Kubernetes集群的监控报警策略最佳实践
本文为Kubernetes监控系列的第二篇文章,系列目录如下:
Kubernetes监控开源工具基本介绍以及如何使用Sysdig进行监控
Kubernetes集群的监控报警策略最佳实践(本篇)
Kubernetes中的服务发现与故障排除(敬请期待)
Docker与Kubernetes在WayBlazer的使用案例(敬请期待)
监控是每个优质基础设施的基础,是达到可靠性层次的基础。监控有助于减少对突发事件的响应时间,实现对系统问题的检测、故障排除和调试。在基础设施高度动态的云时代,监控也是容量规划的基础。
有效的警报是监控策略的基石。当你转向容器和Kubernetes编排环境,你的警报策略也需要演进。正是因为以下几个核心原因,其中许多我们在" 如何监视Kubernetes"中进行了讲述:
可见性:容器是一个黑盒。传统工具只能针对公共监控端点进行检查。如果想深入监控相关服务,则需要采取不一样的方法。
新的基础架构层:现在服务和主机之间有一个新的层:容器和容器编排服务。这些是你需要监控的新内部服务,你的监控系统需要了解这些服务。
动态重调度:容器没有像之前那样的服务节点,所以传统的监控不能有效地工作。没有获取服务度量标准的静态端点,没有运行服务实例的静态数量(设想一个金丝雀发布或自动伸缩设置)。在某节点中一个进程被kill是正常的,因为它有很大的机会被重新调度到基础设施的其他节点。
元数据和标签:随着服务跨多个容器,为所有这些服务添加系统级别的监控以及服务特定的度量标准,再加上Kubernetes带来的所有新服务,如何让所有这些信息对我们有所帮助?有时你希望看到分布在不同节点容器中的服务的网络请求度量,有时你希望看到特定节点中所有容器的相同度量,而不关心它们属于哪个服务。这就需要一个多维度量系统,需要从不同的角度来看待这些指标。如果通过Kubernetes中存在的不同标签自动标记度量标准,并且监控系统能够了解Kubernetes元数据,那么只需要在每种情况下按照需要聚合和分割度量标准就可以实现多维度度量。
考虑到这些问题,让我们创建一组对Kubernetes环境至关重要的报警策略。我们的Kubernetes报警策略教程将涵盖:
应用程序层度量标准的报警
Kubernetes上运行的服务的报警
Kubernetes基础设施的报警
在主机/节点层上的报警
最后我们还将通过检测系统调用问题来了解如何通过报警加速故障排除。
![]()
以下示例是一个公共REST API端点监控警报,监控prod命令空间中的名为javaapp的deployment,在10分钟内如果延迟超过1秒则报警。
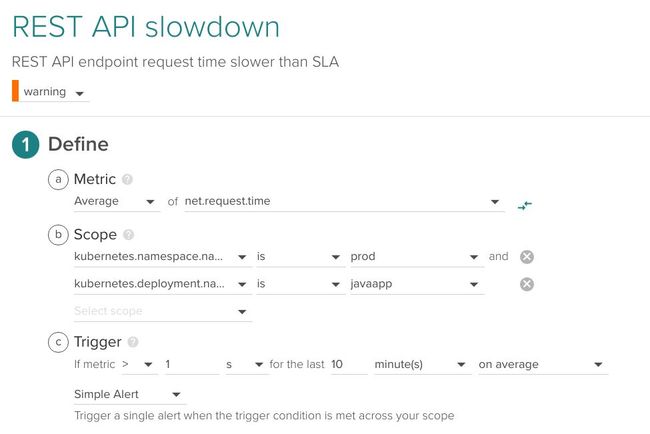
所有这些报警高度依赖于应用程序、工作负载模式等等,但真正的问题是如何在所有服务中一致性地获取数据。在理想环境中,除了核心监控工具之外,无需再购买综合监控服务即可获得这一套关键指标。
这个类别中经常出现的一些指标和报警是:
服务相应时间
服务可用性
SLA合规性
每秒请求的成功/失败数
![]()
没错,如果想知道服务的全局运行和执行情况,就需要利用监视工具功能根据容器元数据将度量标准进行聚合和分段。
如 第一篇文章所述,Kubernetes将容器标记为一个deployment或者通过一个service进行暴露,在定义报警时就需要考虑这些因素,例如针对生产环境的报警(可能通过命名空间进行定义)。
以下是Cassandra集群的示例:

