ELK6.7.2搭建教程
一、ELK简介
ELK是三个开源软件的缩写,分别为:Elasticsearch 、 Logstash以及Kibana , 它们都是开源软件。ELK是一整套日志管理系统,对于日志的集中化管理,日志的统计和检索等都能够完美解决。
二、ELK选型
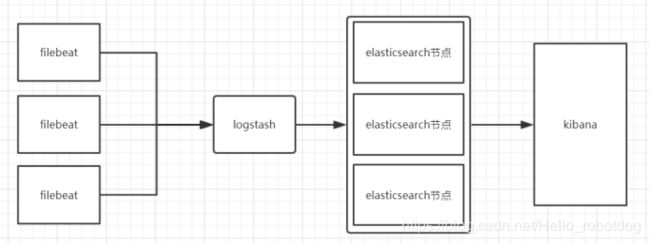
工作模式1:logstash采集、处理、转发到elasticsearch存储,在kibana进行展示
-- datasource->logstash->elasticsearch->kibana
模式特点:这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。

工作模式2:Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
-- datasource->filebeat->logstash-> elasticsearch->kibana
模式特点:这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景
工作模式3:Filebeat采集完毕直接入到kafka消息队列,进而logstash取出数据,进行处理分析输出到es,并在kibana进行展示。(filebeat版本5.0以上才支持直接输出到kafka)
--datasource->filebeat->kafka->logstash->elasticsearch->kibana
模式特点:这种架构适合于日志规模比较庞大的情况。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性。
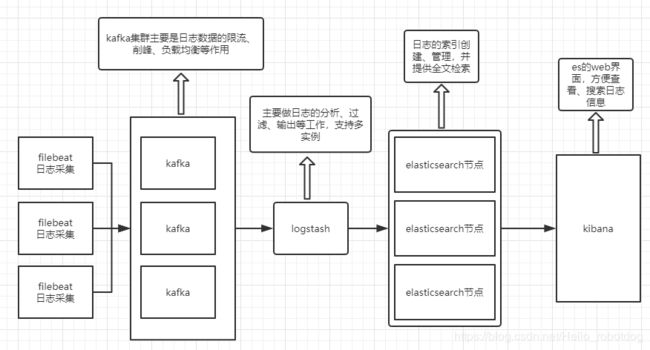
总结:以上是目前流行的ELK收集模式,本次搭建ELK主要是收集数据量极大的日志,综合考虑,选择工作模式3进行搭建。
更多ELK工作模式,请参考文档:https://www.cnblogs.com/qingqing74647464/p/9378385.html
三、安装前的准备工作
3.1 服务器
(1)准备8台服务器,以下是服务器配置详情,及用途。
| 操作系统版本 | IP地址 | CPU核数 | 内存大小(G) | 磁盘大小(G) | 内网访问端口号 | 内网互通权限 | 是否需要访问外网 | 用途 |
| Centos7.6 | 192.168.1.100 | 8 | 8 | 200 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建elasticsearch集群的master1节点及kibana |
| Centos7.6 | 192.168.1.101 | 8 | 8 | 200 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建elasticsearch集群的master2节点 |
| Centos7.6 | 192.168.1.102 | 16 | 16 | 1024 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建elasticsearch集群的data1节点 |
| Centos7.6 | 192.168.1.103 | 16 | 16 | 1024 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建elasticsearch集群的data2节点 |
| Centos7.6 | 192.168.1.104 | 16 | 16 | 1024 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建elasticsearch集群的data3节点 |
| Centos7.6 | 192.168.1.105 | 8 | 16 | 200 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建kafka集群、logstash集群 |
| Centos7.6 | 192.168.1.106 | 8 | 16 | 200 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建kafka集群、logstash集群 |
| Centos7.6 | 192.168.1.107 | 8 | 16 | 200 | 全开 | 同网段互通 | 是 | 内核4.4+,保证能上网,拥有root权限,用于搭建kafka集群、logstash集群 |
(2)安装jdk8
参考文档:https://www.cnblogs.com/shihaiming/p/5809553.html
(3)关闭防火墙
查看防火墙状态:systemctl status firewalld.service
关闭防火墙:systemctl stop firewalld.service
禁止开机启动防火墙:systemctl disable firewalld.service
3.2 版本信息
- Elasticsearch-6.7.2
