WSDM Cup 2019自然语言推理任务获奖解题思路

总第337篇
2019年 第15篇

美美导读:美团团队在刚刚结束的WSDM Cup 2019比赛“真假新闻甄别任务”中获得了第二名的好成绩。本文将详细介绍他们本次获奖的解决方案,里面用到了很多黑科技比如BERT哦。
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2。
刚刚在墨尔本结束的第12届WSDM大会传来一个好消息,由美团搜索与NLP部NLP中心的刘帅朋、刘硕和任磊三位同学组成的Travel团队,在WSDM Cup 2019大赛 “真假新闻甄别任务” 中获得了第二名的好成绩。队长刘帅朋受邀于2月15日代表团队在会上作口头技术报告,向全球同行展示了来自美团点评的解决方案。本文将详细介绍他们本次获奖的解决方案。

1. 背景
信息技术的飞速发展,催生了数据量的爆炸式增长。技术的进步也使得了人们获取信息的方式变得更加便捷,然而任何技术都是一把“双刃剑”,信息技术在为人们的学习、工作和生活提供便利的同时,也对人类社会健康持续的发展带来了一些新的威胁。目前亟需解决的一个问题,就是如何有效识别网络中大量存在的“虚假新闻”。虚假新闻传播了很多不准确甚至虚构的信息,对整个线上资讯的生态造成了很大的破坏,而且虚假新闻会对读者造成误导,干扰正常的社会舆论,严重的危害了整个社会的安定与和谐。因此,本届WSDM Cup的一个重要议题就是研究如何实现对虚假新闻的准确甄别,该议题也吸引了全球众多数据科学家的参与。
虽然美团点评的主营业务与在线资讯存在一些差异,但本任务涉及的算法原理是通用的,而且在美团业务场景中也可以有很多可以落地,例如虚假评论识别、智能客服中使用的问答技术、NLP平台中使用的文本相似度计算技术、广告匹配等。于是,Travel团队通过对任务进行分析,将该问题转化为NLP领域的“自然语言推理” (NLI)任务,即判断给定的两段文本间的逻辑蕴含关系。因此,基于对任务较为深入理解和平时的技术积累,他们提出了一种解决方案——一种基于多层次深度模型融合框架的虚假新闻甄别技术,该技术以最近NLP领域炙手可热的BERT为基础模型,并在此基础上提出了一种多层次的模型集成技术。
2. 数据分析
为了客观地衡量算法模型的效果,本届大会组织方提供了一个大型新闻数据集,该数据集包含32万多个训练样本和8万多个测试样本,这些数据样本均取材于互联网上真实的数据。每个样本包含有两个新闻标题组成的标题对,其中标题对类别标签包括Agreed、Disagreed、Unrelated等3种。他们的任务就是对测试样本的标签类别进行预测。
“磨刀不误砍柴功”,在一开始,Travel团队并没有急于搭建模型,而是先对数据进行了全面的统计分析。他们认为,如果能够通过分析发现数据的一些特性,就会有助于后续采取针对性的策略。
首先,他们统计了训练数据中的类别分布情况,如图1所示,Unrelated类别占比最大,接近70%;而Disagreed类占比最小,不到3%。训练数据存在严重的类别不均衡问题,如果直接用这样的训练数据训练模型,这会导致模型对占比较大类的学习比较充分,而对占比较小的类别学习不充分,从而使模型向类别大的类别进行偏移,存在较严重的过拟合问题。后面也会介绍他们针对该问题提出的对应解决方案。
 图1 数据集中类别分布情况
图1 数据集中类别分布情况
然后,Travel团队对训练数据的文本长度分布情况进行了统计,如图2所示,不同类别的文本长度分布基本保持一致,同时绝大多数文本长度分布在20~100内。这些统计信息对于后面模型调参有着很大的帮助。
 图2 数据集中文本长度分布情况
图2 数据集中文本长度分布情况
3. 数据的预处理与数据增强
本着“数据决定模型的上限,模型优化只是不断地逼近这个上限”的想法,接下来,Travel团队对数据进行了一系列的处理。
在数据分析时,他们发现训练数据存在一定的噪声,如果不进行人工干预,将会影响模型的学习效果。比如新闻文本语料中简体与繁体共存,这会加大模型的学习难度。因此,他们对数据进行繁体转简体的处理。同时,过滤掉了对分类没有任何作用的停用词,从而降低了噪声。
