C++ STL库/C头文件函数
转载@Memset 转载@Jason333
目录
Vector 操作函数
List 操作函数
Set和Multiset 操作函数
Map和Multimap 操作函数
优先队列
Vector
1、结构
vector模塑出一个动态数组,因此,它本身是“将元素置于动态数组中加以管理”的一个抽象概念。vector将其元素复制到内部的dynamic array中。元素之间总存在某种顺序,所以vector是一种有序群集。vector支持随机存取,因此只要知道位置,可以在常数时间内存取任何一个元素。根据vector的结构可知,在末端添加或者删除元素,性能相当好,如果在前端或者中部安插或删除元素,性能就不怎么样了,因为操作点之后的元素都需要移到另一位置,而每一次移动都需要调用assignement(赋值)操作符。

2、大小(size)和容量(capacity)
2.1 性能
vector的优异性能的秘诀之一就是配置比其容纳元素所需更多的内存。vector用于操作大小的函数有size(),empty(),max_size(),另一个有关大小的函数是capacity(),它返回的是vector实际能够容纳的元素数量,如果超越这个数量,vector就有必要重新配置内部存储器。
vector的容量之所以很重要,有以下两个原因:
- 一旦内存重新分配,和vector相关的所有元素都会失效,如:references,pointers,iterators。
- 内存分配很耗时间
2.2 内存分配
2.2.1 reserve
如果程序管理了和vector元素相关的reference,pointers,iterator,或者执行效率至关重要,那么就必须考虑容器的容量问题。可以使用reserve()来保留适当容量,避免一再的分配内存,只要保留的容量有剩余,就不用担心reference失效。
std::vector v;
v.reserve(n); //为vector分配容量为n的内存 还有一点要记住的是,如果调用reserve()所给的参数比当前的vector容量还小,不会发生任何反应,vector不能通过reverse来缩减容量。如何达到时间和空间的最佳效率,由系统版本决定,很多时候为了防止内存破碎,即使不调用reserve,当你第一次安插元素的时候,也会一次性配置整块内存(例如2K)。vector的容量不会缩减,即使删除元素,其reference,pointers,iterators也不会失效,继续指向发生动作之前的位置,然而安插元素可能使这些元素失效(因为安插可能重新分配内存空间)。
2.2.2 构造分配
另外一种避免重新分配内存的方法是,初始化期间就像构造函数传递附加参数,构造出足够的空间。如果参数是个数值,它将成为vector的起始大小。
std::vector v(500); //分配能容纳500个T元素的内存大小 当然,要获得这种能力,这种元素必须提供一个default构造函数,如果类型很复杂,提供了default构造函数,初始化也会很耗时,如果只是为了保留足够的内存,建议使用reverse()。
2.2.3 内存缩减
当然,要想缩减vector内存还是有方法的,那就是两个vector交换了内容后,两者的容量也会交换,即保留元素,又缩减了内存。
![]()
template
void shrinkCapacity(std::vector &v)
{
std::vector temp(v); //初始化一个新的vector
v.swap(temp); //交换元素内容
} ![]()
或者通过下列语句:
std::vector (v).swap(v); 不过应该注意的是,swap()之后,原先所有的reference,pointers,iterator都换了指涉对象,他们仍然指向原本位置,也就是说它们在交换之后,都失效了。
![]()
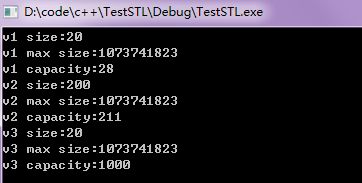
void mvTestSize()
{
// size 为20的vector
vector veciSize1;
for (int i = 0; i < 20; i++)
{
veciSize1.push_back(i);
}
cout << "v1 size:" << veciSize1.size() << endl;
cout << "v1 max size:" << veciSize1.max_size() << endl;
cout << "v1 capacity:" << veciSize1.capacity() << endl;
// size为200的vector
vector veciSize2;
for (int i = 0; i < 200; i++)
{
veciSize2.push_back(i);
}
cout << "v2 size:" << veciSize2.size() << endl;
cout << "v2 max size:" << veciSize2.max_size() << endl;
cout << "v2 capacity:" << veciSize2.capacity() << endl;