- logstash-6.7.2
- kibana-6.7.2
- filebeat-6.7.2
- kibana-6.7.2
- kafka_2.11-2.1.1
- zookeeper-3.4.14
- kafka-manager-1.3.3.7(kafka界面管理工具)可根据个人情况选用
四、Elasticsearch
4.1 Elasticsearch简介
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
4.2 Elasticsearch安装
4.2.1 安装
去官网下载elasticsearch的安装包:elasticsearch-6.7.2.tar.gz
地址:https://www.elastic.co/cn/downloads/
(1)上传安装包至linux服务器
(2)解压安装包
[root@master1~]# tar -zxvf elasticsearch-6.7.2.tar.gz #解压安装包
4.2.2 配置
Elasticsearch主要有两个配置文件,elasticsearch.yml 文件用于配置集群节点等相关信息的,elasticsearch 文件则是配置服务本身相关的配置,例如某个配置文件的路径以及java的一些路径配置什么的。
开始配置集群节点,在 192.168.1.100上编辑配置文件:
[root@master1 ~]# vim /usr/elasticsearch/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: master-slave #自定义集群名称
node.name: master-1 #节点名称
node.master: true #是否master节点
node.data: false #是否数据节点
network.host: 0.0.0.0 #监听地址(默认为0.0.0.0),也可以填写多个
http.port: 9200 #es集群提供外部访问的接口
transport.tcp.port: 9300 #es集群内部通信接口
bootstrap.memory_lock: true #避免es使用swap交换分区
discovery.zen.ping.unicast.hosts: ["192.168.2.100:9300", "192.168.2.101:9300", "192.168.2.102:9300", "192.168.2.103:9300", "192.168.2.104:9300"]
192.168.1.101
[root@master2 ~]# vim /usr/elasticsearch/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: master-slave #自定义集群名称
node.name: master-2 #节点名称
node.master: true #是否master节点
node.data: false #是否数据节点
network.host: 0.0.0.0 #监听地址(默认为0.0.0.0),也可以填写多个
http.port: 9200 #es集群提供外部访问的接口
transport.tcp.port: 9300 #es集群内部通信接口
bootstrap.memory_lock: true #避免es使用swap交换分区
discovery.zen.ping.unicast.hosts: ["192.168.2.100:9300", "192.168.2.101:9300", "192.168.2.102:9300", "192.168.2.103:9300", "192.168.2.104:9300"]
192.168.1.102
[root@node1 ~]# vim /usr/elasticsearch/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: master-slave #自定义集群名称
node.name: node-1 #节点名称
node.master: false #是否master节点
node.data: true #是否数据节点
network.host: 0.0.0.0 #监听地址(默认为0.0.0.0),也可以填写多个
http.port: 9200 #es集群提供外部访问的接口
transport.tcp.port: 9300 #es集群内部通信接口
bootstrap.memory_lock: true #避免es使用swap交换分区
discovery.zen.ping.unicast.hosts: ["192.168.2.100:9300", "192.168.2.101:9300", "192.168.2.102:9300", "192.168.2.103:9300", "192.168.2.104:9300"]
192.168.1.103
[root@node1 ~]# vim /usr/elasticsearch/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: master-slave #自定义集群名称
