detectron代码理解(一):Resnet模型构建
这里具体以resnet50为例进行说明,一句一句地分析代码,代码位置位于Resnet.py,具体的分析函数为add_ResNet_convX_body.
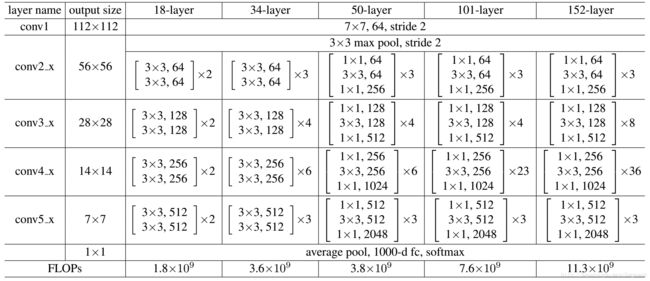
在分析之前首先贴上resnet50的代码结构图:
# add the stem (by default, conv1 and pool1 with bn; can support gn)
p, dim_in = globals()[cfg.RESNETS.STEM_FUNC](model, 'data')这里p = gpu_0/pool1,dim_in = 64
从上面的图可以看出,p就是经过开始的3×3的pooling得到的,因为前面的卷积个数为64,poll不改变特征图个数,所以输出的dim_in = 64。这里之所以称为dim_in是相对与下面bottleneck是输入。
dim_bottleneck = cfg.RESNETS.NUM_GROUPS * cfg.RESNETS.WIDTH_PER_GROUP
(n1, n2, n3) = block_counts[:3] #dim_bottleneck的数值与GPU的数量有关,GPU的数量乘以这个一个基本的数值cfg.RESNETS.WIDTH_PER_GROUP就得到了dim_bottleneck,这里dim_bottleneck = 64。
(n1, n2, n3) = (3,4,6)。这里的n1是表格中conv2_x中的3,代表3个residual block,n2,n3同理
s, dim_in = add_stage(model, 'res2', p, n1, dim_in, 256, dim_bottleneck, 1)添加第一个stage,其中(下面所述的表格中的都是,conv2_x这一行的)
(1)p为输入,即gpu_0/pool1
(2)n1为block的数目,
(3)dim_in是输入特征图的大小,即上面所述的64
(4)256表示经过这个stage后输出的特征图数量,对应表格中的256
(5)dim_bottleneck=64,对应表格中的64
我们再来看stage函数,是一个for循环,同过循环来依次添加resiual block,n=3,也就是添加3个
def add_stage(
model,
prefix,
blob_in,
n,
dim_in,
dim_out,
dim_inner,
dilation, # 相当于padding参数
stride_init=2
):
"""Add a ResNet stage to the model by stacking n residual blocks."""
# e.g., prefix = res2
for i in range(n):
blob_in = add_residual_block(
model,
'{}_{}'.format(prefix, i),
blob_in,
dim_in,
dim_out,
dim_inner,
dilation,
stride_init,
# Not using inplace for the last block;
# it may be fetched externally or used by FPN
inplace_sum=i < n - 1
)
print(blob_in)
dim_in = dim_out
return blob_in, dim_inadd_stage这个函数会调用到add_residual_block函数,应该很容易的理解到,对于conv2_x这个stage每一个residual block的输出都是256个featuremap。
同时还要理清相关的关系,于第一个residual block,下面的dim_in是64,是上面pool的输出。对于第二个residual block,这时候的dim_in就是第一个residual block的输出了,也就是256,不过中间的dim_inner仍是64,其目的是减少参数,最后的输出dim_out也还是256。第三个residual block同理,对应表格就能很清楚的明白。
def add_residual_block(
model,
prefix,
blob_in,
dim_in,
dim_out,
dim_inner,
dilation,
stride_init=2,
inplace_sum=False
):
"""Add a residual block to the model."""
# prefix = res_, e.g., res2_3
# Max pooling is performed prior to the first stage (which is uniquely
# distinguished by dim_in = 64), thus we keep stride = 1 for the first stage
stride = stride_init if (
dim_in != dim_out and dim_in != 64 and dilation == 1
) else 1
# transformation blob dim_in表示输入,dim_out表示输出,dim_inner表示中间
tr = globals()[cfg.RESNETS.TRANS_FUNC](
model,
blob_in,
dim_in,
dim_out,
stride,
prefix,
dim_inner,
group=cfg.RESNETS.NUM_GROUPS,
dilation=dilation
)
# sum -> ReLU
# shortcut function: by default using bn; support gn 恒等映射
add_shortcut = globals()[cfg.RESNETS.SHORTCUT_FUNC]
sc = add_shortcut(model, prefix, blob_in, dim_in, dim_out, stride) #恒等映射
if inplace_sum:
s = model.net.Sum([tr, sc], tr) #第二个参数相当于命名
else:
s = model.net.Sum([tr, sc], prefix + '_sum')
return model.Relu(s, s) 最后生成的模型结构(加粗部分是该stage最终的输出,res2_0表示第二层的第一个residual block,res2_1表示第二层的第二个residual block)
| conv2_x | gpu_0/res2_0_branch2c_bn gpu_0/res2_1_branch2c_bn gpu_0/res2_2_sum |
| conv3_x | gpu_0/res3_0_branch2c_bn gpu_0/res3_1_branch2c_bn gpu_0/res3_2_branch2c_bn gpu_0/res3_3_sum |
| conv4_x | gpu_0/res4_0_branch2c_bn gpu_0/res4_1_branch2c_bn gpu_0/res4_2_branch2c_bn gpu_0/res4_3_branch2c_bn gpu_0/res4_4_branch2c_bn gpu_0/res4_5_sum |
| conv5_x | gpu_0/res5_0_branch2c_bn gpu_0/res5_2_sum |