//分配固定的size
vector veciSize3;
veciSize3.reserve(1000);
for (int i = 0; i < 20; i++)
{
veciSize3.push_back(i);
}
cout << "v3 size:" << veciSize3.size() << endl;
cout << "v3 max size:" << veciSize3.max_size() << endl;
cout << "v3 capacity:" << veciSize3.capacity() << endl;
} ![]()
输出结果:
3、 vector操作函数
3.1 构造、拷贝和析构
可以在构造时提供元素,也可以不提供。如果指定大小,系统会调用元素的default构造函数一一制造新元素。
| 操作 |
效果 |
| vector |
产生一个空的vector,没有任何元素 |
| vector |
产生另一同一类型的副本 (所有元素都被拷贝) |
| vector |
利用元素的default构造函数生成一个大小为n的vector |
| vector |
产生一个大小为n的vector,每个元素都是elem |
| vector |
产生一个vector,以区间[beg,end)作为初始值 |
| c.~vector |
销毁所有元素,释放内存 |
3.2 非变动操作
| 操作 |
效果 |
| c.size() |
返回当前的元素数量 |
| c.empty() |
判断大小是否为零,等同于0 == size(),效率更高 |
| c.max_size() |
返回能容纳的元素最大数量 |
| capacity() |
返回重新分配空间前所能容纳的最大元素数量 |
| reserve() |
如果容量不足,扩大 |
| c1 == c2 |
判断c1是否等于c2 |
| c1 != c2 |
判断c1是否不等于c2(等同于!(c1==c2)) |
| c1 < c2 |
判断c1是否小于c2 |
| c1 > c2 |
判断c1是否大于c2 |
| c1 <= c2 |
判断c1是否小于等于c2(等同于!(c2 |
| c1 >= c2 |
判断c1是否大于等于c2 (等同于!(c1 |
3.3 赋值操作
| 操作 |
效果 |
| c1 = c2 |
将c2的元素全部给c1 |
| c.assign(n,elem) |
复制n个elem给c |
| c.assign(beg,end) |
将区间[beg,end)赋值给c |
| c1.swap(c2) |
将c1和c2元素互换 |
| swap(c1,c2) |
将c1和c2元素互换,全局函数 |
值得注意的是,所有的赋值操作都可能调用元素的default构造函数,copy构造函数和assignment操作符或者析构函数。
3.4 元素存取
| 操作 |
效果 |
| c.at(idx) |
返回索引idx标示的元素,如果越界,抛出越界异常 |
| c[idx] |
返回索引idx标示的元素,不进行范围检查 |
| c.front() |
返回第一个元素,不检查第一个元素是否存在 |
| c.back() |
返回最后一个元素,不检查最后一个元素是否存在 |
按照c/c++的惯例,第一个元素的索引为0,所以n个元素的索引为n-1。只有at()会检查范围,其他函数不检查范围,如果越界,除了at()会抛出异常,其他函数会引发未定义行为,所以使用索引的时候,必须确定索引有效,对一个空的vector使用front()和back()都会发生未定义行为,所以调用他们,必须保证vector不为空。
对于non-const-vector,这些函数返回的都是reference,可以通过这些函数来改变元素内容。
3.5 迭代器相关函数
vector提供了一些常规函数来获取迭代器。vector的迭代器是random access iterators(随机存取迭代器),简单的来说就是数组一样的迭代器,可以直接使用下标操作。
| 操作 |
效果 |
| c.begin() |
返回一个随机存取迭代器,指向第一个元素 |
| c.end() |
返回一个随机存取迭代器,指向最后一个元素的下一个位置 |
| c.rbegin() |
返回一个逆向迭代器,指向逆向迭代的第一个元素 |
| c.rend() |
返回一个逆向迭代器,指向逆向迭代的最后一个元素的下一个位置 |
3.5.1迭代器失效条件
- 使用者在较小位置安插或移除元素。
- 由于容量变化而引起内存重新分配。
3.5.2 安插和移除元素
vector提供安插和移除操作函数,调用这些函数,必须保证参数合法:
- 迭代器必须指向一个合法位置。
- 区间的起始位置不能在结束位置之后。
- 不能从空容器中移除元素。
关于性能,下列情况的安插和移除操作可能效率高一些:
- 在容器的尾部安插或删除元素。
- 容量一开始就很大。
- 安插多个元素,调用一次比调用多次快。
安插和删除元素,会使“作用点”之后的各元素的reference、pointers、iterators失效,如果安插操作导致内存重新分配,该容器的所有reference、pointers、iterators都会失效。