node.name: node-2 #节点名称
node.master: false #是否master节点
node.data: true #是否数据节点
network.host: 0.0.0.0 #监听地址(默认为0.0.0.0),也可以填写多个
http.port: 9200 #es集群提供外部访问的接口
transport.tcp.port: 9300 #es集群内部通信接口
bootstrap.memory_lock: true #避免es使用swap交换分区
discovery.zen.ping.unicast.hosts: ["192.168.2.100:9300", "192.168.2.101:9300", "192.168.2.102:9300", "192.168.2.103:9300", "192.168.2.104:9300"]
192.168.1.104
[root@node1 ~]# vim /usr/elasticsearch/elasticsearch-6.7.2/config/elasticsearch.yml
cluster.name: master-slave #自定义集群名称
node.name: node-3 #节点名称
node.master: false #是否master节点
node.data: true #是否数据节点
network.host: 0.0.0.0 #监听地址(默认为0.0.0.0),也可以填写多个
http.port: 9200 #es集群提供外部访问的接口
transport.tcp.port: 9300 #es集群内部通信接口
bootstrap.memory_lock: true #避免es使用swap交换分区
discovery.zen.ping.unicast.hosts: ["192.168.2.100:9300", "192.168.2.101:9300", "192.168.2.102:9300", "192.168.2.103:9300", "192.168.2.104:9300"]
依此启动
[root@master1 ~]# cd /usr/elasticsearch/elasticsearch-6.7.2/bin/
[root@master1 bin]# ./elasticsearch -d
可能遇到的问题:
1、报错:can not run elasticsearch as root
使用root账户启动造成的报错,这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,建议创建一个单独的用户用来运行ElasticSearch。
创建elsearch用户组及elsearch用户
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
更改elasticsearch文件夹及内部文件的所属用户及组为elsearch:elsearch
cd /usr
chown -R elsearch:elsearch elasticsearch-6.7.2
切换到elsearch用户再启动
su elsearch cd elasticsearch/bin
./elasticsearch -d
2、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
每个进程最大同时打开文件数太小,可通过下面2个命令查看当前数量
修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效
* soft nofile 65536
* hard nofile 131072
* soft memlock unlimited
* hard memlock unlimited
3、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elasticsearch用户拥有的内存权限太小,至少需要262144
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
1.当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给lucene。
2.当机器内存大于64G时,遵循以下原则:
a.如果主要的使用场景是全文检索, 那么建议给ES Heap分配 4~32G的内存即可;其它内存留给操作系统, 供lucene使用(segments cache), 以提供更快的查询性能。
b.如果主要的使用场景是聚合或排序, 并且大多数是numerics, dates, geo_points 以及not_analyzed的字符类型, 建议分配给ES Heap分配 4~32G的内存即可,其它内存留给操作系统,供lucene使用(doc values cache),提供快速的基于文档的聚类、排序性能。
c.如果使用场景是聚合或排序,并且都是基于analyzed 字符数据,这时需要更多的 heap size, 建议机器上运行多ES实例,每个实例保持不超过50%的ES heap设置(但不超过32G,堆内存设置32G以下时,JVM使用对象指标压缩技巧节省空间),50%以上留给lucene。
