Hive的DDL
DDL: Data Definition Language
create delete drop alter 关键字开头的

- Database
HDFS上的一个文件夹
默认自带一个default数据库
默认数据库存放位置:/user/hive/warehouse
位置是由参数决定的:hive.metastore.warehouse.dir
在Hive里面查看指定配置参数的语法:
set key;
你要设置参数: set key=value;


2.创建数据库
模版: CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
例子: CREATE DATABASE IF NOT EXISTS d5_hive_2
COMMENT ‘this is ruozedata d5’
WITH DBPROPERTIES (‘creator’=‘ruoze’, ‘date’=‘20181020’);

看一个数据库的内容desc database extended d5_hive_2;

简单的创建一个数据库
create database d5_hive;
create database if not exists d5_hive;(不会创建重复的数据库)即有了就不会创建,没有才创建,比较完备
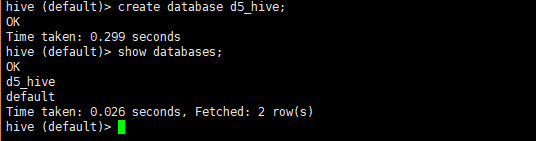
非default的存放路径:${hive.metastore.warehouse.dir}/dbname.db
default是系统默认的一个数据库

模糊匹配
有三个数据库
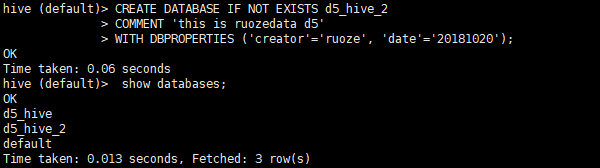
show databases like ‘d5*’;
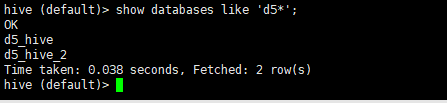
切库

3.修改数据库
模版:ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, …); – (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; – (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; – (Note: Hive 2.2.1, 2.4.0 and later)
例子:alter database d5_hive_2 set dbproperties (‘edited-by’=‘jepson’);

删除数据库
drop database d5_hive_2;
drop database if exists d5_hive_2;(比较完备)
删除一个空的数据库
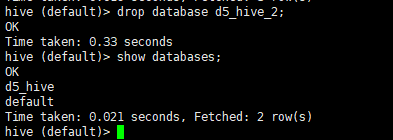
但是一个数据库里有表,表里有分区,上面的操作就不行了
drop database d5_hive_2 cascade;
注意,cascade慎用
cascade: hibernate/jpa
1对多的时候,你删除1的一端是否删除多的一端
数值类型:int bigint float double
字符串: string
Hive构建在Hadoop之上
hive创建表,然后数据是存储在HDFS之上
文件:zhangsan,20,m,beijing
表: name age gender location
所以创建表的时候要指定分隔符(默认分隔符是\001 ^A)
空格、制表符(\t)
创建表
模版:
CREATE TABLE table_name (
col_name data_type,
col_name data_type,
col_name data_type
…
)
row format delimited fields terminated by ‘\t’
;
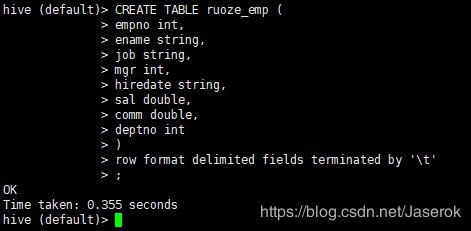
例子:
CREATE TABLE ruoze_emp (
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by ‘\t’
;

看表结构(内容)
desc ruoze_emp;

看表的详细内容
desc formatted ruoze_emp;


创建一张新的表,只要表的表结构不要数据
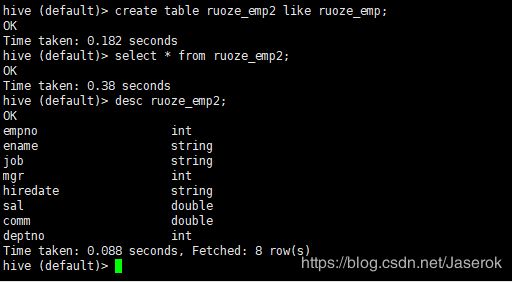
创建一张新的表,要表结构和表数据
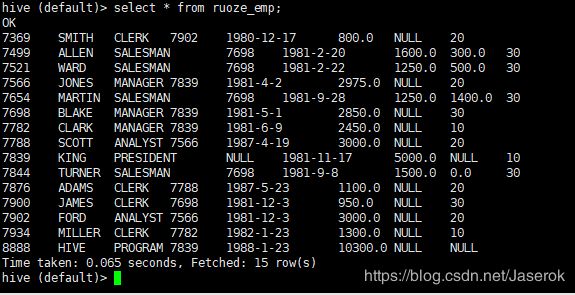
create table ruoze_emp3 as select *from ruoze_emp;


补充:导数据(DML内容)
load data local inpath ‘/home/hadoop/data/emp.txt’ overwrite into table ruoze_emp;(从本地导数据(linux))
load data inpath ‘/home/hadoop/data/emp.txt’ overwrite into table ruoze_emp;(表示从hdfs上导数据。注意:并且只能导一次,相当于mv.(移动))

修改表


#补充
1在hive中把数据用sql语句导到本地
INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/ruoze’
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
SELECT empno,ename FROM ruoze _emp;
2导到hdfs
INSERT OVERWRITE DIRECTORY ‘/tmp/ruoze’
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
SELECT empno,ename FROM ruoze _emp;