| 操作 |
效果 |
| c.insert(pos,elem) |
在pos位置上插入一个elem副本,并返回新元素位置 |
| c.insert(pos,n,elem) |
在pos位置插入n个elem副本,无返回值 |
| c.insert(pos,beg,end) |
在pos位置插入[beg,end]内所有元素的副本,无返回值 |
| c.push_back(elem) |
在尾部添加一个elme副本 |
| c.pop_back() |
移除最后一个元素 |
| c.erase(pos) |
移除pos上的位置,返回下一个元素的位置 |
| c.erase(beg,end) |
移除[beg,end)内的所有元素,并返回下一元素的位置 |
| c.resize(num) |
将元素的位置改为num个(如果size变大了,多出来的元素需要default构造函数来完成构造)) |
| c.resize(num,elem) |
将元素的位置改为num个(如果size变大了,多出来的元素都是elem的副本)) |
| c.clear() |
移除所有元素,将容器清空 |
List
1、结构
list使用一个double linked list(双向链表)来管理元素。

2、 list 能力
list内部结构和vector或deque截然不同,所以与他们的区别:
list不支持随机存取,需要存取某个元素,需要遍历之前所有的元素,是很缓慢的行为。
任何位置上(不止是两端)安插和删除元素都非常快,始终都是在常数时间内完成,因为无需移动其他任何操作,实际上只进行了一些指针操作。
安插和删除并不会造成指向其他元素的各个pointers、reference、iterators失效
list是原子操作,要么成功,要么失败,不会说只执行一半。
list不支持随机存取,不提供下标操作符和at()函数。
list不提供容量,内存分配的操作函数,因为完全没必要,每个元素都有自己的内存空间,在删除之前一直有效。
list提供专门的函数用于移动函数,这些函数执行效率高,无需元素的拷贝和移动,只需要调整若干指针。
3、操作函数
3.1 构造和析构
| 操作 |
效果 |
| list |
产生一个空的list |
| list |
产生一个c2同型的list,每个元素都被复制 |
| list |
产生一个n个元素的list,每个元素都由default构造产生 |
| list |
产生一个n个元素的list,每个元素都是elem的副本 |
| list |
产生一个list以区间[beg,end)内所有元素作为初值 |
| c.~list |
销毁所有元素,释放内存 |
3.2 非变动性操作
| 操作 |
效果 |
| c.size() |
返回当前的元素数量 |
| c.empty() |
判断大小是否为零,等同于0 == size(),效率更高 |
| c.max_size() |
返回能容纳的元素最大数量 |
| c1 == c2 |
判断c1是否等于c2 |
| c1 != c2 |
判断c1是否不等于c2(等同于!(c1==c2)) |
| c1 < c2 |
判断c1是否小于c2 |
| c1 > c2 |
判断c1是否大于c2 |
| c1 <= c2 |
判断c1是否小于等于c2(等同于!(c2 |
| c1 >= c2 |
判断c1是否大于等于c2 (等同于!(c1 |
3.3 赋值
| 操作 |
效果 |
| c1 = c2 |
将c2的元素全部赋值给c1 |
| c.assign(n,elem) |
将elem的n个副本拷贝给c |
| c.assign(beg,end) |
创建一个list,区间[beg,end)内的所有元素作为初值 |
| c1.swap(c2) |
c1和c2元素互换 |
| swap(c1,c2) |
c1和c2元素互换,全局函数 |
3.3 元素存取
list不支持随机存取,只有front()和back()能直接存取元素。
| 操作 |
效果 |
| c.front() |
返回第一个元素,不检查元素是否存在 |
| c.back() |
返回最后一个元素,不检查元素是否存在 |
3.4 迭代器相关函数
list只有使用迭代器才能对元素进行存取,list不支持随机存取,所以这些迭代器是双向迭代器,凡是用到随机存取迭代器的算法都不能使用。
| 操作 |
效果 |
| c.begin() |
返回一个随机存取迭代器,指向第一个元素 |
| c.end() |
返回一个随机存取迭代器,指向最后一个元素的下一个位置 |
| c.rbegin() |
返回一个逆向迭代器,指向逆向迭代的第一个元素 |
| c.rend() |
返回一个逆向迭代器,指向逆向迭代的最后一个元素的下一个位置 |
3.5 元素的安插和移除
list提供了deque的所有功能,还增加了remove()和remove_if()应用于list。
| 操作 |
效果 |
| c.insert(pos, elem) |
在迭代器pos位置插入一个elem副本,返回新元素位置 |
| c.insert(pos,n, elem) |
在迭代器pos位置插入n个elem副本,无返回值 |
