Keras中实现神经网络的Stacking方法
Table of Contents
- 1. stack模型的一般集成方式
- 2. 分类任务的定义
- 3. 神经网络-多层感知器
- 4. 训练并保存模型
- 创建MLP模型并训练
- 创建存放模型的文件夹
- 创建MLP子模型并保存
- 5. 独立Stacking Model
- 载入子模型(sub-model)
- 训练元模型(meta-learner)
- 举例: 元模型=llogistic为例
- 6. 集成的stacking Model-神经网络嵌入神经网络模型的方式
1. stack模型的一般集成方式
平均集成模型联合来自不同训练模型的预测结果。
该方法的限制在于每个模型都输出相同的预测结果给集成预测集,没有考虑模型性能。该方法的一种变异,加权平均集成,它对每个ensemble成员中的权重,通过trust或expected模型在留出数据集上性能来衡量。
这使得性能好的模型权重高,性能差的模型权重低。加权平均集成的性能优于平均集成。
线性加权求和的模型是将任意子模型的结果联合起来,加权平均集成未来将会取代它。加权平均集成也称为stacked generalization或者stacking.
在stacking中,在子模型之上的模型算法通过将子模型结果作为训练集,原标签为目标变量,以求获得更好的拟合能力。
不妨将stacking过程理解成两层:level0和 level1。
- level0:level0数据集是原始数据集的训练数据,用于训练子模型,子模型输出预测结果;
- level1:level1数据集是将level0的预测结果作为训练数据,用于元模型训练,输出预测结果。
2. 分类任务的定义
数据集基本情况:
- 样本量:1000
- 特征:2
- 目标变量:数值型,3分类
make_blobs() function :指定采样量,输入变量,类标签等创建样本集。
from sklearn.datasets import make_blobs
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras.utils import to_categorical
from numpy import dstack
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
Using TensorFlow backend.
# generate 2d classification dataset
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
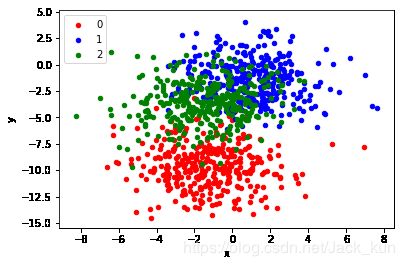
X, y = make_blobs(n_samples=1000, centers=3, n_features=2, cluster_std=2, random_state=2)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue', 2:'green'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()
3. 神经网络-多层感知器
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
y = to_categorical(y)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
(100, 2) (1000, 2)
keras的softmax报错:TypeError: softmax() got an unexpected keyword argument ‘axis’
方法:C:\ProgramData\Anaconda3\Lib\site-packages\keras\backend\tensorflow_backend.py中的3000多行的softmax函数的axis删除,在重新启动jupyter notebook
参考:
https://blog.csdn.net/czp_374/article/details/80647940
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3,activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=500, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
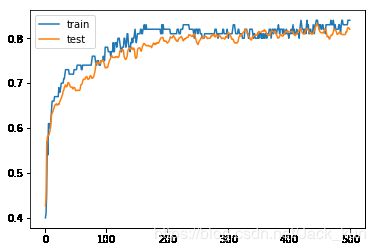
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
Train: 0.830, Test: 0.820
# learning curves of model accuracy
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
4. 训练并保存模型
创建MLP模型并训练
# fit model on dataset
def fit_model(trainX, trainy):
# define model
model = Sequential()
model.add(Dense(25, input_dim=2, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
model.fit(trainX, trainy, epochs=500, verbose=0)
return model
创建存放模型的文件夹
# create directory for models
import os
os.makedirs('tmp_models')
创建MLP子模型并保存
# fit and save models
n_members = 5
for i in range(n_members):
# fit model
model = fit_model(trainX, trainy)
# save model
filename = 'tmp_models/model_' + str(i + 1) + '.h5'
model.save(filename)
print('>Saved %s' % filename)
>Saved tmp_models/model_1.h5
>Saved tmp_models/model_2.h5
>Saved tmp_models/model_3.h5
>Saved tmp_models/model_4.h5
>Saved tmp_models/model_5.h5
5. 独立Stacking Model
载入子模型(sub-model)
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'tmp_models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
>loaded tmp_models/model_1.h5
>loaded tmp_models/model_2.h5
>loaded tmp_models/model_3.h5
>loaded tmp_models/model_4.h5
>loaded tmp_models/model_5.h5
Loaded 5 models
testy_enc
array([[[ 0., 1.],
[ 1., 0.],
[ 1., 0.]],
[[ 1., 0.],
[ 1., 0.],
[ 0., 1.]],
[[ 1., 0.],
[ 1., 0.],
[ 0., 1.]],
...,
[[ 1., 0.],
[ 0., 1.],
[ 1., 0.]],
[[ 0., 1.],
[ 1., 0.],
[ 1., 0.]],
[[ 1., 0.],
[ 1., 0.],
[ 0., 1.]]], dtype=float32)
print(testX.shape,testy_enc.shape,trainX.shape, testy.shape, trainy.shape)
(1000, 2) (1000, 3, 2) (100, 2) (1000, 3) (100, 3)
members[0].evaluate(testX, testy)
1000/1000 [==============================] - 1s 570us/step
[0.4565311725139618, 0.81399999999999995]
# evaluate standalone models on test dataset
for model in members:
# testy_enc = to_categorical(testy)
_, acc = model.evaluate(testX, testy, verbose=0)
print('Model Accuracy: %.3f' % acc)
Model Accuracy: 0.814
Model Accuracy: 0.799
Model Accuracy: 0.810
Model Accuracy: 0.807
Model Accuracy: 0.809
训练元模型(meta-learner)
# create stacked model input dataset as outputs from the ensemble
def stacked_dataset(members, inputX):
stackX = None
for model in members:
# make prediction
yhat = model.predict(inputX, verbose=0)
# stack predictions into [rows, members, probabilities]
if stackX is None:
