Hadoop2.2.0集群安装
目录
一、Hadoop2.2.0完全分布式集群平台安装设置:
HDFS HA架构:
前提条件:
1、先设定电脑的IP为静态地址:
2、设置各个主机的hostname
3、在所有电脑的/etc/hosts添加以下配置:
4、设置SSH无密码登陆
5、下载解压hadoop-2.2.0.tar.gz:
6、配置Hadoop的环境变量
7、编译Hadoop Native包
8、修改Hadoop的配置文件
9、关闭防火墙
10、查看Hadoop是否运行成功
Hadoop最新安装手册
一、Hadoop2.2.0完全分布式集群平台安装设置:
HDFS HA架构:
在一个典型的 HDFS HA 场景中,通常由两个 NameNode 组成,一个处于 active 状态,另一个处于 standby 状态。Active NameNode 对外提供服务,比如处理来自客户端的 RPC 请求,而 Standby NameNode 则不对外提供服务,仅同步 active namenode 的状态,以便能够在它失败时快速进行切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Bookeeper,Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。
注意,在 Hadoop 2.0 中,不再需要 secondary namenode 或者 backup namenode,它们的工作由 Standby namenode 承担。
本文将重点介绍基于 QJM 的 HA 解决方案。在该方案中,主备 NameNode 之间通过一组 JournalNode 同步元数据信息,一条数据只要成功写入多数 JournalNode 即认为写入成功。通常配置奇数个(2N+1)个 JournalNode,这样,只要 N+1 个写入成功就认为数据写入成功,此时最多容忍 N-1 个 JournalNode 挂掉,比如 3 个 JournalNode 时,最多允许 1 个 JournalNode挂掉,5 个 JournalNode 时,最多允许 2 个 JournalNode 挂掉。基于 QJM 的 HDFS 架构如下

前提条件:
1、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令是否可以在终端使用,如何配置JDK这里就不说了;
2、在每台Linux上安装好SSH,如何安装请参加《Linux平台下安装SSH》。后面会说如何配置SSH无密码登录。
有了上面的前提条件之后,我们接下来就可以进行安装Hadoop分布式平台了。步骤如下:
1、先设定电脑的IP为静态地址:
CentOS下设置IP的方式:
![]()
在里面添加下面语句:

里面的IPADDR地址设置你想要的,我这里是10.10.141.14。
设置好后,需要让IP地址生效,运行下面命令:
![]()
然后运行ifconfig检验一下设置是否生效:
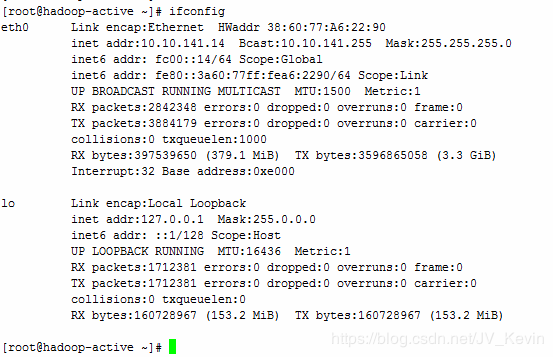
可见IP地址已经设置为10.10.141.14了。
2、设置各个主机的hostname
CentOS设置hostname步骤如下:
![]()
将里面的HOSTNAME修改为你想要的hostname,我这里是取hadoop-active
HOSTNAME=hadoop-active
查看设置是否生效,运行下面命令
![]()
3、在所有电脑的/etc/hosts添加以下配置:
![]()

其实就是所有电脑的静态IP地址和其hostname的对应关系。
检验所有机器配置是否修改生效,可以用ping来查看

如果上面的命令可以ping通,说明配置成功。
4、设置SSH无密码登陆
终端中执行:
[hadoop@hadoop ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): //使用默认位置
Enter passphrase (empty for no passphrase): //直接回车
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
5b:47:52:a7:1e:1c:4d:98:d7:04:eb:d9:0e:5f:dd:3d hadoop@hadoop
The key's randomart image is:
+--[ RSA 2048]----+
| o=++.|
| o+o..|
| . =.. |
| + o o+|
| S . o +E*|
| o . +o|
| o|
| |
| |
+-----------------+
[hadoop@hadoop ~]$
cp /home/hadoop/.ssh/id_rsa.pub /home/hadoop/.ssh/authorized_keys
[hadoop@hadoop ~]$chmod 644 /home/hadoop/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh localhost //测试是否成功
Last login: Thu Dec 8 14:23:46 2011 from localhost.localdomain
[hadoop@hadoop ~]$ exit
logout
Connection to localhost closed.
cat id_rsa.pub >> .ssh/authorized_keys
5、下载解压hadoop-2.2.0.tar.gz:
下载方式不再赘述,可以直接