如果我们在Kubernetes、AWS EC2或OpenStack中运行Cassandra,则衡量指标cassandra.compactions.pending存在每个实例上,但是现在我们要查看在prod命名空间内的cassandra复制控制器中聚合的指标。这两个标签都来自Kubernetes,但我们也可以更改范围,包括来自AWS或其他云提供商的标签,例如可用区域。
这个类别中经常出现的一些指标和警报是:
HTTP请求数
数据库连接数、副本数
线程数、文件描述符数、连接数
中间件特定指标:Python uwsgi worker数量,JVM堆大小等
另外,如果正在使用外部托管服务,则很可能需要从这些提供程序导入度量标准,因为它们可能还有需要做出反应的事件。
![]()
由Kubernetes处理的服务
1.1 是否有足够的Pod/Container给每个应用程序运行?
Kubernetes可以通过Deployments、Replica Sets和Replication Controllers来处理具有多个Pod的应用程序。它们之间区别比较小,可以使用它们来维护运行相同应用程序的多个实例。运行实例的数量可以动态地进行伸缩,甚至可以通过自动缩放来实现自动化。
运行容器数量可能发生变化的原因有多种:因为节点失败或资源不足将容器重新调度到不同主机或者进行新版本的滚动部署等。如果在延长的时间段内运行的副本数或实例的数量低于我们所需的副本数,则表示某些组件工作不正常(缺少足够的节点或资源、Kubernetes或Docker Engine故障、Docker镜像损坏等等)。
在Kubernetes部署服务中,跨多个服务进行如下报警策略对比是非常有必要的:
timeAvg(kubernetes.replicaSet.replicas.running) < timeAvg(kubernetes.replicaSet.replicas.desired)
正如之前所说,在重新调度与迁移过程运行中的实例副本数少于预期是可接受的,所以对每个容器需要关注配置项 .spec.minReadySeconds (表示容器从启动到可用状态的时间)。你可能也需要检查 .spec.strategy.rollingUpdate.maxUnavailable 配置项,它定义了在滚动部署期间有多少容器可以处于不可用状态。
下面是上述报警策略的一个示例,在 wordpress 命名空间中集群 kubernetes-dev 的一个deployment wordpress-wordpress。

1.2 是否有给定应用程序的任何Pod/Container?
与之前的警报类似,但具有更高的优先级(例如,这个应用程序是半夜获取页面的备选对象),将提醒是否没有为给定应用程序运行容器。
以下示例,在相同的deployment中增加警报,但不同的是1分钟内运行Pod <1时触发:

1.3 重启循环中是否有任何Pod/Container?
在部署新版本时,如果没有足够的可用资源,或者只是某些需求或依赖关系不存在,容器或Pod最终可能会在循环中持续重新启动。这种情况称为“CrashLoopBackOff”。发生这种情况时,Pod永远不会进入就绪状态,从而被视为不可用,并且不会处于运行状态,因此,这种场景已被报警覆盖。尽管如此,笔者仍希望设置一个警报,以便在整个基础架构中捕捉到这种行为,立即了解具体问题。这不是那种中断睡眠的报警,但会有不少有用的信息。
这是在整个基础架构中应用的一个示例,在过去的2分钟内检测到4次以上的重新启动:

监控Kubernetes系统服务
除了确保Kubernetes能正常完成其工作之外,我们还希望监测Kubernetes的内部健康状况。这将取决于Kubernetes集群安装的不同组件,因为这些可能会根据不同部署选择而改变,但有一些基本组件是相同的。
2.1 etcd是否正常运行?
etcd是Kubernetes的分布式服务发现、通信、命令通道。监控etcd可以像监控任何分布式键值数据库一样深入,但会使事情变得简单。
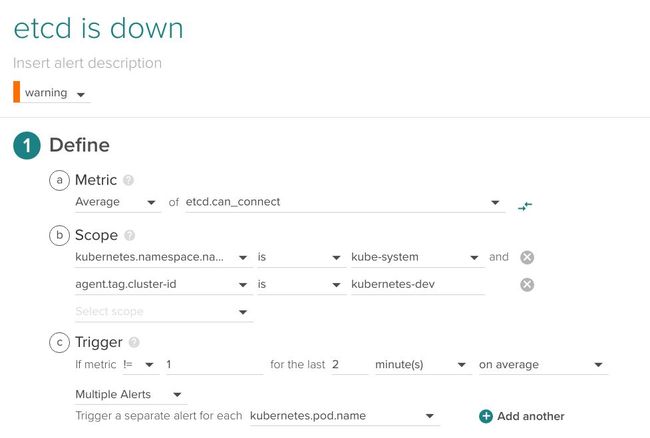
我们可以进一步去监控设置命令失败或者节点数,但是我们将会把它留给未来的etcd监控文章来描述。
2.2 集群中有足够的节点吗?
节点故障在Kubernetes中不是问题,调度程序将在其他可用节点中生成容器。但是,如果我们耗尽节点呢?或者已部署的应用程序的资源需求超过了现有节点?或者我们达到配额限制?
在这种情况下发出警报并不容易,因为这取决于你想要在待机状态下有多少个节点,或者你想要在现有节点上推送多少超额配置。可以使用监控度量值kube_node_status_ready和kube_node_spec_unschedulable进行节点状态警报。
如果要进行容量级别报警,则必须将每个已调度Pod请求的CPU和memory进行累加,然后检查是否会覆盖每个节点,使用监控度量值kube_node_status_capacity_cpu_cores和kube_node_status_capacity_memory_bytes。
在主机/节点层上的报警
![]()
主要区别是现在警报的严重程度。在此之前,系统服务宕机可能意味着你的应用程序停止运行并且要紧急处理事故(禁止有效的高可用性)。而对于Kubernetes来说当服务发生异常,服务可以在主机之间移动,主机警报不应该不受重视。
让我们看看我们应该考虑的几个方面:
1. 主机宕机
如果主机停机或无法访问,我们希望收到通知。我们将在整个基础架构中应用此单一警报。我们打算给它一个5分钟的等待时间,因为我们不想看到网络连接问题上的嘈杂警报。你可能希望将其降低到1或2分钟,具体取决于你希望接收通知的速度。

