机器学习/深度学习入门:VGGNet模型实现
VGGNet:ILSVRC2014年亚军
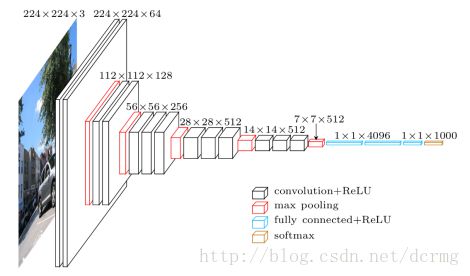

改进
(1)通过不断加深网络结构来提升性能。网络层数的增长并不会带来参数量上的爆炸,因为参数量主要集中在最后三个全连接层中。
(2)在 AlexNet 基础上将单层网络替换为堆叠的3*3的卷积层和2*2的最大池化层,减少卷积层参数,同时加深网络结构提高性能(两个3*3卷积层的串联相当于1个5*5的卷积层,3个3*3的卷积层串联相当于1个7*7的卷积层,即3个3*3卷积层的感受野大小相当于1个7*7的卷积层。但是3个3*3的卷积层参数量只有7*7的一半左右,同时前者可以有3个非线性操作,而后者只有1个非线性操作,这样使得前者对于特征的学习能力更强,同时证明虽然1*1的卷积也是很有效的,但是没有3*3的卷积效果好,因为3*3的网络可以学习到更大的空间特征);
(3)采用 Pre-trained 方法利用浅层网络(A)训练参数初始化深层网络参数(D,E),加速收敛;
(4)采用 Multi-Scale 方法进行数据增强、训练、测试,提高准确率。将原始图像缩放到不同尺寸 S,然后再随机裁切224´224的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令 S 在[256,512]这个区间内取值,使用 Multi-Scale 获得多个版本的数据,并将多个版本的数据合在一起进行训练。
(5)去掉了 LRN,减少了内存的小消耗和计算时间。
TensorFlow实现
网络结构如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 19-2-26 上午12:31
# @Author : HJH
# @Site :
# @File : temp.py
# @Software: PyCharm
import tensorflow as tf
import numpy as np
class VGGNet(object):
def __init__(self, num_classes=1000, dropout_keep_prob=0.5):
self.num_classes = num_classes
self.dropout_keep_prob = dropout_keep_prob
def inference(self, x, training=False):
conv1_1 = conv(x, 3, 3, 64, 1, 1, 'conv1_1')
conv1_2 = conv(conv1_1, 3, 3, 64, 1, 1, 'conv1_2')
pool1 = pool(conv1_2, 2, 2, 2, 2, name='pool1')
conv2_1 = conv(pool1, 3, 3, 128, 1, 1, 'conv2_1')
conv2_2 = conv(conv2_1, 3, 3, 128, 1, 1, 'conv2_1')
pool2 = pool(conv2_2, 2, 2, 2, 2, name='pool2')
conv3_1 = conv(pool2, 3, 3, 256, 1, 1, 'conv3_1')
conv3_2 = conv(conv3_1, 3, 3, 256, 1, 1, 'conv3_2')
conv3_3 = conv(conv3_2, 3, 3, 256, 1, 1, 'conv3_3')
pool3 = pool(conv3_3, 2, 2, 2, 2, name='pool3')
conv4_1 = conv(pool3, 3, 3, 512, 1, 1, 'conv4_1')
conv4_2 = conv(conv4_1, 3, 3, 512, 1, 1, 'conv4_2')
conv4_3 = conv(conv4_2, 3, 3, 512, 1, 1, 'conv4_3')
pool4 = pool(conv4_3, 2, 2, 2, 2, name='pool4')
conv5_1 = conv(pool4, 3, 3, 512, 1, 1, 'conv5_1')
conv5_2 = conv(conv5_1, 3, 3, 512, 1, 1, 'conv5_2')
conv5_3 = conv(conv5_2, 3, 3, 512, 1, 1, 'conv5_3')
pool5 = pool(conv5_3, 2, 2, 2, 2, name='pool5')
shape = int(np.prod(pool5.get_shape()[1:]))
pool5_flat = tf.reshape(pool5, [-1, shape])
fc6 = fc(pool5_flat, shape, 4096, 'fc6', training=training, dropout_keep_prob=self.dropout_keep_prob)
fc7 = fc(fc6, 4096, 4096, 'fc7', training=training, dropout_keep_prob=self.dropout_keep_prob)
self.fc8 = fc(fc7, 4096, self.num_classes, 'fc8', training=training, relu=False)
return self.fc8
def loss(self, batch_x, batch_y=None):
y_predict = self.inference(batch_x, training=True)
self.loss = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=batch_y, labels=y_predict))
return self.loss
def optimize(self, learning_rate, train_layers=[]):
var_list = [v for v in tf.trainable_variables() if v.name.split('/')[0] in train_layers]
return tf.train.AdamOptimizer(learning_rate).minimize(self.loss, var_list=var_list)
def load_original_weights(self, session, skip_layer=[]):
weights = np.load('vgg16_weights.npz')
keys = sorted(weights.keys())
for i, name in enumerate(keys):
parts = name.split('_')
layer = '_'.join(parts[:-1])
if layer == 'fc8' and self.num_classes != 1000:
continue
with tf.variable_scope(layer, reuse=True):
if parts[-1] == 'W':
var = tf.get_variable('weights')
session.run(var.assign(weights[name]))
elif parts[-1] == 'b':
var = tf.get_variable('biases')
session.run(var.assign(weights[name]))
def conv(x, filter_height, filter_width, num_filters, stride_y, stride_x, name, padding='SAME'):
with tf.variable_scope(name) as scope:
input_channels = int(x.get_shape()[-1])
kernel = tf.get_variable('weights', initializer=tf.truncated_normal(
[filter_height, filter_width, input_channels, num_filters], dtype=tf.float32, stddev=1e-1))
biases = tf.get_variable('biases', initializer=tf.constant(0.0, shape=[num_filters], dtype=tf.float32))
conv = tf.nn.conv2d(x, kernel, [1, stride_y, stride_x, 1], padding=padding)
add_bias = tf.nn.bias_add(conv, biases)
out = tf.nn.relu(add_bias, name=scope.name)
return out
def pool(x, filter_height, filter_width, stride_y, stride_x, name, padding='SAME'):
return tf.nn.max_pool(x, ksize=[1, filter_height, filter_width, 1], strides=[1, stride_y, stride_x, 1],
padding=padding, name=name)
def fc(x, num_in, num_out, name, dropout_keep_prob=0.5, relu=True, training=True):
with tf.variable_scope(name) as scope:
kernel = tf.get_variable('weight',
initializer=tf.truncated_normal([num_in, num_out], dtype=tf.float32, stddev=1e-1))
biases = tf.get_variable('biases', initializer=tf.constant(1.0, shape=[num_out], dtype=tf.float32))
out = tf.nn.bias_add(tf.matmul(x, kernel), biases, name=scope.name)
if relu:
out = tf.nn.relu(out)
if training:
out = tf.nn.dropout(out, dropout_keep_prob)
return out