运行完上面的命令之后,hadoop-2.2.0.tar.gz文件将会保存在/home/$user/Downloads/hadoop里面,然后解压:
![]()
之后将会在hadoop文件夹下面生成hadoop-2.2.0文件夹
6、配置Hadoop的环境变量
在/etc/profile文件的末尾加上以下配置

在终端输入hadoop命令查看Hadoop的环境变量是否生效:
7、编译Hadoop Native包
WARN org.apache.hadoop.util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
在网上查了一下发现Apache官网提供的是32位编译的,在64位服务器上会有问题。而且官方竟然没有提供64位版本,要使用得自己编译。
7.1、编译环境准备
经过一次次编译失败,翻遍了谷歌、百度之后终于凑齐了下面这些包。
下面的服务器环境都基于Centos的,其它发行版Linux可能会有不同。
1、GCC、CMake、openssl、JDK。
2、hadoop-2.2.0-src.tar.gz(http://hadoop.apache.org/releases.html#Download)
3、apache-ant-1.9.2-bin.tar.gz(http://ant.apache.org/bindownload.cgi)
4、apache-maven-3.0.5-bin.tar.gz(http://maven.apache.org/download.cgi)
注意:此处最新的3.1.1版有Bug,缺少依赖包。详细说明如下所示:
https://cwiki.apache.org/confluence/display/MAVEN/AetherClassNotFound
5、findbugs-2.0.2.tar.gz(http://sourceforge.jp/projects/sfnet_findbugs/releases/)
注意:sourceforge.com被墙,只能进sourceforge.jp
6、protobuf-2.5.0.tar.gz(https://code.google.com/p/protobuf/downloads/list)
7、zlib-devel-1.2.3-3.x86_64.rpm
http://rpm.pbone.net/index.php3/stat/4/idpl/8192688/dir/startcom_5/com/zlib-devel-1.2.3-3.x86_64.rpm.html
7.2、依赖环境配置
安装没啥好说的了,大部分都是tar包,解开就能用。只有protobuf需要make一下。
配置好环境后不要忘了source /etc/profile一下,否则不会生效。
下面的图是环境变量配置明细:

7.3、编译
安装好了上面的依赖后就可以编译了。
| mvn package -Pdist,native,docs -DskipTests -Dtar |
然后就是漫长的等待,真的很漫长(用小时来做单位的)。当你看到一串SUCCESS的时候,那么恭喜你成功了。

7.4、生成打包文件
到这一步就简单了,在/data/java/tools/hadoop-2.2.0-src/hadoop-dist/target/目录下,可以看到编译好的hadoop-2.2.0.tar.gz包静静的趴在那里,现在你可以进行安装了。
8、修改Hadoop的配置文件
7.1、修改Hadoop的hadoop-env.sh配置文件,设置jdk所在的路径:
![]()
找到JAVA_HOME,并设置为服务器JDK所在的绝对路径。
同时配置HADOOP_HOME,设置为服务器hadoop所在的绝对路径。
7.2、依次修改core-site.xml、yarn-site.xml、mapred-site.xml和hdfs-site.xml配置文件,主要分析core-site.xml与hdfs-site.xml配置信息。
Core-site.xml配置如下:
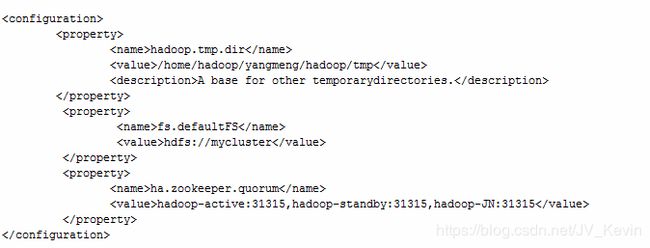
Hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多配置都依赖它。它默认的位置是在/tmp/{$user}下面,但是在/tmp路径下的存储是不安全的,因为linux一次重启,文件就可能被删除。所以建议配置该路径到持久化目录。
fs.defaultFS整个Federation集群对外提供服务的NS逻辑名称,这里的协议不再是hdfs,而是新引入的viewfs,这个逻辑名称会在下面的挂载表中用到。缺省文件服务的协议和NS逻辑名称,和hdfs-site里的对应,此配置替代了1.0里的fs.default.name。
Ha.zookeeper.quorum:”A list of ZooKeeper server addresses, separated by commas, that are to be used by the ZKFailoverController in automatic failover.”。配置三个Zookper节点,用于ZKFC故障转移。
hdfs-site.xml配置如下:

dfs.nameservices HDFS命名服务的逻辑名称,可用户自己定义,比如 mycluster,注意,该名称将被基于 HDFS 的系统使用,比如 Hbase 等,此外,需要你想启用 HDFS Federation,可以通过该参数指定多个逻辑名称,并用“,”分割。

dfs.ha.namenodes.[$nameserviceID] 命名服务下包含的NameNode列表,可为每个NN指定一个自定义的 ID 名称,比如命名服务mycluster下有两个NameNode,分别命名为 nn1 和 nn2。
注意,目前每个命名服务最多配置两个 NameNode
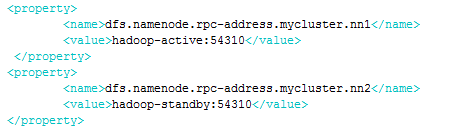
dfs.namenode.rpc-address.[$nameservice ID].[$name node ID] 为每个NN设置 RPC 地址。

这里面提到了两个RPC端口,分别是dfs.namenode.rpc-address和dfs.namenode.servicerpc-address。如果只配置dfs.namenode.rpc-address,那么NameNode-Client和NameNode-DataNode之间的RPC都走的是这个端口。如果配置了后者与前者不同,那么dfs.namenode.rpc-address表示的是NameNode-Client之间的RPC,而dfs.namenode.servicerpc-address表示的是NameNode-DataNode之间的RPC。之所以要区别开来,我想主要是因为datanode和namenode通讯时不会影响client和namenode的通讯,因为同一个端口同时打开的句柄毕竟是预先设定的,缺省为10个。

dfs.namenode.http-address.[$nameservice ID].[$name node ID] 为每个NN设置对外的 HTTP 地址

dfs.namenode.shared.edits.dir 设置一组journalNode的URI地址,active NameNode将edit log写入这些JournalNode,而standby NameNode读取这些edit log,并作用在内存中的目录树中,其中,journalId是该命名空间的唯一ID。假设你有三台journalNode,即node1.example.com, node2.example.com 和 node3.example.com,则可如上配置。

dfs.journalnode.edits.dir 设置journaldata的存储路径

dfs.client.failover.proxy.provider.[$nameservice ID]设置客户端与 active NameNode 进行交互的 Java 实现类,DFS 客户端通过该类寻找当前的active NameNode。该类可由用户自己实现,默认实现为 ConfiguredFailoverProxyProvider

dfs.ha.fencing.methods 主备架构解决单点故障问题时,必须要认真解决的是脑裂问题,即出现两个 master 同时对外提供服务,导致系统处于不一致状态,可能导致数据丢失等潜在问题。在 HDFS HA中,JournalNode 只允许一个 NameNode 写数据,不会出现两个 active NameNode 的问题,但是,当主备切换时,之前的 active NameNode 可能仍在处理客户端的 RPC 请求,为此,需要增加隔离机制(fencing)将之前的 active NameNode 杀死。
HDFS 允许用户配置多个隔离机制,当发生主备切换时,将顺次执行这些隔离机制,直到一个返回成功。Hadoop 2.0 内部打包了两种类型的隔离机制,分别是shell和sshfence。
这里配置sshfence
sshfence通过ssh登录到前一个active NameNode并将其杀死。为了让该机制成功执行,需配置免密码ssh登陆,这可通过参数dfs.ha.fencing.ssh.private-key-files设置一个私钥文件。