| c.insert(pos, beg,end) |
在迭代器pos位置插入区间[beg,end)内所有元素的副本,无返回值 |
| c.push_back(elem) |
在尾部追加一个elem副本 |
| c.pop_back() |
移除最后一个元素,不返回 |
| c.push_front(elem) |
在头部安插一个elem副本 |
| c.pop_front() |
移除第一个元素,不返回 |
| c.remove(val) |
移除所有值为val的元素 |
| c.remove_if(op) |
移除所有“造成op(elem)为true”的元素 |
| c.erase(pos) |
移除迭代器pos所指元素,返回下一元素位置 |
| c.erase(beg,end) |
移除区间[beg,end)内的所有元素,返回下一元素位置 |
| c.resize(num) |
将元素容量重置为num个,如果size变大,则以default构造函数构造所有元素 |
| c.resize (num, elem) |
将元素容量重置为num个,如果size变大,则所有元素为elem的副本 |
| c. clear () |
移除所有元素,将整个容器清空 |
3.6 特殊变动性操作
| 操作 |
效果 |
| c.unique() |
如果存在若干相邻而数值相等的元素,移除重复元素,只留下一个 |
| c.unique(op) |
若存在若干相邻元素,都使op()为true,移除重复元素,只留下一个 |
| c1.splice(pos,c2) |
将所有c2元素移到c1容器pos迭代器之前 |
| c1.splice(pos,c2,c2pos) |
将c2 pos位置元素移到c1元素pos位置,c1和c2可以相同 |
| c1.splice(pos,c2,c2beg,c2end) |
将c2区间[c2beg,c2end)所有元素移到c1 pos位置之前,c1和c2可以相同 |
| c.sort() |
以operator < 为准,对所有元素排序 |
| c.sort(op) |
以op()为准,对c排序 |
| c1.merge(c2) |
假设c1和c2已序,将c2元素移动到c1,并保证合并后的list仍为已序 |
| c1.merge(c2,op) |
假设c1和c2都以op()为序,将c2移动到c1仍然以op()已序 |
| c.reverse() |
将所有元素反序 |
Set和Multiset
1、结构
set和multiset会根据特定的排序原则将元素排序。两者不同之处在于,multisets允许元素重复,而set不允许重复。
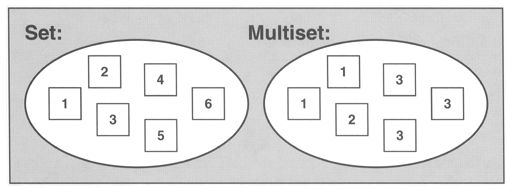
只要是assignable、copyable、comparable(根据某个排序准则)的型别T,都可以成为set或者multisets的元素。如果没有特别的排序原则,采用默认的less,已operator < 对元素进行比较,以便完成排序。
排序准则必须遵守以下原则:
- 必须是“反对称的”,对operator <而言,如果x < y为真,y
- 必须是“可传递的”,对operator <而言,如果x
- 必须是“非自反的”,对operator<而言,x
2、能力
和所有的标准关联容器类似,sets和multisets通常以平衡二叉树完成。
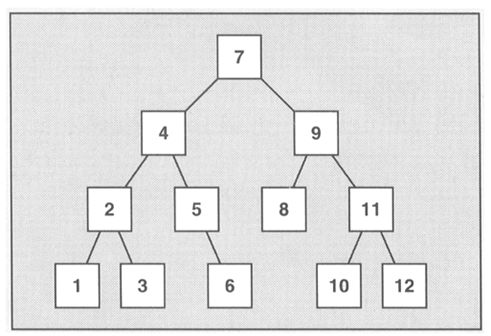
自动排序的主要优点在于使二叉树搜寻元素具有良好的性能,在其搜索函数算法具有对数复杂度。但是自动排序也造成了一个限制,不能直接改变元素值,因为这样会打乱原有的顺序,要改变元素的值,必须先删除旧元素,再插入新元素。所以sets和multisets具有以下特点:
- 不提供直接用来存取元素的任何操作元素
- 通过迭代器进行元素的存取。
3、操作函数
3.1 构造、拷贝、析构
| 操作 |
效果 |
| set c |
产生一个空的set/multiset,不含任何元素 |
| set c(op) |
以op为排序准则,产生一个空的set/multiset |
| set c1(c2) |
产生某个set/multiset的副本,所有元素都被拷贝 |
| set c(beg,end) |
以区间[beg,end)内的所有元素产生一个set/multiset |
| set c(beg,end, op) |
以op为排序准则,区间[beg,end)内的元素产生一个set/multiset |
| c.~set() |
销毁所有元素,释放内存 |
| set |
产生一个set,以(operator <)为排序准则 |
| set |
产生一个set,以op为排序准则 |
3.2 非变动性操作
| 操作 |
效果 |
| c.size() |
返回当前的元素数量 |
| c.empty () |
判断大小是否为零,等同于0 == size(),效率更高 |
| c.max_size() |
返回能容纳的元素最大数量 |
| c1 == c2 |
判断c1是否等于c2 |
| c1 != c2 |
判断c1是否不等于c2(等同于!(c1==c2)) |