更多es性能调优参数,参考文档:https://www.jianshu.com/p/532b540d4c46
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
执行sysctl -p
即可永久修改
参考数据(4g/4194304 8g/8388608)如果申请16G的内存,可适当将vm.max_map_count=4194304或8388608
4.2.3 curl查看es集群情况
依此成功启动es的各个集群节点,查看集群的状态:
[root@master1 ~]# curl '192.168.1.100:9200/_cluster/health?pretty'
{
"cluster_name" : "master-slave ",
"status" : "green", # 为green则代表健康没问题,如果是yellow或者red则是集群有问题
"timed_out" : false, # 是否有超时
"number_of_nodes" : 5, # 集群中的节点数量
"number_of_data_nodes" : 3, # 集群中data节点的数量
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
更多使用curl命令操作elasticsearch的内容,参考文档:http://zhaoyanblog.com/archives/732.html
五、kibana
5.1 kibana简介
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
5.2 kibana安装
5.2.1 安装
去官网下载kibana的安装包:kibana-6.7.2.tar.gz
地址:https://www.elastic.co/cn/downloads/
[root@master1 ~]# tar -zxvf kibana-6.7.2.tar.gz
5.2.2 配置
安装完成后,对kibana进行配置:
[root@master1 ~]# vim /usr/kibana/kibana-6.7.2-linux-x86_64/config/kibana.yml # 增加以下内容
server.port: 5601 # 配置kibana的端口
server.host: 192.168.1.100 # 配置监听ip
elasticsearch.hosts: ["http://192.168.1.100:9200","http://192.168.1.101:9200"] # 配置es服务器的ip,如果是集群则配置该集群中主节点的ip
logging.dest: /var/log/kibana.log # 配置kibana的日志文件路径,不然默认是messages里记录日志
创建日志文件:
[root@master-node ~]# touch /var/log/kibana.log
启动kibana服务,并检查进程和监听端口:
[root@master1 ~]# cd /usr/kibana/kibana-6.7.2-linux-x86_64/bin/
[root@master1 bin]# ./kibana &
[root@master1 ~]# ps aux |grep kibana
kibana 3083 36.8 2.9 1118668 112352 ? Ssl 17:14 0:03 /usr/share/kibana/bin/../node/bin/node --no-warnings /usr/share/kibana/bin/../src/cli -c /etc/kibana/kibana.yml
root 3095 0.0 0.0 112660 964 pts/0 S+ 17:14 0:00 grep --color=auto kibana
[root@master1 ~]# netstat -lntp |grep 5601
tcp 0 0 192.168.1.100:5601 0.0.0.0:* LISTEN 3083/node
然后在浏览器里进行访问,如:http://192.168.1.100:5601/ ,由于我们并没有安装x-pack,所以此时是没有用户名和密码的,可以直接访问的。

点击Index Patterns,创建新索引
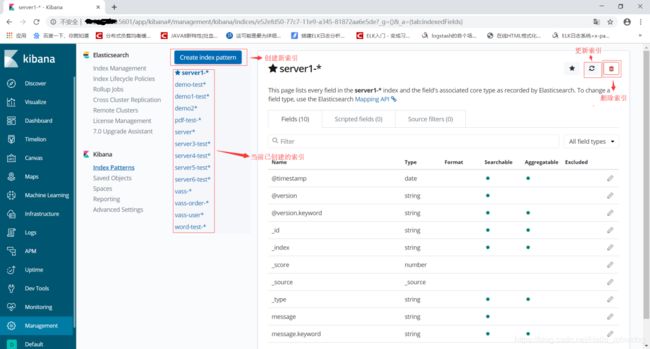
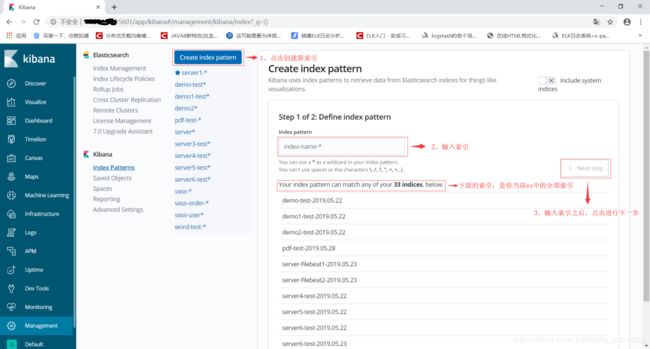



六、Logstash
6.1 Logstash简介
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去
6.2 Logstash安装
6.2.1 安装
去官网下载logstash的安装包:logstash-6.7.2.tar.gz
地址:https://www.elastic.co/cn/downloads/
[root@logstash1 ~]# tar -zxvf logstash-6.7.2.tar.gz
6.2.2 配置