此外,上文提到训练数据中,存在严重的样本不均衡问题,如果不对该问题做针对性的处理,则会严重制约模型效果指标的提升。通过对数据进行了大量的分析后,他们提出了一个简单有效的缓解样本不均衡问题的方法,基于标签传播的数据增强方法。具体方法如图3所示:
 图3 数据增强策略
图3 数据增强策略
如果标题A与标题B一致,而标题A与标题C一致,那么可以得出结论,标题B与标题C一致。同理,如果标题A与标题B一致,而标题A与标题D不一致,那么可以得出结论,标题B与标题D也不一致。此外,Travel团队还通过将新闻对中的两条文本相互交换位置,来扩充训练数据集。
4. 基础模型
BERT是Google最新推出的基于双向Transformer的大规模预训练语言模型,在11项NLP任务中夺得SOTA结果,引爆了整个NLP界。BERT取得成功的一个关键因素是Transformer的强大特征提取能力。Transformer可以利用Self-Attention机制实现快速并行训练,改进了RNN最被人所诟病的“训练慢”的缺点,可以高效地对海量数据进行快速建模。同时,BERT拥有多层注意力结构(12层或24层),并且在每个层中都包含有多个“头”(12头或16头)。由于模型的权重不在层与层之间共享,一个BERT模型相当于拥有12×12=224或24×16=384种不同的注意力机制,不同层能够提取不同层次的文本或语义特征,这可以让BERT具有超强的文本表征能力。
本赛题作为典型的自然语言推理(NLI)任务,需要提取新闻标题的高级语义特征,BERT的超强文本表征能力正好本赛题所需要的。基于上述考虑,Travel团队的基础模型就采用了BERT模型,其中BERT网络结构如图4所示:
 图4 BERT网络结构图
图4 BERT网络结构图
在比赛中,Travel团队在增强后的训练数据上对Google预训练BERT模型进行了微调(Finetune),使用了如图5所示的方式。为了让后面模型融合增加模型的多样性,他们同时Finetune了中文版本和英文版本。
 图5 基于BERT的假新闻分类模型结构
图5 基于BERT的假新闻分类模型结构
5. 多层次深度模型融合框架
模型融合,是指对已有的多个基模型按照一定的策略进行集成以提升模型效果的一种技术,常见的技术包括Voting、Averaging、Blending、Stacking等等。这些模型融合技术在前人的许多工作中得到了应用并且取得了不错的效果,然而任何一种技术只有在适用场景下才能发挥出最好的效果,例如Voting、Averaging技术的融合策略较为简单,一般来说效果提升不是非常大,但优点是计算逻辑简单、计算复杂度低、算法效率高;而Stacking技术融合策略较复杂,一般来说效果提升比较明显,但缺点是算法计算复杂度高,对计算资源的要求较苛刻。
本任务使用的基模型为BERT,该模型虽然拥有非常强大的表征建模能力,但同时BERT的网络结构复杂,包含的参数众多,计算复杂度很高,即使使用了专用的GPU计算资源,其训练速度也是比较慢的,因此这就要求在对BERT模型融合时不能直接使用Stacking这种高计算复杂度的技术,因此我们选择了Blending这种计算复杂度相对较低、融合效果相对较好的融合技术对基模型BERT做融合。
同时,Travel团队借鉴了神经网络中网络分层的设计思想来设计模型融合框架,他们想既然神经网络可以通过增加网络深度来提升模型的效果,那么在模型融合中是否也可以通过增加模型融合的层数来提升模型融合的效果呢?基于这一设想,他们提出了一种多层次深度模型融合框架,该框架通过增加模型的层数进而提升了融合的深度,最终取得了更好的融合效果。