| c1 < c2 |
判断c1是否小于c2 |
| c1 > c2 |
判断c1是否大于c2 |
| c1 <= c2 |
判断c1是否小于等于c2(等同于!(c2 |
| c1 >= c2 |
判断c1是否大于等于c2 (等同于!(c1 |
3.3 特殊的搜寻函数
sets和multisets在元素快速搜寻方面做了优化设计,提供了特殊的搜寻函数,所以应优先使用这些搜寻函数,可获得对数复杂度,而非STL的线性复杂度。比如在1000个元素搜寻,对数复杂度平均十次,而线性复杂度平均需要500次。
| 操作 |
效果 |
| count (elem) |
返回元素值为elem的个数 |
| find(elem) |
返回元素值为elem的第一个元素,如果没有返回end() |
| lower _bound(elem) |
返回元素值为elem的第一个可安插位置,也就是元素值 >= elem的第一个元素位置 |
| upper _bound (elem) |
返回元素值为elem的最后一个可安插位置,也就是元素值 > elem 的第一个元素位置 |
| equal_range (elem) |
返回elem可安插的第一个位置和最后一个位置,也就是元素值==elem的区间 |
3.4 赋值
| 操作 |
效果 |
| c1 = c2 |
将c2的元素全部给c1 |
| c1.swap(c2) |
将c1和c2 的元素互换 |
| swap(c1,c2) |
同上,全局函数 |
3.5 迭代器相关函数
sets和multisets的迭代器是双向迭代器,对迭代器操作而言,所有的元素都被视为常数,可以确保你不会人为改变元素值,从而打乱既定顺序,所以无法调用变动性算法,如remove()。
| 操作 |
效果 |
| c.begin() |
返回一个随机存取迭代器,指向第一个元素 |
| c.end() |
返回一个随机存取迭代器,指向最后一个元素的下一个位置 |
| c.rbegin() |
返回一个逆向迭代器,指向逆向迭代的第一个元素 |
| c.rend() |
返回一个逆向迭代器,指向逆向迭代的最后一个元素的下一个位置 |
3.6 安插和删除元素
必须保证参数有效,迭代器必须指向有效位置,序列起点不能位于终点之后,不能从空容器删除元素。
| 操作 |
效果 |
| c.insert(elem) |
插入一个elem副本,返回新元素位置,无论插入成功与否。 |
| c.insert(pos, elem) |
安插一个elem元素副本,返回新元素位置,pos为收索起点,提升插入速度。 |
| c.insert(beg,end) |
将区间[beg,end)所有的元素安插到c,无返回值。 |
| c.erase(elem) |
删除与elem相等的所有元素,返回被移除的元素个数。 |
| c.erase(pos) |
移除迭代器pos所指位置元素,无返回值。 |
| c.erase(beg,end) |
移除区间[beg,end)所有元素,无返回值。 |
| c.clear() |
移除所有元素,将容器清空 |
Map和Multimap
1、结构
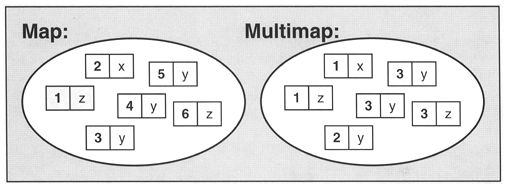
Map和multimap将key/value pair(键值/实值 队组)当作元素,进行管理。他们根据key的排序准则将元素排序。multimap允许重复元素,map不允许。
元素要求:
- key/value必须具有assigned(可赋值)和copyable(可复制的)性质。
- 对于排序而言,key必须具是comparable(可比较的)。
2、能力
典型情况下,set,multisets,map,multimap使用相同的内部结构,因此可以将set和multiset当成特殊的map和multimap,只不过set的value和key指向的是同一元素。
map和multimap会根据key对元素进行自动排序,所以根据key值搜寻某个元素具有良好的性能,但是如果根据value来搜寻效率就很低了。
同样,自动排序使得你不能直接改变元素的key,因为这样会破坏正确次序,要修改元素的key,必须先移除拥有key的元素,然后插入拥有新的key/value的元素,从迭代器的观点来看,元素的key是常数,元素的value是可以直接修改的。
3、操作函数
3.1 构造、析构、拷贝
| 操作 |
效果 |
| map c |
产生一个空的map/multimap不包含任何元素 |
| map c(op) |
以op为排序准则,产生一个空的map/multimap |
| map c1(c2) |
产生某个map/multimap的副本,所有元素都被拷贝 |
| map c(beg,end) |
以区间[beg,end)内的元素产生一个map/multimap |
| map c(beg,end,op) |
以op为排序准则,区间[beg,end)内的所有元素生成一个map/multimap |
| c.~map() |
销毁所有元素,释放内存 |
| map |
一个map/multimap,以less<> (operator <)为排序准则 |
| map |