安装完之后,先不要启动服务,先配置logstash收集kafka日志:
[root@logstash1 ~]# cd /usr/logstash-6.7.2/bin/
[root@logstash1 bin]# mkdir conf.d
[root@logstash1 ~]# vim conf.d/first-demo.conf # 加入如下内容
input{
kafka {
bootstrap_servers => "192.168.1.105:9092,192.168.1.106:9092,192.168.1.107:9092"
topics => ["test"]
group_id => "consumer-test"
}
}output {
elasticsearch {
hosts => ["192.168.1.100:9200","192.168.1.101:9200","192.168.1.102:9200","192.168.1.103:9200","192.168.1.104:9200"]
index => "server-test-%{+YYYY.MM.dd}"
}
}
检测配置文件是否有错:
[root@logstash1 ~]# cd /usr/logstash/bin
[root@logstash1 bin]# ./logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit
Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
Configuration OK # 为ok则代表配置文件没有问题
[root@logstash1 bin]#
命令说明:
--path.settings 用于指定logstash的配置文件所在的目录
-f 指定需要被检测的配置文件的路径
--config.test_and_exit 指定检测完之后就退出,不然就会直接启动了
当然你必须要先搭建kafka集群,并创建对应topic,所以这里先不启动logstash,以上是192.168.1.105服务器的配置,根据个人需要,可在192.168.1.106、192.168.1.107服务器上安装logtash,实现logstash集群,也可以单机启动多个logstash,实现单机多节点。
编辑logstash.yml
[root@logstash1 ~]$ cd /usr/logstash-6.7.2/config/
[root@logstash1 config]$ vim logstash.yml
path.logs: /usr/logstash-6.7.2/logstash-data/log #日志路径
path.config: /usr/logstash-6.7.2/bin/conf.d/*.conf #配置文件路径(支持正则)
path.data: /usr/logstash-6.7.2/logstash-data/data #logstash数据保存路径
http.host: "192.168.1.105" #主机ip
启动命令:
[root@logstash1 ~]# cd /usr/logstash-6.7.2
[root@logstash1 logstash-6.7.2]# nohup ./bin/logstash -f ./bin/conf.d/first-demo.conf > ./bin/nohup.out &
七、kafka
7.1 安装zookeeper
7.1.1 下载
去官网下载zookeeper的安装包:zookeeper-3.4.14.tar.gz
地址:https://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.14/
7.1.2 解压
tar -zxvf zookeeper-3.4.10.tar.gz
用192.168.1.105、192.168.1.106、192.168.1.107三台服务器做kakfa集群,当前配置实例为192.168.1.105
[root@logstash1 ~]$ cd /usr/zookeeper-3.4.14
[root@logstash1 zookeeper-3.4.14]$ mkdir data
[root@logstash1 zookeeper-3.4.14]$ mkdir log
#在每一个数据文件目录中,新建一个myid文件,文件必须是唯一的服务标识,在后面的配置中会用到
[root@logstash1 zookeeper-3.4.14]$ echo '1' > data/myid
#复制出zoo.cfg文件:
[root@logstash1 zookeeper-3.4.14]$ cp conf/zoo_sample.cfg conf/zoo.cfg
7.1.3 配置
vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#存储路径
dataDir=/实际路径/zookeeper-cluster/data
#日志路径,方便查LOG
