CentOS7部署Hadoop2.7.5全分布式群集
文章目录
- 安装虚拟机
- 安装JDK
- 克隆
- 安装HADOOP
- 配置HADOOP
- 修改UUID
- 修改计算机名
- 修改映射
- 配置SSH
- 搭建全分布环境
- 配置hadoop-env.sh
- 配置core-site.xml
- 配置hdfs-site.xml
- 配置mapred-site.xml
- 配置yarn-site.xml
- 配置slaves
- 远程分发到服务器上
- 启动之前需要格式化
- 测试
- 验证
安装虚拟机
VMware Workstation 12.5.7 PRO 安装 CentOS7
安装JDK
linux安装最新版JDK
克隆
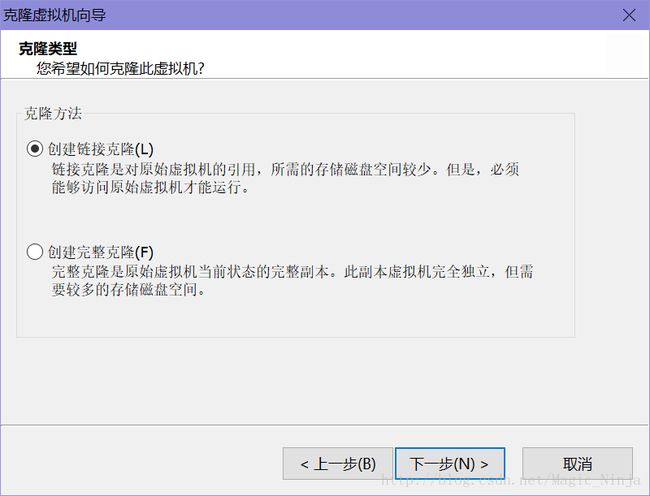
我是直接克隆虚拟机,要是有服务器或者自安装也可以。
点击完整克隆
安装HADOOP
CentOS7安装单机版Hadoop
配置HADOOP
修改UUID
vim /etc/sysconfig/network-scripts/ifcfg-ens33
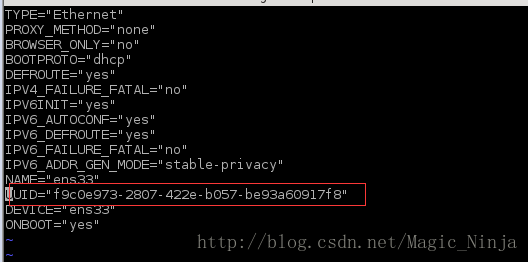
因为克隆过来的UUID是相同的,可以删除重新生成,也可以修改其中一个数就可以了,里面的数值是16进制的,在这范围内就可以。
修改计算机名
hostnamectl --static set-hostname hadoop01

修改映射
vim /etc/hosts
192.168.164.137 hadoop01 www.hadoop01.com
192.168.164.136 hadoop02 www.hadoop02.com
192.168.164.138 hadoop03 www.hadoop03.com

CentOS7克隆之后IP地址是自动分配的,所以不需要自己设置
查询本机IP
ifconfig
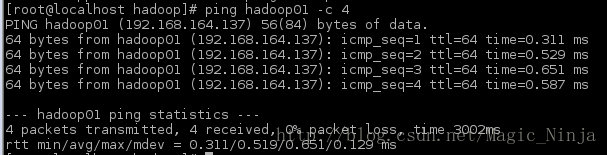
检验是能联通,在win的cmd ping一下
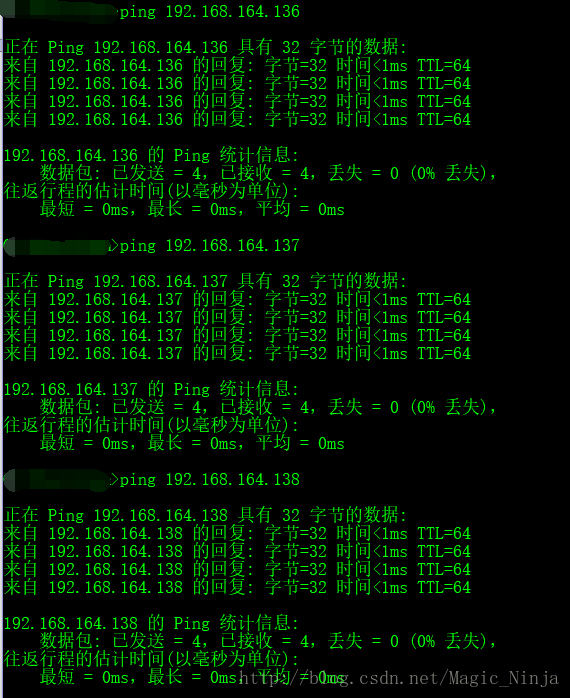
改名之后可以通过名字来在虚拟机之间通讯
配置SSH
cd /root/.ssh
ssh-keygen -t rsa
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
# hadoop01,hadoop02,hadoop03是我的主机名,主机名自己设置的
搭建全分布环境
规划
| 主机名称 | IP地址 | 功能 |
|---|---|---|
| hadoop01 | 192.168.164.137 | NameNode,DataNode,ResourceManager,NodeManager |
| hadoop02 | 192.168.164.136 | DataNode,NodeManager |
| hadoop03 | 192.168.164.138 | DataNode,NodeManager |
| 所有机子都需要配置 |
|---|
| 1.JDK 2.SSH免登陆 3.Hadoop集群 |
配置hadoop-env.sh
vim /usr/local/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.x86_64
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.5/etc/hadoop/
配置core-site.xml
vim /usr/local/Hadoop-2.7.5/etc/Hadoop/core-site.xml
<configuration>
<!-- configuration hdfs file system namespace -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- configuration hdfs cache size of the operation -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- configuration hdfs Temporary data storage directory -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mshing/bigdata/tmp</value>
</property>
</configuration>
配置hdfs-site.xml
vim /usr/local/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoopdata/dfs/data</value>
</property>
<property>
<name>dfs.chechpoint.dir</name>
<value>/home/hadoop/hadoopdata/checkpoint/dfs/cname</value>
</property>
<property>
<name>dfs.http.address</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop01:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
配置mapred-site.xml
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
配置yarn-site.xml
vim etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>
配置slaves
vim etc/hadoop/slaves

