Python实战篇 | 使用selenium来模拟浏览器抓取淘宝美食商品信息
爬虫原理分析:

项目流程设计思路:

爬虫前奏:安装MongoDB数据库
【1】MongoDB数据库下载(密码:09z1)
【2】MongoDB数据库安装指南
【3】RoboMongo - MongoDB数据库可视化开发工具(密码:ifav)
【如果失效,可以和我联系获取或者百度进行搜索】
使用到的模块:
(1)selenium
自动化测试工具、支持多种浏览器;
爬虫中主要用于解决JavaScript渲染问题。
selenium是一个用于Web应用程序测试的工具。
selenium自动化测试直接运行在浏览器中,就像真正的用户在操作一样。
# 安装selenium模块命令(在DOS窗口中输入,前提:已配置好环境变量)
pip install selenium 点击查看selenium模块使用文档
(2)pyquery
PyQuery库也是一个非常强大又灵活的网页解析库;
我们使用PyQuery来解析html。
# 安装pyquery模块命令(在DOS窗口中输入,前提:已配置好环境变量)
pip install pyquery 点击查看pyquery模块使用文档
(3)pymongo(pymongo是操作MongoDB的python模块)
在这个项目中,我们另外生成一个名为config.py的文件(相当于一个配置文件)。
# 在文件中,我们配置一些MongoDB的相关信息:
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_TABLE='products'
KEY_WORD="美食"
SERVICE_ARGS=["--load-images=false", "--disk-cache=true"]对配置文件进行分析:
MONGO_URL:表示连接MongoDB数据库的主机地址
MONGO_DB: 表示数据库的名字
MONGO_TABLE:表示数据表的名字
KEY_WORD: 进行搜索的关键字
SERVICE_ARGS:
为了更好、更快的抓取数据并存放到数据库中;
我们不需要在浏览器中加载图片,并开启磁盘缓冲
# 安装pymongo模块命令(在DOS窗口中输入,前提:已配置好环境变量)
pip install pymongo 点击查看pymongo模块的官方文档
(4)re
在该项目中,我们使用re模块
# 对页码多余的部分进行处理,我们只需要总页码的数字即可
total =int(re.compile("(\d+)").search(total).group(1))
(5)chromeDriver驱动浏览器:
由于Selenium可以操作各种浏览器进行测试,所以在使用之前我们需要在电脑上安装对应的浏览器。
(摩卡已经将三大浏览器驱动下载地址放到这啦!点击即可跳转~)
【1】Chrome浏览器的驱动chromedriver
【2】Firefox浏览器的驱动geckodriver
【3】IE浏览器的驱动IEdriver
在这个项目中,我们使用Chrome浏览器作为自动化测试的浏览器。
(小伙伴们根据实际情况选择相应的浏览器驱动)
下载好后, 将可执行文件放到python安装目录下的Scripts文件夹中;
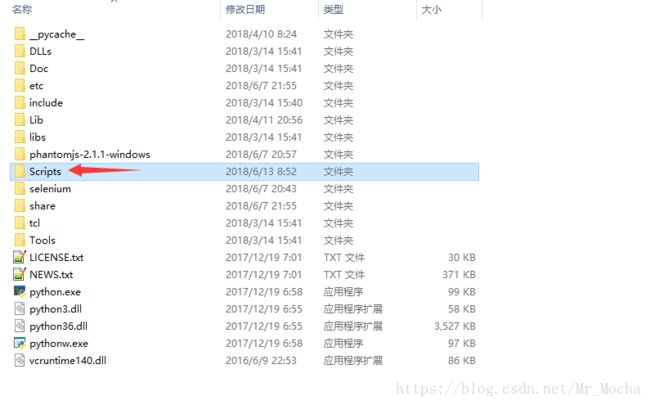
测试是否已经安装好,在python命令行中输入:
(如果弹出浏览器,说明执行成功)
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")选中搜索输入框,右键选择“检查” 即可定位到该元素的位置。 此时我们右键,选择“Copy” –> 选择“Copy selector”
获取class属性使用: .class属性名称
获取id属性使用: #id属性名称