具体来说,他们的框架包括三个层次,共进行了两次模型融合。第一层采用Blending策略进行模型训练和预测,在具体实践中,他们选定了25个不同的BERT模型作为基模型;第二层采用5折的Stacking策略对25个基模型进行第一次融合,这里他们选用了支持向量机(SVM)、逻辑回归(LR)、K近邻(KNN)、朴素贝叶斯(NB),这些传统的机器学习模型,既保留了训练速度快的优点,也保证了模型间的差异性,为后续融合提供了效率和效果的保证;第三层采用了一个线性的LR模型,进行第二次模型融合并且生成了最终的结果。模型融合的架构如图6所示:
 图6 模型融合架构
图6 模型融合架构
整体方案模型训练分为三个阶段,如图7所示:
第一个阶段,将训练数据划分为两部分,分别为Train Data和Val Data。Train Data用于训练BERT模型,用训练好的BERT模型分别预测Val Data和Test Data。将不同BERT模型预测的Val Data和Test Data的结果分别进行合并,可以得到一份新的训练数据New Train Data和一份新的测试数据New Test Data。
第二阶段,将上一阶段的New Train Data作为训练数据,New Test Data作为测试数据。本阶段将New Train Data均匀的划分为5份,使用“留一法”训练5个SVM模型,用这5个模型分别去预测剩下的一份训练数据和测试数据,将5份预测的训练数据合并,可以得到一份新的训练数据NewTrainingData2,将5份预测的测试数据采用均值法合并,得到一份新的测试数据NewTestData2。同样的方法再分别训练LR、KNN、NB等模型。
第三阶段,将上一阶段的NewTrainingData2作为训练数据,NewTestData2作为测试数据,重新训练一个LR模型,预测NewTestData2的结果作为最终的预测结果。为了防止过拟合,本阶段采用5折交叉验证的训练方式。
 图7 假新闻分类方案的整体架构和训练流程
图7 假新闻分类方案的整体架构和训练流程
6. 实验
6.1 评价指标
为了缓解数据集中存在的类别分布不均衡问题,本任务使用带权重的准确率作为衡量模型效果的评价指标,其定义如下所示:
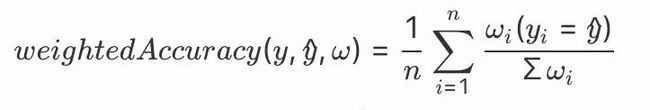
其中,y为样本的真实类别标签,![]() 为模型的预测结果,
为模型的预测结果,![]() 为数据集中第i个样本的权重,其权重值与类别相关,其中Agreed类别的权重为1/15,Disagreed类别的权重为1/5,Unrelated类别的权重为1/16。
为数据集中第i个样本的权重,其权重值与类别相关,其中Agreed类别的权重为1/15,Disagreed类别的权重为1/5,Unrelated类别的权重为1/16。
6.2 实验结果
在官方测试集上,Travel团队的最优单模型的准确率达到0.86750,25个BERT模型简单平均融合后准确率达0.87700(+0.95PP),25个BERT模型结果以加权平均的形式融合后准确率达0.87702(+0.952PP),他们提出的多层次模型融合技术准确率达0.88156(+1.406PP)。实践证明,美团NLP中心的经验融合模型在假新闻分类任务上取得了较大的效果提升。
 图8 效果提升
图8 效果提升
7. 总结与展望
本文主要对解决方案中使用的关键技术进行了介绍,比如数据增强、数据预处理、多层模型融合策略等,这些方法在实践中证明可以有效的提升预测的准确率。由于参赛时间所限,还有很多思路没有来及尝试,例如美团使用的BERT预训练模型是基于维基百科数据训练而得到的,而维基百科跟新闻在语言层面也存在较大的差异,所以可以将现有的BERT在新闻数据上进行持续地训练,从而使其能够对新闻数据具有更好的表征能。
参考文献
[1] Dagan, Ido, Oren Glickman, and Bernardo Magnini. 2006. The PASCAL recognising textual entailment challenge, Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment. Springer, Berlin, Heidelberg, 177-190.