一个map,以op为排序准则 |
3.2 非变动性操作
| 操作 |
效果 |
| c.size() |
返回当前的元素数量 |
| c.empty() |
判断大小是否为零,等同于0 == size(),效率更高 |
| c.max_size() |
返回能容纳的元素最大数量 |
| c1 == c2 |
判断c1是否等于c2 |
| c1 != c2 |
判断c1是否不等于c2(等同于!(c1==c2)) |
| c1 < c2 |
判断c1是否小于c2 |
| c1 > c2 |
判断c1是否大于c2 |
| c1 <= c2 |
判断c1是否小于等于c2(等同于!(c2 |
| c1 >= c2 |
判断c1是否大于等于c2 (等同于!(c1 |
3.3 特殊搜寻函数
| 操作 |
效果 |
| count(key) |
返回键值等于key的元素个数 |
| find(key) |
返回键值等于key的第一个元素,没找到返回end() |
| lower_bound(key) |
返回键值为key之元素的第一个可安插位置,也就是键值>=key的第一个元素位置 |
| upper_bound(key) |
返回键值为key之元素的最后一个可安插位置,也就是键值>key的第一个元素位置 |
| equal_range(key) |
返回键值为key之元素的第一个可安插位置和最后一个可安插位置,也就是键值==key的元素区间 |
3.4 赋值
| 操作 |
效果 |
| c1 = c2 |
将c2的元素全部给c1 |
| c1.swap(c2) |
将c1和c2 的元素互换 |
| swap(c1,c2) |
同上,全局函数 |
3.5 迭代器函数
map和multimap不支持元素直接存取,因此元素的存取通常是经过迭代器进行。不过例外的是,map提供下标操作,可直接存取元素。同样,他们的迭代器是双向迭代器,所有的元素的key都被视为常数,不能调用任何变动性操作,如remove(),要移除元素,只能用塔门提供的函数。
| 操作 |
效果 |
| c.begin() |
返回一个随机存取迭代器,指向第一个元素 |
| c.end() |
返回一个随机存取迭代器,指向最后一个元素的下一个位置 |
| c.rbegin() |
返回一个逆向迭代器,指向逆向迭代的第一个元素 |
| c.rend() |
返回一个逆向迭代器,指向逆向迭代的最后一个元素的下一个位置 |
3.6 元素的安插和移除
| 操作 |
效果 |
| c.insert(elem) |
插入一个elem副本,返回新元素位置,无论插入成功与否。 |
| c.insert(pos, elem) |
安插一个elem元素副本,返回新元素位置,pos为收索起点,提升插入速度。 |
| c.insert(beg,end) |
将区间[beg,end)所有的元素安插到c,无返回值。 |
| c.erase(elem) |
删除与elem相等的所有元素,返回被移除的元素个数。 |
| c.erase(pos) |
移除迭代器pos所指位置元素,无返回值。 |
| c.erase(beg,end) |
移除区间[beg,end)所有元素,无返回值。 |
| c.clear() |
移除所有元素,将容器清空 |
有三个不同的方法将value插入map:
- 运用value_type,为了避免隐式转换,可以使用value_type明白传递正确型别。value_type是容器本身提供的型别定义
std::map coll;
...
coll.insert(std::map::value_type("otto",22.3)); - 运用pair,另一个作法是直接运用pair<>。
![]()
std::map coll;
...
//use implicit conversion:
coll.insert(std::pair("otto",22.3));
//use no implicit conversion:
coll.insert(std::pair("otto",22.3)); ![]()
上述第一个insert()语句内的型别并不正确,所以会被转换成真正的型别。- 运用make_pair()
最方便的方法是直接运用make_pair()函数,这个函数根据传入的两个参数构造一个pair对象。![]()
std::map coll;
...
coll.insert(std::make_pair("otto",22.3));
下面是个简单例子,检查安插元素是否成功:
std::map coll;
...
if (coll.insert(std::make_pair("otto",22.3)).second) {
std::cout << "OK, could insert otto/22.3" << std::endl;
}
else {
std::cout << "Oops, could not insert otto/22.3 "
<< "(key otto already exists)" << std::endl;
} ![]()
如果要移除某个值为value的元素,使用erase()即可。
std::map coll;
...