2. 磁盘利用率
这是稍微复杂一些的警报。我们在整个基础架构的所有文件系统中应用此警报。我们将范围设置为 everywhere,并针对每个 fs.mountDir 设置单独的评估/警报。
以下是超过80%使用率的通用警报,但你可能需要不同的策略,如具有更高阈值(95%)或不同阈值的更高优先级警报(具体取决于文件系统)。
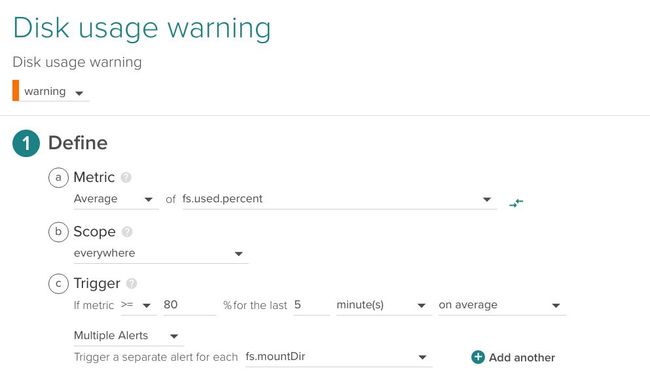
如果要为不同的服务或主机创建不同的阈值,只需更改要应用特定阈值的范围。
3. 一些其他资源
此类别中的常见资源是有关负载、CPU使用率、内存和交换空间使用情况的警报。如果在一定的时间内这些数据中的任何一个显著提升,可能就需要警报提醒您。我们需要在阈值、等待时间以及如何判定噪声警报之间进行折中。
如果您想为这些资源设置指标,请参考以下指标:
负载:load.average.1m, load.average.5m 和 load.average.15m
CPU:cpu.used.percent
memory:memory.used.percent 或 memory.bytes.used
swap:memory.swap.used.percent 或 memory.swap.bytes.used
一些人同样使用这个类别监控他们部分基础架构所在云服务提供商的资源。
![]()
但是如果一些更棘手的问题出现在我们面前,我们可以看到我们拥有的所有武器:提供者状态页面、日志(希望来自中心位置)、任何形式的APM或分布式追踪(如果开发人员安装了代码或者外部综合监测)。然后,我们祈祷这一事件在这些地方留下了一些线索,以便我们可以追溯到问题出现的多种来源原因。
我们怎么能够在警报被解除时自动dump所有系统调用?系统调用是所发生事情的真实来源,并将包含我们可以获得的所有信息。通过系统调用有可能发现触发警报的根本问题所在。Sysdig Monitor允许在警报触发时自动开始捕获所有系统调用。
例如,可以配置CrashLoopBackOff场景:

只有当你安装代码后,Sysdig Monitor代理才能从系统调用拦截中计算出来相应的指标。考虑HTTP响应时间或SQL响应时间。Sysdig Monitor代理程序在套接字上捕获read()和write()系统调用,解码应用程序协议并计算转发到我们时间序列数据库中的指标。这样做的好处是可以在不触及开发人员代码的情况下获得仪表盘数据和警报:
![]()
能够利用Kubernetes和云服务提供商的元数据信息来汇总和细分监控指标和警报将成为多层次有效监控的必要条件。我们已经看到如何使用标签来更新我们已有的警报或创建Kubernetes上所需的新警报。
接下来,让我们看看在Kubernetes编排环境中的典型服务发现故障排除的挑战。
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.588235294117647" data-w="432" data-src="http://v.qq.com/iframe/player.html?vid=s06032nah0m&width=651&height=366.1875&auto=0" style="display: block; width: 651px !important; height: 366.1875px !important;" width="651" height="366.1875" data-vh="366.1875" data-vw="651" src="http://v.qq.com/iframe/player.html?vid=s06032nah0m&width=651&height=366.1875&auto=0"/>
原文链接:https://sysdig.com/blog/alerting-kubernetes/
深入浅出Kubernetes及企业AI平台落地实践培训
![]()

4月20日正式上课,点击阅读原文链接即可报名。