[2] Bowman S R, Angeli G, Potts C, et al. 2015. A large annotated corpus for learning natural language inference. In proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP).
[3] Adina Williams, Nikita Nangia, and Samuel R Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In NAACL.
[4] Rajpurkar P, Zhang J, Lopyrev K, et al. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250.
[5] Luisa Bentivogli, Bernardo Magnini, Ido Dagan, Hoa Trang Dang, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC. NIST.
[6] Hector J Levesque, Ernest Davis, and Leora Morgenstern. 2011. The winograd schema challenge. In Aaai spring symposium: Logical formalizations of commonsense reasoning, volume 46, page 47.
[7] Bowman, Samuel R., et al. 2015. "A large annotated corpus for learning natural language inference." arXiv preprint arXiv:1508.05326.
[8] Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. 2018. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv preprint arXiv:1804.07461.
[9] Chen, Q., Zhu, X., Ling, Z., Wei, S., Jiang, H., & Inkpen, D. 2016. Enhanced lstm for natural language inference. arXiv preprint arXiv:1609.06038.
[10] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.
[11] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[12] David H. Wolpert. 1992. Stacked generalization. Neural Networks (1992). https: //doi.org/10.1016/S0893- 6080(05)80023- 1.
[13] Shuaipeng Liu, Shuo Liu, Lei Ren. 2019. Trust or Suspect? An Empirical Ensemble Framework for Fake News Classification. WSDM Cup 2019 Workshop, AU, February 2019, 4 pages.
作者简介
刘帅朋,硕士,美团点评搜索与NLP部NLP中心高级算法工程师,目前主要从事NLU相关工作。曾任中科院自动化研究所研究助理,主持研发的智能法律助理课题获CCTV-1频道大型人工智能节目《机智过人第二季》报道。
刘硕,硕士,美团点评搜索与NLP部NLP中心智能客服算法工程师,目前主要从事智能客服对话平台中离线挖掘相关工作。
任磊,硕士,美团点评搜索与NLP部NLP中心知识图谱算法工程师,目前主要从事美团大脑情感计算以及BERT应用相关工作。
会星,博士,担任美团点评搜索与NLP部NLP中心的研究员,智能客服团队负责人。目前主要负责美团智能客服业务及智能客服平台的建设。在此之前,会星在阿里达摩院语音实验室作为智能语音对话交互专家,主要负责主导的产品有斑马智行语音交互系统,YunOS语音助理等,推动了阿里智能对话交互体系建设。
富峥,博士,担任美团点评搜索与NLP部NLP中心的研究员,带领知识图谱算法团队。目前主要负责美团大脑项目,围绕美团吃喝玩乐场景打造的知识图谱及其应用。在知识图谱、个性化推荐、用户画像、时空数据挖掘等领域展开了众多的创新性研究,并在相关领域的顶级会议和期刊上发表30余篇论文,如KDD、WWW、AAAI、IJCAI、TKDE、TIST等,曾获ICDM2013最佳论文大奖,出版学术专著1部。
仲远,博士,美团点评搜索与NLP部负责人。在国际顶级学术会议发表论文30余篇,获得ICDE 2015最佳论文奖,并是ACL 2016 Tutorial “Understanding Short Texts”主讲人,出版学术专著3部,获得美国专利5项。此前,曾担任微软亚洲研究院主管研究员,以及美国Facebook公司Research Scientist。曾负责微软研究院知识图谱、对话机器人项目和Facebook产品级NLP Service。
欢迎加入美团深度学习技术交流群,跟作者零距离交流。进群方式:请加美美同学微信(微信号:MTDPtech02),回复:自然语言,美美会自动拉你进群。
---------- END ----------
也许你还想看
美团餐饮娱乐知识图谱——美团大脑揭秘
美团大脑:知识图谱的建模方法及其应用
美团外卖日单量破1600万背后的“超级大脑”之订单分配