//remove all elements with the passed key
coll.erase(key); 如果multimap内喊重复元素,不能使用erase()来删除这些元素的第一个,但是可以这么做:
![]()
typedef multimap StringFloatMMap;
StringFloatMMap coll;
...
//remove first element with passed key
StringFloatMMap::iterator pos;
pos = coll.find(key);
if (pos != coll.end()) {
coll.erase(pos);
} ![]()
这里使用成员函数的find()而非STL里面的find(),因为成员函数更快,然而不能使用成员函数find()来移除拥有某个value(而非某个key)的元素。
移除元素时,要当心心意外发生,当移除迭代器所指对象时,可能使迭代器失效。
![]()
typedef std::map StringFloatMap;
StringFloatMap coll;
StringFloatMap::iterator pos;
...
for (pos = coll.begin(); pos != coll.end(); ++pos) {
if (pos->second == value) {
coll. erase (pos); // RUNTIME ERROR !!!
}
} ![]()
对pos所指元素实施erase(),会使pos不再成为一个有效的迭代器,如果此后未对pos重新设值就使用pos,会出现异常。++pos就能导致一个未定义行为。下面是正确的删除方法。
![]()
typedef std::map StringFloatMap;
StringFloatMap coll;
StringFloatMap::iterator pos;
...
//remove all elements having a certain value
for (pos = c.begin(); pos != c.end(); ) {
if (pos->second == value) {
c.erase(pos++);
}
else {
++pos;
}
} ![]()
注意,pos++会指向下一个元素,但返回其原始值(指向原位置)的一个副本,因此,当erase()被调用,pos已经不指向那个即将被删除的元素了。
4、map视为关联数组
通常,关联数组不提供直接存取,必须依靠迭代器,不过map是个例外,map提供下标操作符,可以直接存取元素。不过下标操作符的索引不是元素整数位置,而是元素的key。也就是说,索引可以是任何型别,而非局限的整数型别。
| 操作 |
效果 |
| m[key] |
返回一个reference,指向键值为key的元素,如果该元素尚未存在,插入该元素。 |
和一般数组的区别不仅仅是索引型别,你不能使用一个错误的索引,如果你是用某个key为索引,容器尚未存在该元素,会自动安插该元素,新元素由default构造,所有基本型别都提供default构造函数,以零为初始值。
关联数组的行为方式有优点,也有缺点:
优点是可以透过方便的接口向map安插新元素。
![]()
std::map coll; // empty collection
/*insert "otto"/7.7 as key/value pair
*-first it inserts "otto"/float()
*-then it assigns 7.7
*/
coll["otto"] = 7.7; ![]()
其中的语句:coll["otto"] = 7.7;处理如下:
1.处理coll["otto"]:
--如果存在键值为“otto”的元素,以上式子返回该元素的reference。
--如果没有任何元素的键值为“otto”,以上式子便为map自动安插一个新元素,键值key为“otto”,value通过default构造函数完成,并返回一个reference指向新元素。
2.将7.7赋值给value:
--紧接着,将7.7赋值给刚才返回的元素。
这样,map之内就包含了一个键值(key)为“otto”的元素,其值(value)为7.7。
缺点就是你可能不小心误置新元素。例如你想打印key为“otto”的元素值:
std::cout << coll[“ottto”] << endl;
它会安插一个键值为“ottto”的元素,然后打印其值,缺省情况下是0。它并不会告诉你拼写错误,并且插入一个你可能不需要的元素。
这种插入方式比一般的map安插方式来得慢,因为在生成新元素的时候,需要使用default构造函数将新元素初始化,而这个值马上又会被真正的value覆盖。
String
1:string对象的定义和初始化以及读写
string s1; 默认构造函数,s1为空串
string s2(s1); 将s2初始化为s1的一个副本
string s3("valuee"); 将s3初始化一个字符串面值副本
string s4(n,'c'); 将s4 初始化为字符'c'的n个副本
cin>>s5; 读取有效字符到遇到空格
getline(cin,s6); 读取字符到遇到换行,空格可读入,知道‘\n’结束(练习在下一个代码中),
getline(cin,s7,'a'); 一个直到‘a’结束,其中任何字符包括'\n'都能够读入,可以试试题:UVa10361
2:string对象操作
s.empty() 判断是否为空,bool型
s.size() 或 s.length() 返回字符的个数
s[n] 返回位置为n的字符,从0开始计数
s1+s2 连接,看下面例子:
可用此方法给字符串后面添加字符如:s=s+'a';
a: string s2=s1+", "; //对,把一个string对象和一个字符面值连接起来是允许的
b: string s4="hello "+", "; //错,不能将两个字符串面值相加