stackX = yhat
else:
stackX = dstack((stackX, yhat))
# flatten predictions to [rows, members x probabilities]
stackX = stackX.reshape((stackX.shape[0], stackX.shape[1]*stackX.shape[2]))
return stackX
举例: 元模型=llogistic为例
第一层模型是各个神经网络
第二层模型是logistic
def fit_stacked_model(members, inputX, inputy):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# fit standalone model
model = LogisticRegression()
model.fit(stackedX, inputy)
return model
testy3 = np.sum(testy, axis=1)
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# one hot encode output variable
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# fit stacked model using the ensemble
model = fit_stacked_model(members, testX, testy2)
# make a prediction with the stacked model
def stacked_prediction(members, model, inputX):
# create dataset using ensemble
stackedX = stacked_dataset(members, inputX)
# make a prediction
yhat = model.predict(stackedX)
return yhat
# evaluate model on test set
yhat = stacked_prediction(members, model, testX)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Stacked Test Accuracy: 0.823
6. 集成的stacking Model-神经网络嵌入神经网络模型的方式
第一层模型是神经网络
第二层模型是神经网络
# stacked generalization with neural net meta model on blobs dataset
from sklearn.datasets.samples_generator import make_blobs
from sklearn.metrics import accuracy_score
from keras.models import load_model
from keras.utils import to_categorical
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers.merge import concatenate
from numpy import argmax
# load models from file
def load_all_models(n_models):
all_models = list()
for i in range(n_models):
# define filename for this ensemble
filename = 'tmp_models/model_' + str(i + 1) + '.h5'
# load model from file
model = load_model(filename)
# add to list of members
all_models.append(model)
print('>loaded %s' % filename)
return all_models
# define stacked model from multiple member input models
def define_stacked_model(members):
# update all layers in all models to not be trainable
for i in range(len(members)):
model = members[i]
for layer in model.layers: # 对原已训练好的模型model,冻结所有layer不再参加训练,
# make not trainable
layer.trainable = False
# rename to avoid 'unique layer name' issue
layer.name = 'ensemble_' + str(i+1) + '_' + layer.name
# define multi-headed input
ensemble_visible = [model.input for model in members] # 获取n个原模型的input张量
# concatenate merge output from each model
ensemble_outputs = [model.output for model in members] # 获取n个原模型的output张量
merge = concatenate(ensemble_outputs) # 披了外壳的tf.concat()。参考:https://blog.csdn.net/leviopku/article/details/82380710
hidden = Dense(10, activation='relu')(merge)
output = Dense(3, activation='softmax')(hidden)
model = Model(inputs=ensemble_visible, outputs=output)
# plot graph of ensemble
plot_model(model, show_shapes=True, to_file='model_graph.png')
# compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# fit a stacked model
def fit_stacked_model(model, inputX, inputy):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# encode output data
inputy_enc = to_categorical(inputy)
# fit model
model.fit(X, inputy_enc, epochs=300, verbose=0)
# make a prediction with a stacked model
def predict_stacked_model(model, inputX):
# prepare input data
X = [inputX for _ in range(len(model.input))]
# make prediction
return model.predict(X, verbose=0)
# generate 2d classification dataset
X, y = make_blobs(n_samples=1100, centers=3, n_features=2, cluster_std=2, random_state=2)
# split into train and test
n_train = 100
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
print(trainX.shape, testX.shape)
# load all models
n_members = 5
members = load_all_models(n_members)
print('Loaded %d models' % len(members))
# define ensemble model
stacked_model = define_stacked_model(members)
# fit stacked model on test dataset
fit_stacked_model(stacked_model, testX, testy)
# make predictions and evaluate
yhat = predict_stacked_model(stacked_model, testX)
yhat = argmax(yhat, axis=1)
acc = accuracy_score(testy, yhat)
print('Stacked Test Accuracy: %.3f' % acc)
Using TensorFlow backend.
(100, 2) (1000, 2)
>loaded tmp_models/model_1.h5
>loaded tmp_models/model_2.h5
>loaded tmp_models/model_3.h5
>loaded tmp_models/model_4.h5
>loaded tmp_models/model_5.h5
Loaded 5 models
Stacked Test Accuracy: 0.832
原文链接:
How to Develop a Stacking Ensemble for Deep Learning Neural Networks in Python With Keras