远程分发到服务器上
scp -r /usr/local/hadoop-2.7.5/ hadoop02:/usr/local/
scp -r /usr/local/hadoop-2.7.5/ hadoop03:/usr/local/
启动之前需要格式化
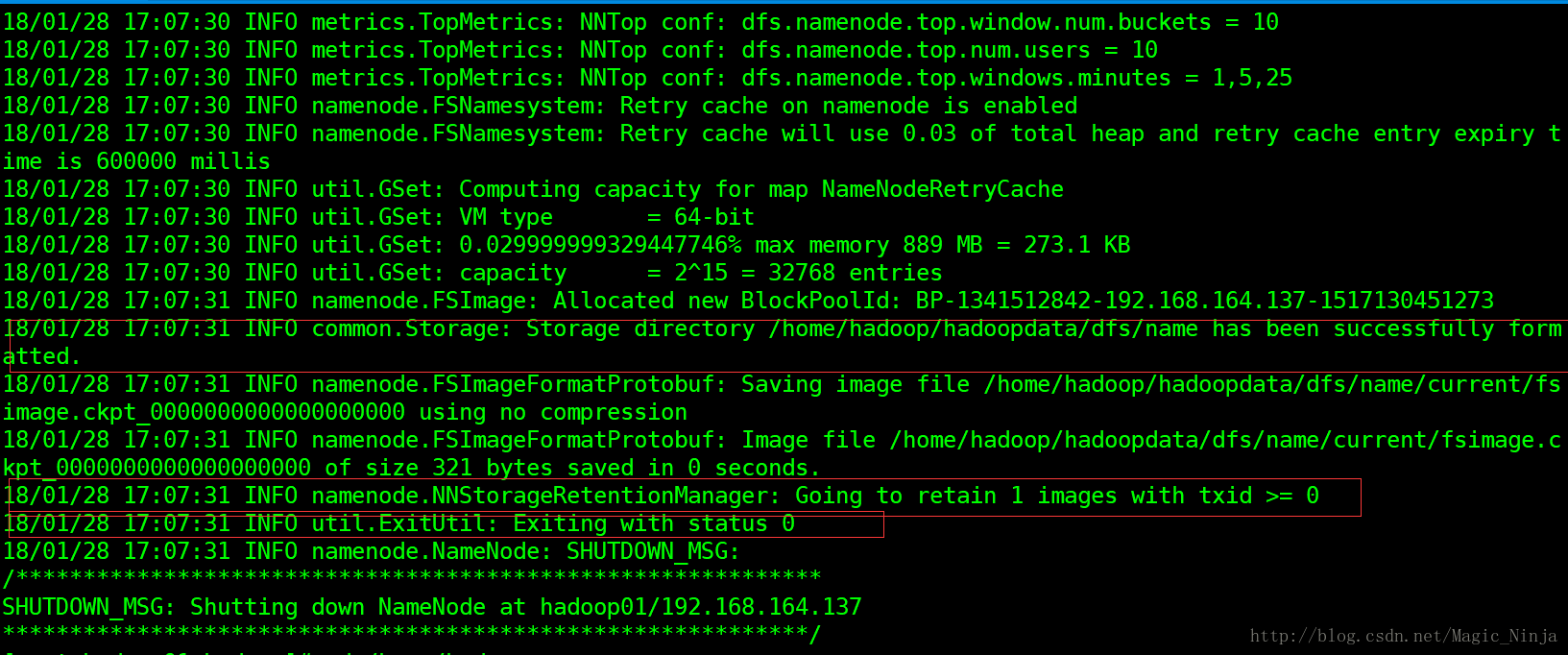
启动之前,在namenode服务器上先格式化,只需格式化一次就好了
hadoop namenode -format
测试
启动namenode,datanode,ResourceManager,NodeManager节点
全启动:
start-all.sh
模块启动:
start -dfs.sh
start -yarn.sh
单个进程启动/停止:
hadoop-damon.sh start/stop namenode
hadoop-damons.sh start/stop datanode
yarn-damon.sh start/stop namenode
yarn-damons.sh start/stop namenode
mr-jobhistory-daemon.sh start/stop historyserver
验证
在三台机子分别输入
jps
就可以看到启动的进程了