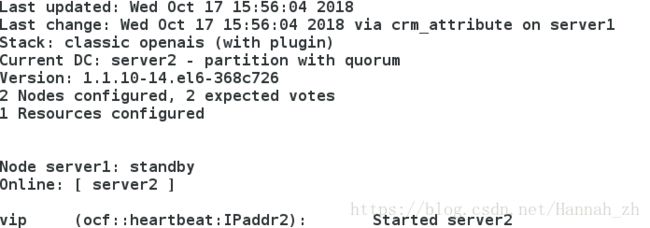
<5>节点1设定为online
[root@server1 ~]# crm node online