dataLogDir=/实际路径/zookeeper-cluster/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#控制客户的连接数,默认数为60,太少
maxClientCnxns=300
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
#http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#zookeeper集群地址(本机的ip填0.0.0.0)
server.1=0.0.0.0:2888:3888
server.2=192.168.1.106:2888:3888
server.3=192.168.1.107:2888:3888
192.168.1.106、192.168.1.107服务器的配置类似,请参考192.168.1.105服务器配置。
7.1.4 启动
分别启动3个zookeeper服务
$ /usr/zookeeper-3.4.14/bin/zkServer.sh start
$ /usr/zookeeper-3.4.14/bin/zkServer.sh start
$ /usr/zookeeper-3.4.14/bin/zkServer.sh start
启动完成后查看每个服务的状态
$ /usr/zookeeper-3.4.14/bin/zkServer.sh status
$ /usr/zookeeper-3.4.14/bin/zkServer.sh status
$ /usr/zookeeper-3.4.14/bin/zkServer.sh status
7.2 安装kafka
7.2.1 下载
去官网下载kafka的安装包:kafka_2.11-2.1.1.tgz
地址:http://kafka.apache.org/downloads
7.2.2 解压
tar zxvf kafka_2.11-2.1.1.tgz
7.2.3 配置
以192.168.1.105为例
[root@logstash1 ~]$ cd /usr/kafka_2.11-2.1.1/config/server.properties
#配置zookeeper连接,默认Kafka会使用ZooKeeper默认的/路径,这样有关Kafka的ZooKeeper配置就会散落在根路径下面,如果你有其他的应用也在使用ZooKeeper集群,查看ZooKeeper中数据可能会不直观,所以强烈建议指定一个chroot路径,直接在zookeeper.connect配置项中指定
zookeeper.connect=192.168.1.105:2181, 192.168.1.106:2181, 192.168.1.107:2181/kafka
#每个Kafka Broker应该配置一个唯一的ID
broker.id=0
#端口号
port=9092
#如果有多个网卡地址,也可以将不同的Broker绑定到不同的网卡
host.name=192.168.1.105
#日志目录
log.dirs=/usr/kafka_2.11-2.1.1/logs
#设置topic可删除,默认该项是被注释的,需要放开
delete.topic.enable=true
#关闭自动创建topic,默认情况下Producer往一个不存在的Topic发送message时会自动创建这个Topic
auto.create.topics.enable=false
7.2.4 启动
kafka_2.11-2.1.1/bin/kafka-server-start.sh kafka_2.11-2.1.1/config/server.properties &
7.2.5 关闭
kafka_2.11-2.1.1/bin/kafka-server-stop.sh
7.2.6 topic
7.2.6.1 创建topic
kafka_2.11-2.1.1/bin/kafka-topics.sh -topic test -create -partitions 3 -replication-factor 1 -zookeeper 192.168.1.105:2181/kafka
-topic 主题名称
-partitions 分区
-replication-factor 副本
7.2.6.2 查看指定topic属性
kafka_2.11-2.1.1/bin/kafka-topics.sh -describe -zookeeper 192.168.1.105:2181/kafka -topic test
7.2.6.3 查看topic列表
kafka_2.11-2.1.1/bin/kafka-topics.sh -list -zookeeper 192.168.1.105:2181/kafka
7.2.6.4 创建生产者
kafka_2.11-2.1.1/bin/kafka-console-producer.sh -broker-list localhost:9092 -topic test
7.2.6.5 创建消费者
#重新打开一个ssh连接执行以下命令
kafka_2.11-2.1.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
7.2.6.6 测试
在生成者连接中输入内容.