需要一些目录放置fsimage和edits,对应配置dfs.namenode.name.dir、dfs.namenode.edits.dir
需要指定一个目录来保存blocks,对应配置

dfs.replication确定data block的副本数目,hadoop基于rackawareness(机架感知)默认复制3份分block,(同一个rack下两个,另一个rack下一 份,按照最短距离确定具体所需block, 一般很少采用跨机架数据块,除非某个机架down了)。

这个是块大小的设置,也就是说文件按照多大的size来切分块。一般来说,块的大小也决定了你map的数量。举个例子:我现在有一个1T的文件,如果我的块size设置是默认的64M,那么在HDFS上产生的块将有1024000/64=16000块。
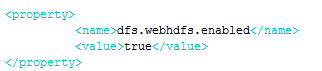
允许文件以rest形式被访问

dfs.permission是否开启文件权限验证,true开启,false不进行读写权限验证。(注:dfs.permission开启与否dfs permission信息都不会改变后丢失,chown、chgrp、chmod操作也始终会验证权限,dfspermission信息只在namenode里,并不在danode里与blocks关联)
yarn-site.xml配置如下:

mapred-site.xml配置如下:

Slaves配置如下:
配置好Hadoop的相关东西之后,请将hadoop-2.2.0整个文件夹分别拷贝到其他master和datanode主机上面去,设置都不需要改!
9、关闭防火墙
关闭防火墙
防火墙会影响外部对linux机器的访问,简单起见就直接关闭防火墙服务。
[hadoop@hadoop ~]$ sudo service iptables stop //停止防火墙服务
[hadoop@hadoop ~]sudo chkconfig --level 35 iptables off //永久关闭防火墙
关闭Selinux
Selinux会进行操作和访问限制,避免配置就直接关闭该功能。
[hadoop@hadoop ~]$ sudo vi /etc/sysconfig/selinux //编辑selinux配置文件
SELINUX=disabled #设置selinux禁用
10、查看Hadoop是否运行成功
启动JN:
- [hadoop@hadoop ~]$cd /usr/local/hadoop2.0/hadoop/sbin/; ./hadoop-daemon.sh start journalnode
格式化NameNode:
[hadoop@hadoop ~]$ hadoop namenode -format
格式化JN
[hadoop@hadoop ~]$ hadoop namenode -initializeSharedEdits
启动Zookeeper:
[hadoop@hadoop ~]$ zkServer.sh start
启动Hadoop:
[hadoop@hadoop ~]$ cd sbin ./star-dfs.sh
启动Yarn:
[hadoop@hadoop ~]$ cd sbin ./start-yarn.sh
启动Hbase:
[hadoop@hadoop ~]$ start-hbase.sh
集群方式启动Hive:
[hadoop@hadoop ~]$ hive:hive -hiveconf hbase.zookeeper.quorum=slave
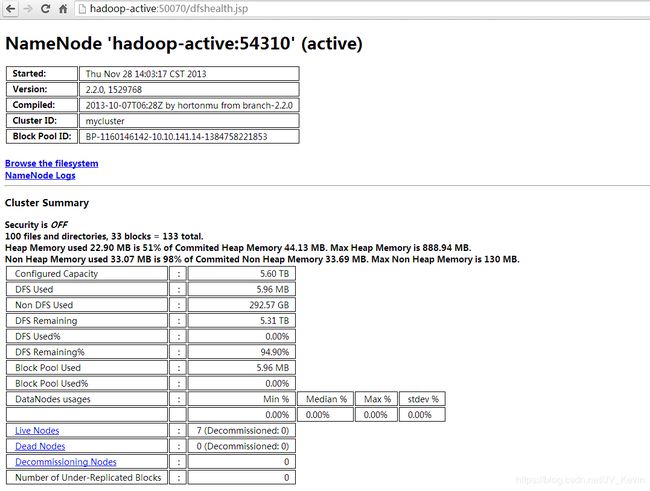
执行jps看是否启动成功,只有7个进程都启动了才对。

在 Web 界面上查看是否启动成功,如果界面显示如下(standby namenode 的界面),则启动成功: