简单的漫画爬虫,python爬虫实战
因为某些众所周知的原因,有些漫画在大网站上看不到了。然后小网站上体验较差又没有更新提醒,每次都要打开看有没有更新,有些不方便。闲来无事就写了个爬虫。再闲来无事写个教程好了,就当是回报各大python博主的教导,嘿嘿。
准备工具
python 3.6.3、mysql、chrome浏览器
相关知识
python、html、正则表达式、xpath、爬虫相关库
步骤:
1、分析网站结构,找出所需信息的位置
以该网址为例:http://comic.kukudm.com/comiclist/941/
F12召唤控制台,选中漫画记录的页面元素,看代码发现每话漫画的页面是在id为comlistn的dl中的dd里面,其中a的href属性就包含漫画网址。

2、获取最新的漫画记录
只是为了追更,那就只要获取dl中最后一个dd就好了。
关键代码如下,这里使用了urllib、lxml、xpath,注意保存漫画名的编码
res = urllib.request.urlopen(comicurl)
html = res.read().decode('gbk', 'ignore').encode('utf-8').decode()
# print(html)
html = etree.HTML(html)
dd_s = html.xpath('//*[@id="comiclistn"]/dd')
for i in range(len(dd_s)-1,0,-1) :
a_s = dd_s[i].findall('a')
print(a_s[0].tag, a_s[0].attrib)
nowurl = "http://comic3.kukudm.com" + a_s[0].get('href')
nowtitle = a_s[0].text.replace(' ','')
nowurl = nowurl.encode('utf-8').decode()
nowtitle = nowtitle.encode('utf-8').decode()
print(nowurl)
print(nowtitle)
3、把更新的漫画记录存入数据库
因为要知道抓取到的漫画记录是不是更新了,所以每次都要保存漫画记录。为此建了两张表。一个是要抓取的漫画的网页kukumanhualist。一个是漫画记录kukumanhuarecord。


结构如下(好像暴露了什么):
关键代码如下:
try:
if cursor.execute("SELECT * FROM kukumanhuarecord WHERE comicName='%s' AND recordUrl='%s'" % (comicname,nowurl)) == 1 :
print("有该漫画记录")
break
else:
print("没有该漫画记录")
try:
insertsql = "INSERT INTO kukumanhuarecord VALUES ('%s','%s','%s','%s',%d)" % (
comicname, nowurl, nowtitle, today, 0)
print(insertsql)
cursor.execute(insertsql)
db.commit()
print("插入成功")
except Exception as err:
print(err)
db.rollback()
print("插入失败")
except Exception as err:
print(err)
print("查询记录失败")以上两步作为抓取漫画记录页面的完整的功能实现保存为一个py文件
完整代码如下:
import urllib.request
from lxml import etree
import time
import pymysql
if __name__ == '__main__':
today = time.strftime("%Y-%m-%d", time.localtime())
print(today)
db = pymysql.connect("localhost","root","","myspyder",use_unicode=True, charset="utf8")
cursor = db.cursor()
cursor.execute("SELECT * FROM kukumanhualist")
comic_list = cursor.fetchall()
for row in comic_list:
print(row)
comicname = row[0]
comicname = comicname.encode('utf-8').decode()
print(comicname)
comicurl = row[1]
res = urllib.request.urlopen(comicurl)
html = res.read().decode('gbk', 'ignore').encode('utf-8').decode()
# print(html)
html = etree.HTML(html)
dd_s = html.xpath('//*[@id="comiclistn"]/dd')
for i in range(len(dd_s)-1,0,-1) :
a_s = dd_s[i].findall('a')
print(a_s[0].tag, a_s[0].attrib)
nowurl = "http://comic3.kukudm.com" + a_s[0].get('href')
nowtitle = a_s[0].text.replace(' ','')
nowurl = nowurl.encode('utf-8').decode()
nowtitle = nowtitle.encode('utf-8').decode()
print(nowurl)
print(nowtitle)
try:
if cursor.execute("SELECT * FROM kukumanhuarecord WHERE comicName='%s' AND recordUrl='%s'" % (comicname,nowurl)) == 1 :
print("有该漫画记录")
break
else:
print("没有该漫画记录")
try:
insertsql = "INSERT INTO kukumanhuarecord VALUES ('%s','%s','%s','%s',%d)" % (
comicname, nowurl, nowtitle, today, 0)
print(insertsql)
cursor.execute(insertsql)
db.commit()
print("插入成功")
except Exception as err:
print(err)
db.rollback()
print("插入失败")
except Exception as err:
print(err)
print("查询记录失败")
4、根据最新漫画记录的网址抓取漫画图片
前面的代码在kukumanhuarecord生成了recordStatus为0(即未抓取图片)的漫画记录。现在根据漫画记录的url去页面抓取图片。
页面分析发现,很好,漫画的每一页就是修改url最后的页数.htm就好了,很方便逐页抓取。同第二步,找出每页中包含图片的元素。
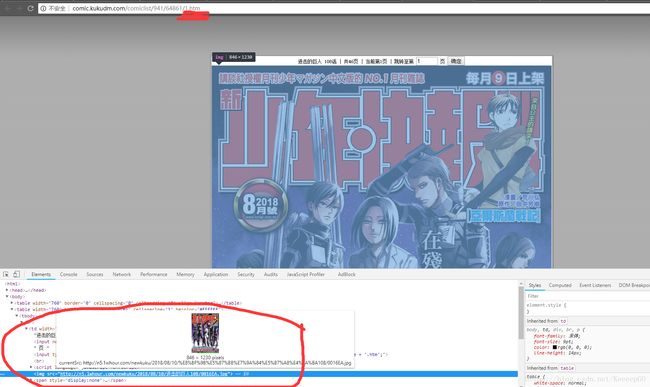
完整代码如下,这里使用了request、re:
import os
import pandas as pd
import requests
import time
import re
import pymysql
if __name__ == "__main__":
db = pymysql.connect("localhost","root","","myspyder",use_unicode=True, charset="utf8")
cursor = db.cursor()
cursor.execute("SELECT * FROM kukumanhuarecord WHERE recordStatus=0")
record_list = cursor.fetchall()
if len(record_list) == 0 :
print("没有要更新的漫画")
cwd = os.getcwd()
for row in record_list:
sql = "UPDATE kukumanhuarecord SET recordStatus=1 WHERE recordUrl='%s'" % (row[1])
cursor.execute(sql)
print(sql)
comicdir = "\\" + row[0] + "\\" + re.search('\d+', row[2]).group()
try:
os.makedirs(cwd + comicdir)
except Exception as err:
print(err)
continue
os.chdir(cwd + comicdir)
now_page_url = row[1]
print(now_page_url)
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'}
res = requests.get(now_page_url, headers=headers)
pattern = re.compile(r'/\d+\.htm')
t = pattern.search(now_page_url).span()[0]
print(t)
print(now_page_url[t])
i = 0
while True:
i += 1
tt = list(now_page_url)
if i > 10:
tt[t+2] = ''
tt[t+1] = str(i)
else:
tt[t+1] = str(i)
now_page_url = ''.join(tt)
print(now_page_url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
res = requests.get(now_page_url, headers=headers)
if res.status_code == 404:
print(res.status_code)
break
if i == 48:
print(i)
break
print(res)
html = res.content.decode('gbk', 'ignore').encode('utf-8').decode()
# print(html)
match_url = re.search('newkuku(\S)+jpg',html)
print(match_url.group())
img_link = 'http://n5.1whour.com/' + match_url.group()
path = '~/comic/'+'.jpg'
imgpage = requests.get(img_link, headers=headers)
#获取图片的名字方便命名
file_name = str(i)+'.jpg'
#图片不是文本文件,以二进制格式写入,所以是html.content
f = open(file_name,'wb')
f.write(imgpage.content)
f.close()
db.commit()
db.close()5、使用命令行并保存为批处理文件
每次要用都要打开命令行输
python get_kukumanhuarecord.py
python get_kukumanhuaimgs.py
好麻烦啊.然后百度了一下可以保存为批处理文件就可以了.具体做法就是写个txt文件把命令写进去,再修改后缀名为bat,就可以双击运行命令了。记得要末尾要加个pause,就可以暂停看print的信息和报错了。

第一次写教程,有所欠缺的地方欢迎指教,谢谢。