c: string s5=s1+", "+"world"; //对,前面两个相加相当于一个string对象;
d: string s6="hello" + ", " + s2; //错
(注:字符串尾部追加还可用s.append("abc")函数添加)
s1=s2 替换
s1==s2 相等,返回true或false
!=,<,<=,>,>= 字符串比较,两个字符串短的与长的前面匹配,短的小于长的
3:string对象中字符的处理(头文件cctype)
isalnum(c) 如果c是字母或数字,返回 true
isalpha(c) 如果c是字母,返回true
iscntrl(c) c是控制符,返回true
isdigit(c) 如果c是数字,返回true
isgraph(c) 如果c不是空格,则可打印,,则为true
islower(c) 如果c是小写字母,则为true
isupper(c) 如果c是大写字符,则为true
isprint(c) 如果c是可打印的字符,则为true
ispunct(c) 如果c是标点符号,则为true
isspace(c) 如果c是空白字符,则为true
isxdigit(c) 如果c是十六进制数,则为true
tolower(c) 如果c是大写字符,则返回其小写字母,否则直接返回c
toupper(c) 跟tolower相反
4:string对象中一些函数
/*-------------------------插入函数----------------------------------包括迭代器操作和下标操作,下标操作更灵活*/
s.insert( it , p ); 把字符串p插入到it的位置
s.insert(p,n,t); 迭代器p元素之前插入n个t的副本
s.insert(p,b,e); 迭代器p元素之前插入迭代器b到e之间的所有元素
s.insert(p,s2,poe2,len); 在下标p之前插入s2下标从poe2开始长度为len的元素
s.insert(pos,cp,len); 下标pos之前插入cp数组的前len个元素。
/*-----------------------替换函数-------------------------------*/
s.assign(b,e); 用迭代器b到e范围内的元素替换s
s.assign(n,t); 用n个t的副本替换s
a.assign(s1,pos2,len);从s1的下标pos2开始连续替换len个。
s.replace ( 3 , 3 , " good " ) ; 从第三个起连续三个替换为good
s.substr(i,j) 截取s串中从i到j的子串 //string::npos 判断字符串是否结束
/*-----------------------删除函数-----------------------------*/
s.erase( 3 )||s.erase ( 0 , 4 ) ; 删除第四个元素或第一到第五个元素
/*----------------------其他函数-----------------------------*/
s.find ( " cat " ) ; 超找第一个出现的字符串”cat“,返回其下标值,查不到返回 4294967295,也可查找字符;
s.append(args); 将args接到s的后面
s.compare ( " good " ) ; s与”good“比较相等返回0,比"good"大返回1,小则返回-1;
reverse ( s.begin(), s.end () ); 反向排序函数,即字符串反转函数
优先队列
HDU6386 Age of Moyu BFS+优先队列
struct cmp
{
bool operator()(const nod &a,const nod &b)const
{
return a.v>b.v;
}
};
priority_queue,cmp>q; string.h 中常用函数
strcpy
功 能: 拷贝一个字符串到另一个
用 法: char *strcpy(char *destin, char *source);
strcat
功 能: 字符串拼接函数
用 法: char *strcat(char *destin, char *source);
strchr
功 能: 在一个串中查找给定字符的第一个匹配之处
用 法: char *strchr(char *str, char c);
strcmp
功 能: 串比较
用 法: int strcmp(char *str1, char *str2); // 看Asic码,str1>str2,返回值 > 0;两串相等,返回0
strcmpi
功 能: 将一个串中的一部分与另一个串比较, 不管大小写
用 法: int strncmpi(char *str1, char *str2, unsigned maxlen);
strnset
功 能: 将一个字符串前n个字符都设为指定字符
用 法: char *strnset(char *str, char ch, unsigned n);
strstr
功 能: 在串中查找指定字符串的第一次出现
用 法: char *strstr(char *str1, char *str2);
strupr
功 能: 将串中的小写字母转换为大写字母
用 法: char *strupr(char *str);
memset
功 能: 将s所指向的某一块内存中的前n个 字节的内容全部设置为ch指定的ASCII值(作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法)
用法:void *memset(void *s, int ch, size_t n);
memcpy
功 能: memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中。
用法:void *memcpy(void *dest, const void *src, size_t n);