Start Project!开启我们的项目~
定义的方法(函数):
(1)def search():
"""在搜索框输入关键字,进行页面跳转
:return 返回页码数
"""
(2)def next_page(page_number):
"""跳转到下一页"""
(3)def get_products():
"""获取商品信息"""
(4)def save_products(result):
"""将商品的信息存储到MongoDB数据库、txt文件中"""
(5)def main():
"""主方法"""# 配置文件
MONGO_URL = "localhost"
MONGO_DB = "taobao"
MONGO_TABLE = "products"
KEY_WORD = "美食"
SERVICE_ARGS = ["--load-images=false", "--disk-cache=true"]# 使用selenium来模拟浏览器抓取淘宝美食商品信息
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
from config import *
import re
import pymongo
# 连接MongoDB数据库
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
# 导入selenium模块中的webdriver,使用Chrome()来获取浏览器对象
browser = webdriver.Chrome()
# browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
# browser.set_window_size(1400, 1000)
# 因为在请求网页时,网页需要加载,那么我们需要等待网页完全加载才能进行下一步
wait = WebDriverWait(browser, 10)
def search():
"""在搜索框输入关键字,进行页面跳转
:return 返回页码数
"""
try:
browser.get("https://www.taobao.com/")
# EC 表示:期待的条件
# 输入搜索关键字
# EC.presence_of_element_located 判断是否加载成功
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))
)
# 点击搜索按钮,提交搜索关键字
# EC.element_to_be_clickable 期待鼠标点击
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button"))
)
# 提交搜索关键字
input.send_keys(KEY_WORD)
submit.click()
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total"))
)
# 获取商品信息
get_products()
return total.text
except TimeoutException:
print("请求超时")
def next_page(page_number):
"""跳转到下一页"""
try:
# 输入要跳转的页数
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input"))
)
# 确认进行跳转
submit = wait.until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit"))
)
input.clear()
input.send_keys(page_number)
submit.click()
# 判断当前的页数与网页的高亮显示是否对应得上
wait.until(
EC.text_to_be_present_in_element(
(By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"), str(page_number))
)
# 获取商品信息
get_products()
except TimeoutException:
next_page(page_number)
def get_products():
"""获取商品信息"""
# 判断商品是否加载成功
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-itemlist .items .item"))
)
# 获取页面信息
html = browser.page_source
doc = pq(html) # 使用PyQuery来解析html
items = doc("#mainsrp-itemlist .items .item").items()
for item in items:
product = {
# 去掉价格中的换行符
"price": item.find(".price").text().replace("\n", ""),
"image": item.find(".pic .img").attr("src"),
"name": item.find(".title").text(),
"location": item.find(".location").text(),
"shop": item.find(".shop").text(),
}
"""
需要保存的商品信息:
(1)商品的图片
(2)商品的价格
(3)商品的名字
(4)商品来源
(5)商品店铺
"""
print(product)
save_products(product)
print("=" * 30)
def save_products(result):
"""将商品的信息存储到MongoDB数据库、txt文件中"""
try:
# 尝试将结果集插入到数据库中
if db[MONGO_TABLE].insert(result):
print("存储到MongoDB数据库成功!", result)
# 将结果集存储到txt文件中
if result:
with open("products.txt", "a", encoding="utf-8") as f:
f.write(str(result) + "\n")
f.close()
except Exception:
print("存储失败!", result)
def main():
"""主方法"""
try:
total = search()
# 对页码多余的部分进行处理
total = int(re.compile("(\d+)").search(total).group(1))
# print(total)
for i in range(2, total + 1):
next_page(i)
except Exception:
print("出错啦!")
finally:
browser.close() # 最后一定都要关闭浏览器
if __name__ == "__main__":
main()
运行结果:
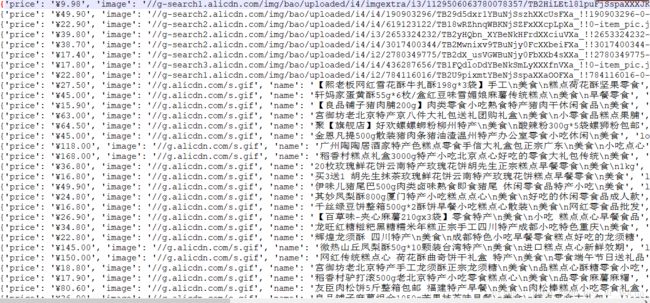
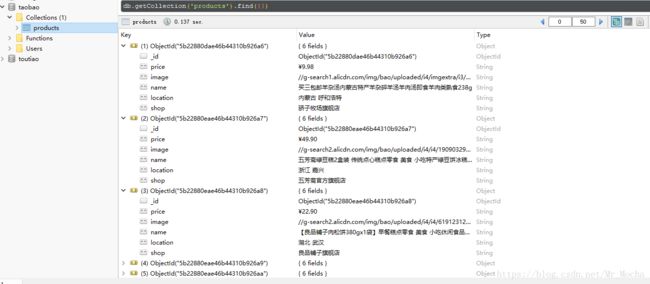
我是摩卡先生,谢谢你的阅读。
喜欢的话,关注我,期待我后续的文章吧!
本项目由焱章同学和摩卡(泽锋)共同完成!
如果小伙伴们在学习Java过程中,
有疑惑或者故事想要和摩卡先生说的话 ,
欢迎大家来加摩卡的微信喔,来交个朋友吧~