test
在消费者连接中查看是否接收到消息
7.3 kafka相关配置参数
broker.id 整数,建议根据ip区分
log.dirs kafka存放消息文件的路径, 默认/tmp/kafka-logs
port broker用于接收producer消息的端口
zookeeper.connnect zookeeper连接 格式为 ip1:port,ip2:port,ip3:port
message.max.bytes 单条消息的最大长度
num.network.threads broker用于处理网络请求的线程数 如不配置默认为3,server.properties默认是2
num.io.threads broker用于执行网络请求的IO线程数 如不配置默认为8,server.properties默认是2可适当增大,
queued.max.requests 排队等候IO线程执行的requests 默认为500
host.name broker的hostname 默认null,建议写主机的ip,不然消费端不配置hosts会有麻烦
num.partitions topic的默认分区数 默认1
log.retention.hours 消息被删除前保存多少小时 默认1周168小时
auto.create.topics.enable 是否可以程序自动创建Topic 默认true,建议false
default.replication.factor 消息备份数目 默认1不做复制,建议修改
num.replica.fetchers 用于复制leader消息到follower的IO线程数 默认1
参考文档:https://blog.csdn.net/henianyou/article/details/75976052
至此,zookeeper以及kafka集群搭建成功。
八、filebeat
8.1 filebeat简介
beats是ELK体系中新增的一个工具,它属于一个轻量的日志采集器,以上我们使用的日志采集工具是logstash,但是logstash占用的资源比较大,没有beats轻量。
filebeat是用go编写,logstash使用ruby写的。Logstash会占用不少的jvm。
当然,也不是filebeat完全占优,filebeat也专注于采集而已,所以这也是为什么很多架构都是filebeat后面接着logstash来做信息转换。
8.2 filebeat安装
8.2.1 安装
去官网下载filebeat的安装包:filebeat-6.7.2.tar.gz
地址:https://www.elastic.co/cn/downloads/
[root@server ~]# tar -zxvf filebeat-6.7.2.tar.gz
说明:filebeat为日志采集工具,一般是安装在应用服务器。
8.2.2 配置
[root@server ~]# vim /usr/filebeat-6.7.2-linux-x86_64/filebeat.yml # 增加或者更改为以下内容
filebeat.prospectors:
- input_type: log #除了"log",还有"stdin"
paths:
- /tmp/*.log #读取文件路径
#include_lines: ['ERROR'] #只发送包含这些字样的日志
multiline: # 多行合并
pattern: '^\d{4}-\d{1,2}-\d{1,2}' #日期开头的
negate: true
match: after #after和before
fields:
beat.name: xxx.xxx.xxx.xxx #增加属性
log_topics: test
#output.elasticsearch: # 先将这几句注释掉
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
output.kafka:
enabled: true
hosts: ["192.168.1.105:9092","192.168.1.106:9092","192.168.1.107:9092"]
topic: '%{[fields][log_topics]}'
required_acks: 1
8.2.3 启动
[root@server ~]# cd /usr/filebeat-6.7.2-linux-x86_64
[root@server ~]# nohup ./filebeat -e -c filebeat.yml > filebeat.out &
九 ELK测试
9.1 启动
以上将所有组件搭建完毕,依此启动各个组件,启动顺序为:elasticsearch集群、kibana、kafka集群、logstash集群、filebeat。
9.2 验证
去kabana界面,查看对应数据是否成功收集并展示。
十 kafka-manager简介
kafka-manager是目前最受欢迎的kafka集群管理工具,最早由雅虎开源,用户可以在Web界面执行一些简单的集群管理操作。具体支持以下内容:
1、管理多个集群
2、轻松检查群集状态(主题,消费者,偏移,代理,副本分发,分区分发)
3、运行首选副本选举
4、使用选项生成分区分配以选择要使用的代理
5、运行分区重新分配(基于生成的分配)
6、使用可选主题配置创建主题(0.8.1.1具有与0.8.2+不同的配置)
7、删除主题(仅支持0.8.2+并记住在代理配置中设置delete.topic.enable = true)
8、主题列表现在指示标记为删除的主题(仅支持0.8.2+)
9、批量生成多个主题的分区分配,并可选择要使用的代理
10、批量运行重新分配多个主题的分区
11、将分区添加到现有主题
12、更新现有主题的配置
具体安装配置,此文档不做说明。
参考文档:https://www.cnblogs.com/frankdeng/p/9584870.html
最后感谢以下优秀文章的学习、借鉴:
elk搭建:https://blog.51cto.com/zero01/2079879
kafka搭建:https://blog.csdn.net/makang456/article/details/78719698
logstash之grok:https://blog.csdn.net/shunzi1046/article/details/53421701
elk自动定时清理:https://blog.51cto.com/qiuyt/2053441?utm_source=oschina-app